Visible to Intel only — GUID: GUID-8EB00871-E88D-40D1-A4CD-AAAFFF2B35C6
What's New
Introduction to the Intel® oneAPI Math Kernel Library (oneMKL) BLAS and LAPACK with DPC++
Overview of Intel® oneMKL BLAS Routines for Data Parallel C++
Overview of Intel® oneAPI Math Kernel Library (oneMKL) Sparse BLAS for DPC++
Overview of Intel® oneMKL LAPACK Routines for Data Parallel C++
Data Types
Matrix Storage
Error Handling
BLAS Routines
Sparse BLAS Routines
LAPACK Routines
Vector Mathematical Functions
Random Number Generators
Summary Statistics
Fourier Transform Functions
Data Fitting
Bibliography
Appendix A: oneMKL Functionality
Notices and Disclaimers
Sparse BLAS Matrix Handle Contract between User and Library
Sparse BLAS Supported Data and Integer Types
Sparse Storage Formats
oneapi::mkl::sparse::init_matrix_handle
oneapi::mkl::sparse::release_matrix_handle
oneapi::mkl::sparse::set_csr_data
oneapi::mkl::sparse::set_matrix_property
oneapi::mkl::sparse::optimize_gemv
oneapi::mkl::sparse::optimize_trmv
oneapi::mkl::sparse::optimize_trsv
oneapi::mkl::sparse::gemv
oneapi::mkl::sparse::gemvdot
oneapi::mkl::sparse::symv
oneapi::mkl::sparse::trmv
oneapi::mkl::sparse::trsv
oneapi::mkl::sparse::gemm
oneapi::mkl::sparse::init_matmat_descr
oneapi::mkl::sparse::set_matmat_data
oneapi::mkl::sparse::get_matmat_data
oneapi::mkl::sparse::release_matmat_descr
oneapi::mkl::sparse::matmat
oneapi::mkl::sparse::omatcopy
oneapi::mkl::sparse::sort_matrix
oneapi::mkl::sparse::update_diagonal_values
gebrd
gebrd (USM Version)
gebrd_scratchpad_size
gels_batch (Buffer Strided Version)
gels_batch (USM Strided Version)
gels_batch_scratchpad_size (Strided Version)
geqrf
geqrf (USM Version)
geqrf_batch (Buffer Strided Version)
geqrf_batch (Group Version)
geqrf_batch (USM Strided Version)
geqrf_batch_scratchpad_size (Group Version)
geqrf_batch_scratchpad_size (Strided Version)
geqrf_scratchpad_size
gerqf
gerqf (USM Version)
gerqf_scratchpad_size
gesv (USM Version)
gesv_scratchpad_size
gesvd
gesvd (USM Version)
gesvd_scratchpad_size
getrf
getrf (USM Version)
getrf_batch (Buffer Strided Version)
getrf_batch (Group Version)
getrf_batch (USM Strided Version)
getrf_batch_scratchpad_size (Group Version)
getrf_batch_scratchpad_size (Strided Version)
getrf_scratchpad_size
getrfnp_batch (Buffer Strided Version)
getrfnp_batch (Group Version)
getrfnp_batch (USM Strided Version)
getrfnp_batch_scratchpad_size (Group Version)
getrfnp_batch_scratchpad_size (Strided Version)
getri
getri (USM Version)
getri_batch (Buffer Strided Version)
getri_batch (Group Version)
getri_batch (USM Strided Version)
getri_batch_scratchpad_size (Group Version)
getri_batch_scratchpad_size (Strided Version)
getri_batch (Out-of-place, Buffer Strided Version)
getri_batch (Out-of-place, USM Strided Version)
getri_batch_scratchpad_size (Strided Version)
getri_scratchpad_size
getrs
getrs (USM Version)
getrs_batch (Buffer Strided Version)
getrs_batch (Group Version)
getrs_batch (USM Strided Version)
getrs_batch_scratchpad_size (Group Version)
getrs_batch_scratchpad_size (Strided Version)
getrs_scratchpad_size
getrsnp_batch (Buffer Strided Version)
getrsnp_batch (USM Strided Version)
getrsnp_batch_scratchpad_size (Strided Version)
heevd
heevd (USM Version)
heevd_scratchpad_size
hegvd
hegvd (USM Version)
hegvd_scratchpad_size
hetrd
hetrd (USM Version)
hetrd_scratchpad_size
hetrf
hetrf (USM Version)
hetrf_scratchpad_size
orgbr
orgbr (USM Version)
orgbr_scratchpad_size
orgqr
orgqr (USM Version)
orgqr_batch (Buffer Strided Version)
orgqr_batch (Group Version)
orgqr_batch (USM Strided Version)
orgqr_batch_scratchpad_size (Group Version)
orgqr_batch_scratchpad_size (Strided Version)
orgqr_scratchpad_size
orgtr
orgtr (USM Version)
orgtr_scratchpad_size
ormqr
ormqr (USM Version)
ormqr_scratchpad_size
ormrq
ormrq (USM Version)
ormrq_scratchpad_size
ormtr
ormtr (USM Version)
ormtr_scratchpad_size
potrf
potrf (USM Version)
potrf_batch (Buffer Strided Version)
potrf_batch (Group Version)
potrf_batch (USM Strided Version)
potrf_batch_scratchpad_size (Group Version)
potrf_batch_scratchpad_size (Strided Version)
potrf_scratchpad_size
potri
potri (USM Version)
potri_scratchpad_size
potrs
potrs (USM Version)
potrs_batch (Buffer Strided Version)
potrs_batch (Group Version)
potrs_batch (USM Strided Version)
potrs_batch_scratchpad_size (Group Version)
potrs_batch_scratchpad_size (Strided Version)
potrs_scratchpad_size
syevd
syevd (USM Version)
syevd_scratchpad_size
sygvd
sygvd (USM Version)
sygvd_scratchpad_size
sytrd
sytrd (USM Version)
sytrd_scratchpad_size
sytrf
sytrf (USM Version)
sytrf_scratchpad_size
trtri (USM Version)
trtri_scratchpad_size
trtrs
trtrs (USM Version)
trtrs_scratchpad_size
ungbr
ungbr (USM Version)
ungbr_scratchpad_size
ungqr
ungqr (USM Version)
ungqr_batch (Buffer Strided Version)
ungqr_batch (Group Version)
ungqr_batch (USM Strided Version)
ungqr_batch_scratchpad_size (Group Version)
ungqr_batch_scratchpad_size (Strided Version)
ungqr_scratchpad_size
ungtr
ungtr (USM Version)
ungtr_scratchpad_size
unmqr
unmqr (USM Version)
unmqr_scratchpad_size
unmrq
unmrq (USM Version)
unmrq_scratchpad_size
unmtr
unmtr (USM Version)
unmtr_scratchpad_size
oneapi::mkl::rng::mrg32k3a
oneapi::mkl::rng::philox4x32x10
oneapi::mkl::rng::mcg31m1
oneapi::mkl::rng::mcg59
oneapi::mkl::rng::r250
oneapi::mkl::rng::wichmann_hill
oneapi::mkl::rng::mt19937
oneapi::mkl::rng::sfmt19937
oneapi::mkl::rng::mt2203
oneapi::mkl::rng::ars5
oneapi::mkl::rng::sobol
oneapi::mkl::rng::niederreiter
oneapi::mkl::rng::nondeterministic
Distributions Template Parameter Method
oneapi::mkl::rng::uniform (Continuous)
oneapi::mkl::rng::gaussian
oneapi::mkl::rng::exponential
oneapi::mkl::rng::laplace
oneapi::mkl::rng::weibull
oneapi::mkl::rng::cauchy
oneapi::mkl::rng::rayleigh
oneapi::mkl::rng::lognormal
oneapi::mkl::rng::gumbel
oneapi::mkl::rng::gamma
oneapi::mkl::rng::beta
oneapi::mkl::rng::chi_square
oneapi::mkl::rng::gaussian_mv
oneapi::mkl::rng::uniform (Discrete)
oneapi::mkl::rng::uniform_bits
oneapi::mkl::rng::bits
oneapi::mkl::rng::bernoulli
oneapi::mkl::rng::geometric
oneapi::mkl::rng::binomial
oneapi::mkl::rng::hypergeometric
oneapi::mkl::rng::poisson
oneapi::mkl::rng::poisson_v
oneapi::mkl::rng::negative_binomial
oneapi::mkl::rng::multinomial
oneapi::mkl::rng::device::uniform (Continuous)
oneapi::mkl::rng::device::gaussian
oneapi::mkl::rng::device::lognormal
oneapi::mkl::rng::device::exponential
oneapi::mkl::rng::device::uniform (Discrete)
oneapi::mkl::rng::device::bits
oneapi::mkl::rng::device::uniform_bits
oneapi::mkl::rng::device::poisson
oneapi::mkl::rng::device::bernoulli
oneapi::mkl::stats::raw_sum
oneapi::mkl::stats::central_sum
oneapi::mkl::stats::central_sum with User-provided Mean
oneapi::mkl::stats::raw_moment
oneapi::mkl::stats::central_moment
oneapi::mkl::stats::central_moment with User-provided Mean
oneapi::mkl::stats::mean
oneapi::mkl::stats::variation
oneapi::mkl::stats::variation with User-provided Mean
oneapi::mkl::stats::skewness
oneapi::mkl::stats::skewness with User-provided Mean
oneapi::mkl::stats::kurtosis
oneapi::mkl::stats::kurtosis with User-provided Mean
oneapi::mkl::stats::min
oneapi::mkl::stats::max
oneapi::mkl::stats::min_max
descriptor<precision, domain>
descriptor<precision, domain>::set_value
descriptor<precision, domain>::get_value
descriptor<precision, domain>::commit
compute_forward<typename descriptor_type, typename data_type>
compute_backward<typename descriptor_type, typename data_type>
User-Allocated Workspaces
Visible to Intel only — GUID: GUID-8EB00871-E88D-40D1-A4CD-AAAFFF2B35C6
omatcopy_batch
Computes a group of out-of-place scaled matrix transpose or copy operations using general matrices.
Description
The omatcopy_batch routines perform a series of out-of-place scaled matrix copies or transpositions. They are similar to the omatcopy routines, but the omatcopy_batch routines perform matrix operations with a group of matrices.
omatcopy_batch supports the following precisions:
T |
|---|
float |
double |
std::complex<float> |
std::complex<double> |
omatcopy_batch (Buffer Version)
Buffer version of omatcopy_batch supports only strided API.
Strided API
The operation for the strided API is defined as:
for i = 0 … batch_size – 1
A and B are matrices at offset i * stride_a in a and i * stride_b in b
B = alpha * op(A)
end for
where:
op(X) is one of op(X) = X, op(X) = X', or op(X) = conjg(X')
alpha is a scalar
A and B are matrices
For the strided API, the single input buffer contains all the input matrices, and the single output buffer contains all the output matrices. The locations of the individual matrices within the buffer are given by stride lengths, while the number of matrices is given by the batch_size parameter.
Syntax
namespace oneapi::mkl::blas::column_major {
void omatcopy_batch(sycl::queue &queue,
transpose trans,
std::int64_t m,
std::int64_t n,
T alpha,
sycl::buffer<T, 1> &a,
std::int64_t lda,
std::int64_t stride_a,
sycl::buffer<T, 1> &b,
std::int64_t ldb,
std::int64_t stride_b,
std::int64_t batch_size);
}
namespace oneapi::mkl::blas::row_major {
void omatcopy_batch(sycl::queue &queue,
transpose trans,
std::int64_t m,
std::int64_t n,
T alpha,
sycl::buffer<T, 1> &a,
std::int64_t lda,
std::int64_t stride_a,
sycl::buffer<T, 1> &b,
std::int64_t ldb,
std::int64_t stride_b,
std::int64_t batch_size);
}
Input Parameters
- queue
-
The queue where the routine should be executed.
- trans
-
Specifies op(A), the transposition operation applied to the matrices A.
- m
-
Number of rows for each matrix A. Must be at least zero.
- n
-
Number of columns for each matrix A. Must be at least zero.
- alpha
-
Scaling factor for the matrix transposition or copy.
- a
-
Buffer holding the input matrices A. Must have size at least stride_a*batch_size.
- lda
-
Leading dimension of the A matrices. If matrices are stored using column major layout, lda must be at least m. If matrices are stored using row major layout, lda must be at least n. Must be positive.
- stride_a
-
Stride between the different A matrices. If matrices are stored using column major layout, stride_a must be at least lda*n. If matrices are stored using row major layout, stride_a must be at least lda*m.
- ldb
-
Leading dimension of the matrices B. Must be positive and satisfy:
trans = transpose::nontrans
trans = transpose::trans or trans = transpose::conjtrans
Column major
Must be at least m
Must be at least n
Row major
Must be at least n
Must be at least m
- stride_b
-
Stride between the different B matrices in the buffer b. Must be positive and satisfy:
trans = transpose::nontrans
trans = transpose::trans or trans = transpose::conjtrans
Column major
Must be at least ldb*n
Must be at least ldb*m
Row major
Must be at least ldb*m
Must be at least ldb*n
- batch_size
-
Specifies the number of matrices to transpose or copy. Must be at least zero.
Output Parameters
- b
-
Output buffer, overwritten by batch_size matrix transpose or copy operations of the form alpha*op(A). Must have size at least stride_b*batch_size.
omatcopy_batch (USM Version)
USM version of omatcopy_batch supports group API and strided API.
Group API
The operation for the group API is defined as:
idx = 0
for i = 0 … group_count – 1
m, n, alpha, lda, ldb and group_size at position i in their respective arrays
for j = 0 … group_size – 1
A and B are matrices at position idx in their respective arrays
B = alpha * op(A)
idx := idx + 1
end for
end for
where:
op(X) is one of op(X) = X, op(X) = X', or op(X) = conjg(X')
alpha is a scalar
A and B are matrices
For the group API, the matrices are given by arrays of pointers. A and B represent matrices stored at addresses pointed to by a and b respectively. The total number of entries in a and b are given by:
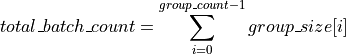
Syntax
namespace oneapi::mkl::blas::column_major {
sycl::event omatcopy_batch(sycl::queue &queue,
const transpose *trans,
const std::int64_t *m,
const std::int64_t *n,
const T *alpha,
const T **a,
const std::int64_t *lda,
T **b,
const std::int64_t *ldb,
std::int64_t group_count,
const std::int64_t *groupsize,
const std::vector<sycl::event> &dependencies = {});
}
namespace oneapi::mkl::blas::row_major {
sycl::event omatcopy_batch(sycl::queue &queue,
const transpose *trans,
const std::int64_t *m,
const std::int64_t *n,
const T *alpha,
const T **a,
const std::int64_t *lda,
T **b,
const std::int64_t *ldb,
std::int64_t group_count,
const std::int64_t *groupsize,
const std::vector<sycl::event> &dependencies = {});
}
Input Parameters
- queue
-
The queue where the routine should be executed.
- trans
-
Array of size group_count. Each element i in the array specifies op(A) the transposition operation applied to the matrices A.
- m
-
Array of group_count integers. m[i] specifies the number of rows of A[i]. Each entry must be at least zero.
- n
-
Array of group_count integers. n[i] specifies the number of columns of A[i]. Each entry must be at least zero.
- alpha
-
Array of size group_count containing scaling factors for the operation.
- a
-
Array of size total_batch_count of pointers to A matrices. If matrices are stored in column major layout, the array allocated for each A matrix of the group i must be of size at least lda[i] * n[i]. If matrices are stored in row major layout, the array allocated for each A matrix of the group i must be of size at least lda[i]*m[i].
- lda
-
Array of group_count integers. lda[i] specifies the leading dimension of the A[i] matrix. If matrices are stored using column major layout, lda[i] must be at least m[i]. If matrices are stored using row major layout, lda[i] must be at least n[i]. Each must be positive.
- ldb
-
Array of group_count integers. ldb[i] specifies the leading dimension of the B[i] matrix. Each ldb[i] must be positive and satisfy:
trans[i] = transpose::nontrans
trans[i] = transpose::trans or trans[i] = transpose::conjtrans
Column major
Must be at least m[i]
Must be at least n[i]
Row major
Must be at least n[i]
Must be at least m[i]
- group_count
-
Number of groups. Must be at least 0.
- group_size
-
Array of size group_count`. The element ``group_size[i] is the number of matrices in the group i. Each element in group_size must be at least 0.
- dependencies
-
List of events to wait for before starting computation, if any. If omitted, defaults to no dependencies.
Output Parameters
- b
-
Output array of pointers to B matrices, overwritten by total_batch_count matrix transpose or copy operations of the form alpha*op(A). If matrices are stored using column major layout, the array allocated for each B matrix of the group i must be of size at least ldb[i] * n[i] if B is not transposed or ldb[i]*m[i] if B is transposed. If matrices are stored using row major layout, the array allocated for each B matrix of the group i must be of size at least ldb[i] * m[i] if B is not transposed or ldb[i]*n[i] if B is transposed.
Return Values
Output event to wait on to ensure computation is complete.
Strided API
The operation for the strided API is defined as:
for i = 0 … batch_size – 1
A and B are matrices at offset i * stride_a in a and i * stride_b in b
B = alpha * op(A)
end for
where:
op(X) is one of op(X) = X, op(X) = X', or op(X) = conjg(X')
alpha is a scalar
A and B are matrices
For the strided API, the single input array contains all the input matrices, and the single output array contains all the output matrices. The locations of the individual matrices within the array are given by stride lengths, while the number of matrices is given by the batch_size parameter.
Syntax
namespace oneapi::mkl::blas::column_major {
sycl::event omatcopy_batch(sycl::queue &queue,
transpose trans,
std::int64_t m,
std::int64_t n,
T alpha,
const T *a,
std::int64_t lda,
std::int64_t stride_a,
T *b,
std::int64_t ldb,
std::int64_t stride_b,
std::int64_t batch_size,
const std::vector<sycl::event> &dependencies = {});
}
namespace oneapi::mkl::blas::row_major {
sycl::event omatcopy_batch(sycl::queue &queue,
transpose trans,
std::int64_t m,
std::int64_t n,
T alpha,
const T *a,
std::int64_t lda,
std::int64_t stride_a,
T *b,
std::int64_t ldb,
std::int64_t stride_b,
std::int64_t batch_size,
const std::vector<sycl::event> &dependencies = {});
}
Input Parameters
- trans
-
Specifies op(A), the transposition operation applied to the matrices A.
- m
-
Number of rows for each matrix A. Must be at least zero.
- n
-
Number of columns for each matrix A. Must be at least zero.
- alpha
-
Scaling factor for the matrix transposition or copy.
- a
-
Array holding the input matrices A. Must have size at least stride_a*batch_size.
- lda
-
Leading dimension of the A matrices. If matrices are stored using column major layout, lda must be at least m. If matrices are stored using row major layout, lda must be at least n. Must be positive.
- stride_a
-
Stride between the different A matrices. If matrices are stored using column major layout, stride_a must be at least lda*n. If matrices are stored using row major layout, stride_a must be at least lda*m.
- ldb
-
Leading dimension of the matrices B. Must be positive and satisfy:
trans = transpose::nontrans
trans = transpose::trans or trans = transpose::conjtrans
Column major
Must be at least m
Must be at least n
Row major
Must be at least n
Must be at least m
- stride_b
-
Stride between the different B matrices in the array b. Must be positive and satisfy:
trans = transpose::nontrans
trans = transpose::trans or trans = transpose::conjtrans
Column major
Must be at least ldb*n
Must be at least ldb*m
Row major
Must be at least ldb*m
Must be at least ldb*n
- batch_size
-
Specifies the number of matrices to transpose or copy. Must be at least zero.
- dependencies
-
List of events to wait for before starting computation, if any. If omitted, defaults to no dependencies.
Output Parameters
- b
-
Output array, overwritten by batch_size matrix transpose or copy operations of the form alpha*op(A). Must have size at least stride_b*batch_size.
Return Values
Output event to wait on to ensure computation is complete.