Visible to Intel only — GUID: GUID-C80DCC86-1E36-4264-A65F-A41CDC8D0D94
Abs
AbsBackward
Add
AvgPool
AvgPoolBackward
BatchNormForwardTraining
BatchNormInference
BatchNormTrainingBackward
BiasAdd
BiasAddBackward
Clamp
ClampBackward
Concat
Convolution
ConvolutionBackwardData
ConvolutionBackwardWeights
ConvTranspose
ConvTransposeBackwardData
ConvTransposeBackwardWeights
Dequantize
Divide
DynamicDequantize
DynamicQuantize
Elu
EluBackward
End
Exp
GroupNorm
GELU
GELUBackward
HardSigmoid
HardSigmoidBackward
HardSwish
HardSwishBackward
Interpolate
InterpolateBackward
LayerNorm
LayerNormBackward
LeakyReLU
Log
LogSoftmax
LogSoftmaxBackward
MatMul
Maximum
MaxPool
MaxPoolBackward
Minimum
Mish
MishBackward
Multiply
Pow
PReLU
PReLUBackward
Quantize
Reciprocal
ReduceL1
ReduceL2
ReduceMax
ReduceMean
ReduceMin
ReduceProd
ReduceSum
ReLU
ReLUBackward
Reorder
Round
Select
Sigmoid
SigmoidBackward
SoftMax
SoftMaxBackward
SoftPlus
SoftPlusBackward
Sqrt
SqrtBackward
Square
SquaredDifference
StaticReshape
StaticTranspose
Subtract
Tanh
TanhBackward
TypeCast
Wildcard
enum dnnl_alg_kind_t
enum dnnl_normalization_flags_t
enum dnnl_primitive_kind_t
enum dnnl_prop_kind_t
enum dnnl_query_t
enum dnnl::normalization_flags
enum dnnl::query
struct dnnl_exec_arg_t
struct dnnl_primitive
struct dnnl_primitive_desc
struct dnnl::primitive
struct dnnl::primitive_desc
struct dnnl::primitive_desc_base
enum dnnl_rnn_direction_t
enum dnnl_rnn_flags_t
enum dnnl::rnn_direction
enum dnnl::rnn_flags
struct dnnl::augru_backward
struct dnnl::augru_forward
struct dnnl::gru_backward
struct dnnl::gru_forward
struct dnnl::lbr_augru_backward
struct dnnl::lbr_augru_forward
struct dnnl::lbr_gru_backward
struct dnnl::lbr_gru_forward
struct dnnl::lstm_backward
struct dnnl::lstm_forward
struct dnnl::rnn_primitive_desc_base
struct dnnl::vanilla_rnn_backward
struct dnnl::vanilla_rnn_forward
Visible to Intel only — GUID: GUID-C80DCC86-1E36-4264-A65F-A41CDC8D0D94
Nuances of int8 Computations
This document uses int8 to denote 8-bit integer no matter whether it is signed or unsigned. To emphasize the signedness of the data type u8 (uint8_t) or s8 (int8_t) are used. In particular, if a primitive has two inputs the types would be written using “/”. For instance:
int8 GEMM denotes any integer GEMM with 8-bit integer inputs, while
u8/s8 GEMM denotes dnnl_gemm_u8s8s32() only.
The operation primitives that work with the int8 data type (dnnl::memory::data_type::s8 and dnnl::memory::data_type::u8) typically use s32 (int32_t) as an intermediate data type (dnnl::memory::data_type::s32) to avoid integer overflows.
For instance, the int8 average pooling primitive accumulates the int8 input values in a window to an s32 accumulator, then divides the result by the window size, and then stores the result back to the int8 destination:
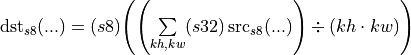
NOTE:
The max pooling primitive can directly work with int8 data types.
Using an s32 accumulator is especially important for matrix-multiply such as operation primitives that have chains of multiplication and accumulation of int8 values. These primitives are:
Int8 GEMMs: dnnl_gemm_s8s8s32() and dnnl_gemm_u8s8s32()
RNN with LSTM or GRU cell functions
Ideally, the semantics of these operations should be as follows:
Convert all inputs to s32 data type.
Perform the operation using s32 data type.
(Optionally) Post process the data. This typically happens with additional data conversion to the f32 data type.
(Optionally) Down-convert the result to the destination data type.
Depending on the hardware, the first step might vary slightly.
The data type of computations within a primitive is defined based on the type of the input tensors.
This document focuses on the first two steps (since the last two steps are independent from the hardware used), and describes the behaviors on different systems and the reasons behind them.
CPU
1. Inputs of mixed type: u8 and s8
Instruction Set Architecture (ISA) has special instructions that enable multiplying and adding the vectors of u8 and s8 very efficiently. oneDNN enables int8 support using these particular instructions.
Unfortunately, these instructions do not have the counterparts that work with vectors of the same type (either s8/s8 or u8/u8). The details for the s8/s8 case are covered in the 2. Inputs of the same type: s8 section below.
1.1. Processors with the Intel AVX2 or Intel AVX-512 Support
System examples: Intel Xeon processor E7 v3 Family (formerly Haswell), Intel Xeon Scalable processor x1xx series (formerly Skylake).
oneDNN implements matrix multiplication such as operations with u8 and s8 operands on the Intel AVX2 and Intel AVX512 Instruction Set by using a sequence of VPMADDUBSW, VPMADDWD, VPADDD instructions [1] :
VPMADDUBSW multiplies two pairs of u8/s8 values and accumulates the result into s16 (int16_t) with potential saturation.
VPMADDWD sums the pairs of s16 values obtained above into s32. Computed sum is exact.
VPADDD accumulates obtained s32 value to the accumulator.
The pseudo-code for the sequence is shown below:
// Want to compute:
// c_s32 += sum{i=0..3}(a_u8[i] * b_s8[i])
int32_t u8s8s32_compute_avx512(
uint8_t a_u8[4], int8_t b_s8[4], int32_t c_s32) {
// Compute using VPMADDUBSW, VPMADDWD, VPADDD:
int16_t ab_s16[4];
for (int i = 0; i < 4; ++i)
ab_s16[i] = (int16_t)a_u8[i] * (int16_t)b_s8[i]; // Exact computations
int16_t VPMADDUBSW_res[2];
VPMADDUBSW_res[0] = saturate_to_s16(ab_s16[0] + ab_s16[1]); // CAUTION: POTENTIAL OVERFLOW / SATURATION
VPMADDUBSW_res[1] = saturate_to_s16(ab_s16[2] + ab_s16[3]); // CAUTION: POTENTIAL OVERFLOW / SATURATION
c_s32 +=
(int32_t)VPMADDUBSW_res[0] +
(int32_t)VPMADDUBSW_res[1];
return c_s32;
}Note the potential saturation happening at the first step (or the snippet that is marked with CAUTION in the pseudo-code). Consider the following example:
uint8_t a_u8[4] = {255, 255, 0, 0};
int8_t b_s8[4] = {127, 127, 0, 0};
int32_t c_s32 = 0;
c_s32 = u8s8s32_compute(a_u8, b_s8, c_s32);
// c_s32 = 32767
// = 0
// + max(INT16_MIN, min(INT16_MAX, 255 * 127 + 255 * 127))
// + max(INT16_MIN, min(INT16_MAX, 0 * 0 + 0 * 0));
// While one might expect 64770 = 255 * 127 + 255 * 127 + 0 * 0 + 0 * 0;This is the major pitfall of using this sequence of instructions. As far as the precise result is concerned, one of the possible instruction sequences would be VPMOVSXBW/VPMOVZXBW, VPMADDWD, VPADDD[1], where the first ones casts the s8/u8 values to s16. Unfortunately, using them would lead to 2x lower performance.
When one input is of type u8 and the other one is of type s8, oneDNN assumes that it is the user’s responsibility to choose the quantization parameters so that no overflow/saturation occurs. For instance, a user can use u7 [0, 127] instead of u8 for the unsigned input, or s7 [-64, 63] instead of the s8 one. It is worth mentioning that this is required only when the Intel AVX2 or Intel AVX512 Instruction Set is used.
The RNN primitive behaves slightly differently than the convolution and inner product primitives, or u8/s8 GEMM. Even though its hidden state is represented by the u8 data type, the non-symmetric quantization is assumed. Namely, the formula is:
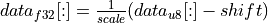 .
.
But similarly to the other primitives, the RNN primitive does not handle potential overflows automatically. It is up to the user to specify the appropriate quantization parameters (see dnnl::primitive_attr::set_rnn_data_qparams() and dnnl::primitive_attr::set_rnn_weights_qparams()). The recommended ones are:
Data (hidden states) use scale = 127, and shift = 128.
Weights use scale = 63 / W_max, where W_max is
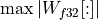 .
.
1.2. Processors with the Intel DL Boost Support
System examples: Intel Xeon Scalable processor x2xx series (formerly Cascade Lake).
Intel DL Boost brings the VPDPBUSD instruction [2], which enables computing the sum of four products of s8 and u8 values. This instruction performs same computations as the sequence of VPMADDUBSW, VPMADDWD, VPADDD instructions shown above, but with the major difference that the intermediate overflow and saturation cannot occur.
In other words, VPDPBUSD enables you to exactly compute:
// Want to compute:
// c_s32 += sum{i=0..3}(a_u8[i] * b_s8[i])
int32_t u8s8s32_compute_avx512_dl_boost(
uint8_t a_u8[4], int8_t b_s8[4], int32_t c_s32) {
// Compute using VPDPBUSD:
c_s32 +=
(int32_t)a_u8[0] * (int32_t)b_s8[0] +
(int32_t)a_u8[1] * (int32_t)b_s8[1] +
(int32_t)a_u8[2] * (int32_t)b_s8[2] +
(int32_t)a_u8[3] * (int32_t)b_s8[3];
return c_s32;
}Since the instruction always computes the result accurately, no special tricks are required, and operations follow the semantics shown above.
2. Inputs of the same type: s8
As mentioned above, with the current instruction set it is impossible to multiply and add two vectors of the s8 data type as efficiently as it is for the mixed case. However, in real-world applications the inputs are typically signed.
To overcome this issue, oneDNN employs a trick: at run-time, it adds 128 to one of the s8 input to make it of type u8 instead. Once the result is computed, oneDNN subtracts the extra value it added by replacing the s8 with u8. This subtracted value sometimes referred as a compensation.
Conceptually the formula is:
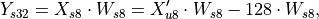
where:
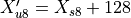 , and
, and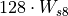 is a compensation.
is a compensation.
NOTE:
Since s8/s8 implementations are based on u8/s8 ones, the performance of the former might be slightly lower than the latter. The difference might vary depending on the problem sizes, hardware, and environment, but is expected to be in a range from 0% to 15% in most cases.
Since s8/s8 implementations are based on u8/s8 ones, they have the same potential issue with overflow/saturation when the Intel AVX2 or Intel AVX512 Instruction Set is used. The difference between the expected and actual results might be much greater though in this case. Consider the following example:
int8_t a_s8[4] = {127, 127, 0, 0};
int8_t b_s8[4] = {127, 127, 0, 0};
int32_t c_s32 = 0;
// s8s8 the uses u8s8
auto s8s8s32_compute = [](int8_t a_s8[4], int8_t b_s8[4], int32_t c_s32) {
uint8_t a_u8[4] = { 128 + a_s8[0], ...};
c_s32 = u8s8s32_compute(a_u8, b_s8, c_s32);
// apply the compensation
c_s32 +=
- 128 * b_s8[0]
- 128 * b_s8[1]
- 128 * b_s8[2]
- 128 * b_s8[3];
return c_s32;
};
c_s32 = s8s8s32_compute(a_s8, b_s8, c_s32);
// c_s32 = 255
// = 32767 - 128 * (127 + 127 + 0 + 0);
// While one might expect 32258 !!!Note that processors with no support of the Intel AVX2 and Intel AVX512 Instruction Set or with support of the Intel DL Boost Instruction Set are not affected by these issues due to the reasons described in 1. Inputs of mixed type: u8 and s8 section above.
Different primitives solve the potential overflow differently. The overview of the implementations are given below:
Convolution primitive. The source is treated as X_s8, which would be shifted during the execution. The compensation is precomputed by a reorder during quantization of the weights, and embedded into them. Finally, when the Intel AVX2 or Intel AVX512 Instruction Set is used the reorder additionally scales the weights by 0.5 to overcome the potential overflow issue. During the convolution execution, the result would be re-scaled back. This rescaling introduces an error that might insignificantly affect the inference accuracy (compared to a platform with the Intel DL Boost Instruction Set).
s8/s8 GEMM (dnnl_gemm_s8s8s32()) does nothing to handle the overflow issue. It is up to the user to prepare the data so that the overflow/saturation does not occur. For instance, the user can specify s7 [-64, 63] instead of s8 for the second input.
WARNING:It would not be enough to use s7 [-64, 63] for the first input. The only possible way to avoid overflow by shrinking the range of the first input would be to use the range [-128, -1], which is most likely meaningless.The inner product primitive directly calls s8/s8 GEMM, so it inherits the behavior of the latter. The user should consider using the appropriate scaling factors to avoid potential issues.
The RNN primitive does not support s8/s8 inputs.
GPU
See Data Types for details of int8 data type support on GPU.
References
[1] Intel(R) 64 and IA-32 Architectures Software Developer’s Manual Combined Volumes 2A, 2B, 2C, and 2D: Instruction Set Reference, A-Z. 325383-070US May 2019.
[2] Intel(R) Architecture Instruction Set Extensions and Future Features Programming Reference. 319433-037 May 2019. Chapter 2.1. VPDPBUSD — Multiply and Add Unsigned and Signed Bytes.
[3] Rodriguez, Andres, et al. “Lower numerical precision deep learning inference and training.” Intel White Paper (2018).