Visible to Intel only — GUID: GUID-68A167F3-C3E5-4B3E-9045-5A70F172E549
Abs
AbsBackward
Add
AvgPool
AvgPoolBackward
BatchNormForwardTraining
BatchNormInference
BatchNormTrainingBackward
BiasAdd
BiasAddBackward
Clamp
ClampBackward
Concat
Convolution
ConvolutionBackwardData
ConvolutionBackwardWeights
ConvTranspose
ConvTransposeBackwardData
ConvTransposeBackwardWeights
Dequantize
Divide
DynamicDequantize
DynamicQuantize
Elu
EluBackward
End
Exp
GroupNorm
GELU
GELUBackward
HardSigmoid
HardSigmoidBackward
HardSwish
HardSwishBackward
Interpolate
InterpolateBackward
LayerNorm
LayerNormBackward
LeakyReLU
Log
LogSoftmax
LogSoftmaxBackward
MatMul
Maximum
MaxPool
MaxPoolBackward
Minimum
Mish
MishBackward
Multiply
Pow
PReLU
PReLUBackward
Quantize
Reciprocal
ReduceL1
ReduceL2
ReduceMax
ReduceMean
ReduceMin
ReduceProd
ReduceSum
ReLU
ReLUBackward
Reorder
Round
Select
Sigmoid
SigmoidBackward
SoftMax
SoftMaxBackward
SoftPlus
SoftPlusBackward
Sqrt
SqrtBackward
Square
SquaredDifference
StaticReshape
StaticTranspose
Subtract
Tanh
TanhBackward
TypeCast
Wildcard
enum dnnl_alg_kind_t
enum dnnl_normalization_flags_t
enum dnnl_primitive_kind_t
enum dnnl_prop_kind_t
enum dnnl_query_t
enum dnnl::normalization_flags
enum dnnl::query
struct dnnl_exec_arg_t
struct dnnl_primitive
struct dnnl_primitive_desc
struct dnnl::primitive
struct dnnl::primitive_desc
struct dnnl::primitive_desc_base
enum dnnl_rnn_direction_t
enum dnnl_rnn_flags_t
enum dnnl::rnn_direction
enum dnnl::rnn_flags
struct dnnl::augru_backward
struct dnnl::augru_forward
struct dnnl::gru_backward
struct dnnl::gru_forward
struct dnnl::lbr_augru_backward
struct dnnl::lbr_augru_forward
struct dnnl::lbr_gru_backward
struct dnnl::lbr_gru_forward
struct dnnl::lstm_backward
struct dnnl::lstm_forward
struct dnnl::rnn_primitive_desc_base
struct dnnl::vanilla_rnn_backward
struct dnnl::vanilla_rnn_forward
Visible to Intel only — GUID: GUID-68A167F3-C3E5-4B3E-9045-5A70F172E549
Low Precision
oneDNN Graph provides low precision support with int8 (signed/unsigned 8-bit integer), bf16 and f16 data types. oneDNN Graph API expects the computation graph is converted to low precision representation, the data’s precision and quantization parameters are specified explicitly. oneDNN Graph API implementation will strictly respect the numeric precision of the computation.
INT8
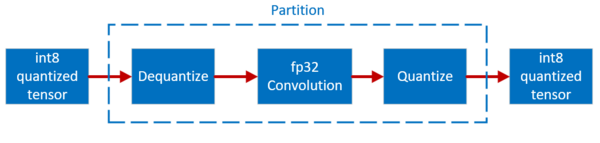
oneDNN Graph API provides below two operations to support quantized model with static quantization:
Dequantize operation takes integer tensor with its associated scale and zero point and returns f32 tensor. Quantize operation takes f32 tensor, scale, zero point, and returns integer tensor. The scale and zero point are single dimension tensors, which could contain one value for the per-tensor quantization case or multiple values for the per-channel quantization case. The integer tensor could be represented in unsigned int8 or signed int8 data type. Zero point could be zero for symmetric quantization scheme, and a non-zero value for asymmetric quantization scheme.
Dequantize and Quantize operation should be inserted manually in the graph as part of quantization process before passing to oneDNN Graph. oneDNN Graph honors the data type passed via logical tensor and faithfully follows the numeric semantics. For example, if the graph has a Quantize operation followed by a Dequantize operation with exact same scale and zero point, oneDNN Graph implementation should not eliminate them since that implicitly changes the numeric precision.
oneDNN Graph partitioning API may return a partition containing Dequantize, Quantize, and Convolution operations in-between. It is not necessary to recognize the subgraph pattern explicitly and convert to fused operation. Depending on oneDNN Graph implementation capability, the partition may include more or fewer operations.
BF16/F16
oneDNN Graph provides TypeCast operation, which can convert a f32 tensor to bf16 or f16, and vice versa. It is used to support auto mixed precision mechanism in popular deep learning frameworks. All oneDNN Graph operations support bf16 and f16 data types.
A TypeCast operation performing down conversion should be inserted clearly to indicate the use of low numeric precision. oneDNN Graph implementation fully honors the API-specified numeric precision and only performs the computation using the API-specified or higher numeric precision.
