Visible to Intel only — GUID: GUID-4D10F490-3207-4D88-B4BF-59852B58157D
Abs
AbsBackward
Add
AvgPool
AvgPoolBackward
BatchNormForwardTraining
BatchNormInference
BatchNormTrainingBackward
BiasAdd
BiasAddBackward
Clamp
ClampBackward
Concat
Convolution
ConvolutionBackwardData
ConvolutionBackwardWeights
ConvTranspose
ConvTransposeBackwardData
ConvTransposeBackwardWeights
Dequantize
Divide
DynamicDequantize
DynamicQuantize
Elu
EluBackward
End
Exp
GroupNorm
GELU
GELUBackward
HardSigmoid
HardSigmoidBackward
HardSwish
HardSwishBackward
Interpolate
InterpolateBackward
LayerNorm
LayerNormBackward
LeakyReLU
Log
LogSoftmax
LogSoftmaxBackward
MatMul
Maximum
MaxPool
MaxPoolBackward
Minimum
Mish
MishBackward
Multiply
Pow
PReLU
PReLUBackward
Quantize
Reciprocal
ReduceL1
ReduceL2
ReduceMax
ReduceMean
ReduceMin
ReduceProd
ReduceSum
ReLU
ReLUBackward
Reorder
Round
Select
Sigmoid
SigmoidBackward
SoftMax
SoftMaxBackward
SoftPlus
SoftPlusBackward
Sqrt
SqrtBackward
Square
SquaredDifference
StaticReshape
StaticTranspose
Subtract
Tanh
TanhBackward
TypeCast
Wildcard
enum dnnl_alg_kind_t
enum dnnl_normalization_flags_t
enum dnnl_primitive_kind_t
enum dnnl_prop_kind_t
enum dnnl_query_t
enum dnnl::normalization_flags
enum dnnl::query
struct dnnl_exec_arg_t
struct dnnl_primitive
struct dnnl_primitive_desc
struct dnnl::primitive
struct dnnl::primitive_desc
struct dnnl::primitive_desc_base
enum dnnl_rnn_direction_t
enum dnnl_rnn_flags_t
enum dnnl::rnn_direction
enum dnnl::rnn_flags
struct dnnl::augru_backward
struct dnnl::augru_forward
struct dnnl::gru_backward
struct dnnl::gru_forward
struct dnnl::lbr_augru_backward
struct dnnl::lbr_augru_forward
struct dnnl::lbr_gru_backward
struct dnnl::lbr_gru_forward
struct dnnl::lstm_backward
struct dnnl::lstm_forward
struct dnnl::rnn_primitive_desc_base
struct dnnl::vanilla_rnn_backward
struct dnnl::vanilla_rnn_forward
Visible to Intel only — GUID: GUID-4D10F490-3207-4D88-B4BF-59852B58157D
Batch-Reduce General Matrix Multiplication
General
The batch-reduce General Matrix Multiplication ukernel (BRGeMM) is an operation that computes a small matrix multiplication batch and accumulates their results in the same destination.
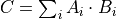
with
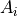 a set of matrices of dimension
a set of matrices of dimension 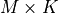
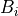 a set of matrices of dimension
a set of matrices of dimension 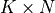
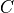 matrix of dimension
matrix of dimension 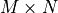 .
.
The BRGeMM ukernel also supports accumulation with values already present in , as well as post-operation and down-conversion to another 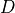 matrix:
matrix:
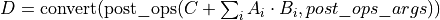
Data Types
In general, C represents an accumulation buffer. Hence, when computations are carried in floating-point arithmetic, C shall be of type f32; when computation is carried in integer arithmetic, C should be of type s32.
The BRGeMM ukernel supports the following combinations of data-types.
A |
B |
C |
D |
|---|---|---|---|
f32 |
f32 |
f32 |
u8, s8, s32, f32, f16, bf16 |
f16 |
f16 |
f32 |
u8, s8, s32, f32, f16, bf16 |
bf16 |
bf16 |
f32 |
u8, s8, s32, f32, f16, bf16 |
u8, s8 |
u8, s8 |
s32 |
u8, s8, s32, f32, f16, bf16 |
Data Representation
Because of hardware restrictions, the BRGeMM ukernel requires a specific data layout. For x86-64 architecture this layout applies to a B matrix. It is expressed through dnnl::ukernel::pack_type which can be queried by dnnl::ukernel::brgemm::get_B_pack_type call. If the query returns dnnl::ukernel::pack_type::no_trans, then packing is not required. Otherwise, the user is responsible for packing the data appropriately before calling dnnl::ukernel::brgemm::execute, either with custom code, or by using a dedicated set of APIs: dnnl::ukernel::transform::generate for generating a kernel of a transform routine and dnnl::ukernel::transform::execute to run the generated kernel.
Attributes
The following ukernel attributes can be set through dedicated setters.
NOTE:
if zero-points are passed for A/B, fpmath_mode should be set for the computation to happen over floating-point format (so up-conversion to floating-point format would happen before computation). If computation in integer format is needed, BRGeMM ukernel should be configured without zero-point, and the user should prepare a compensation term that will be passed to the binary post-op.
Implementation limitations
BRGeMM ukernel has no known limitations.
Examples
This C++ API example demonstrates how to create and execute a BRGeMM ukernel.
/*******************************************************************************
* Copyright 2024 Intel Corporation
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*******************************************************************************/
#include <algorithm>
#include <cmath>
#include <iostream>
#include <string>
#include <utility>
#include <vector>
#include "example_utils.hpp"
#include "oneapi/dnnl/dnnl_ukernel.hpp"
using namespace dnnl;
using namespace dnnl::ukernel;
using tag = memory::format_tag;
using dt = memory::data_type;
void brgemm_example() {
// Create execution dnnl::engine. Needed for reorders to operate over input
// data.
dnnl::engine engine(engine::kind::cpu, 0);
// Create dnnl::stream. Needed for reorders for the same reason.
dnnl::stream engine_stream(engine);
// ukernel dimensions.
// K is for a whole tensor, K_k is for a single ukernel.
const memory::dim M = 8, K = 128, K_k = 64, N = 48;
if (K % K_k != 0) {
printf("K_k must divide K.\n");
return;
}
const memory::dim n_calls = K / K_k;
const memory::dim lda = K;
const memory::dim ldb = N;
const memory::dim ldc = N; // Leading dimension for accumulator.
const memory::dim ldd = N; // Leading dimension for an actual output.
const memory::dim batch_size = n_calls - 1;
memory::data_type a_dt = dt::u8;
memory::data_type b_dt = dt::s8;
memory::data_type c_dt = dt::s32; // Accumulator data type.
memory::data_type d_dt = dt::f32; // Output data type.
// A, B, and C tensors dimensions.
memory::dims A_dims = {M, K};
memory::dims B_dims = {K, N};
memory::dims C_dims = {M, N};
memory::dims D_dims = {M, N};
memory::dims binary_add_dims = {1, 1};
memory::dims B_scales_dims = {1, N};
// Allocate buffers with user data.
std::vector<float> A_user_data(product(A_dims));
std::vector<float> B_user_data(product(B_dims));
std::vector<float> binary_add_user_data(product(binary_add_dims));
std::vector<float> B_scales_user_data(product(B_scales_dims));
std::vector<float> D_data(product(D_dims)); // For reference comparison
std::vector<float> D_user_data(product(D_dims)); // For reference comparison
// Initialize A.
std::generate(A_user_data.begin(), A_user_data.end(), []() {
static int i = 0;
return i++ % 4;
});
// Initialize B.
std::generate(B_user_data.begin(), B_user_data.end(), []() {
static int i = 6;
static int sign_gen = 0;
int sign = (sign_gen++ % 2) ? -1 : 1;
float val = sign * (i++ % 5);
return val;
});
// Initialize binary_add.
std::generate(
binary_add_user_data.begin(), binary_add_user_data.end(), []() {
static int i = 3;
return i++ % 6;
});
// Initialize B scales.
std::generate(B_scales_user_data.begin(), B_scales_user_data.end(), []() {
static int i = 4;
return (float)(i++ % 16) / 8.f;
});
// Create f32 memories. They are used as data holders and reorder into
// memories passed to the ukernel.
auto A_f32_md = memory::desc(A_dims, dt::f32, tag::ab);
auto B_f32_md = memory::desc(B_dims, dt::f32, tag::ab);
auto binary_add_f32_md = memory::desc(binary_add_dims, dt::f32, tag::ab);
auto B_scales_f32_md = memory::desc(B_scales_dims, dt::f32, tag::ab);
auto D_f32_md = memory::desc(D_dims, dt::f32, tag::ab);
auto A_f32_mem = memory(A_f32_md, engine, A_user_data.data());
auto B_f32_mem = memory(B_f32_md, engine, B_user_data.data());
auto binary_add_f32_mem
= memory(binary_add_f32_md, engine, binary_add_user_data.data());
auto B_scales_f32_mem
= memory(B_scales_f32_md, engine, B_scales_user_data.data());
auto D_f32_mem = memory(D_f32_md, engine, D_user_data.data());
// Create ukernel memories in requested data types.
// Note that all formats are `ab`.
auto A_md = memory::desc(A_dims, a_dt, tag::ab);
auto B_md = memory::desc(B_dims, b_dt, tag::ab);
auto binary_add_md = memory::desc(binary_add_dims, dt::f32, tag::ab);
auto B_scales_md = memory::desc(B_scales_dims, dt::f32, tag::ab);
auto C_md = memory::desc(C_dims, c_dt, tag::ab);
auto D_md = memory::desc(D_dims, d_dt, tag::ab);
auto A_mem = memory(A_md, engine);
auto B_mem = memory(B_md, engine);
auto binary_add_mem = memory(binary_add_md, engine);
auto B_scales_mem = memory(B_scales_md, engine);
auto C_mem = memory(C_md, engine);
auto D_mem = memory(D_md, engine);
const auto *A_ptr = reinterpret_cast<uint8_t *>(A_mem.get_data_handle());
auto *B_ptr = reinterpret_cast<uint8_t *>(B_mem.get_data_handle());
const size_t a_dt_size
= memory::data_type_size(A_mem.get_desc().get_data_type());
const size_t b_dt_size
= memory::data_type_size(B_mem.get_desc().get_data_type());
// Reorder user data into buffers passed to ukernels in target data types.
reorder(A_f32_mem, A_mem).execute(engine_stream, A_f32_mem, A_mem);
reorder(B_f32_mem, B_mem).execute(engine_stream, B_f32_mem, B_mem);
reorder(binary_add_f32_mem, binary_add_mem)
.execute(engine_stream, binary_add_f32_mem, binary_add_mem);
reorder(B_scales_f32_mem, B_scales_mem)
.execute(engine_stream, B_scales_f32_mem, B_scales_mem);
reorder(D_f32_mem, D_mem).execute(engine_stream, D_f32_mem, D_mem);
// Prepare C buffer. Needed to use a single ukernel in the example with
// `beta = 1.f`.
// Note: to avoid this step, the first ukernel should run `beta = 0`, and it
// will initialize C buffer with intermediate values.
float *C_ptr = reinterpret_cast<float *>(C_mem.get_data_handle());
for (memory::dim i = 0; i < M * N; i++) {
C_ptr[i] = 0;
}
// Create ukernel post-ops (ReLU + Add).
// It reuses `primitive_attr` abstraction.
post_ops brgemm_ops;
brgemm_ops.append_eltwise(
algorithm::eltwise_relu, /* alpha = */ 0.f, /* beta = */ 0.f);
brgemm_ops.append_binary(algorithm::binary_add, binary_add_md);
// Create BRGeMM ukernel objects.
// There are two objects:
// * `brg` is the main one which operates over partitioned K dimension. It
// utilizes `beta = 1.f` to accumulate into the same buffer. It also uses
// `batch_size` to process as much as `n_calls - 1` iterations.
// * `brg_po` is the ukernel that would be called the last in the chain
// since it has attributes attached to the object and those will execute
// after all accumulation over K dimension is done.
// Note: `beta = 1.f` makes a ukernel reusable over K but will require
// zeroing the correspondent piece of accumulation buffer.
brgemm brg, brg_po;
if (batch_size > 0) {
try {
// Construct a basic brgemm object.
brg = brgemm(
M, N, K_k, batch_size, lda, ldb, ldc, a_dt, b_dt, c_dt);
// Instruct the kernel to append the result to C tensor.
brg.set_add_C(true);
// Finalize the initialization.
brg.finalize();
// Generate the executable JIT code for the objects.
brg.generate();
} catch (error &e) {
if (e.status == dnnl_unimplemented)
throw example_allows_unimplemented {
"Kernel is not supported on this platform.\n"};
// on any other error just re-throw
throw;
}
}
try {
// Construct a basic brgemm object.
brg_po = brgemm(M, N, K_k, 1, lda, ldb, ldc, a_dt, b_dt, c_dt);
// Instruct the kernel to append the result to C tensor.
brg_po.set_add_C(true);
// Specify post-ops for the brgemm object.
brg_po.set_post_ops(ldd, d_dt, brgemm_ops);
// Specify quantization scales for B.
if (b_dt == dt::s8 || b_dt == dt::u8) {
brg_po.set_B_scales(/* mask = */ 2);
}
// Finalize the initialization.
brg_po.finalize();
// Generate the executable JIT code for the objects.
brg_po.generate();
} catch (error &e) {
if (e.status == dnnl_unimplemented)
throw example_allows_unimplemented {
"Kernel is not supported on this platform.\n"};
// on any other error just re-throw
throw;
}
// Query a scratchpad size and initialize a scratchpad buffer if the ukernel
// is expecting it. This is a service space needed, has nothing in common
// with accumulation buffer.
size_t scratchpad_size = brg_po.get_scratchpad_size();
std::vector<uint8_t> scratchpad(scratchpad_size);
uint8_t *B_blocked = nullptr;
void *B_base_ptr = B_ptr;
size_t blocked_B_size = 0;
// Query the packing requirement from the kernel. It's enough to query
// packing requirements from a single object as long as only dimension
// settings change between objects.
// Note: example uses the one that always present regardless of dimensions.
const bool need_pack = brg_po.get_B_pack_type() == pack_type::pack32;
// If packing is needed, create a dedicated object for data transformation.
if (need_pack) {
// Packing B tensor routine. The BRGeMM ukernel expects B passed in a
// special VNNI format for low precision data types, e.g., bfloat16_t.
// Note: the routine doesn't provide a `batch_size` argument in the
// constructor as it can be either incorporated into `K` dimension, or
// manually iterated over in a for-loop on the user side.
transform pack_B(/* K = */ K_k * n_calls, /* N = */ N,
/* in_pack_type = */ pack_type::no_trans, /* in_ld = */ N,
/* out_ld = */ ldb, /* in_dt = */ b_dt, /* out_dt = */ b_dt);
// Size of the packed tensor.
blocked_B_size = ldb * K_k * memory::data_type_size(b_dt);
B_blocked = new uint8_t[blocked_B_size * n_calls];
B_base_ptr = B_blocked;
// Pack B routine execution.
// Note: usually should be split to process only that part of B that the
// ukernel will execute.
pack_B.generate();
pack_B.execute(B_ptr, B_blocked);
}
// BRGeMM ukernel execute section.
// Prepare buffers for execution.
std::vector<std::pair<memory::dim, memory::dim>> A_B_offsets(batch_size);
for (memory::dim i = 0; i < batch_size; i++) {
const memory::dim A_offset_i = i * K_k * a_dt_size;
const memory::dim B_offset_i
= need_pack ? i * blocked_B_size : i * N * K_k * b_dt_size;
A_B_offsets[i] = std::make_pair(A_offset_i, B_offset_i);
}
if (brg) {
// Make an object to call HW specialized routines. For example, prepare
// AMX unit.
brg.set_hw_context();
// An execute call. `A_B` is a vector of pointers to A and packed B
// tensors. `acc_ptr` is a pointer to an accumulator buffer.
brg.execute(A_ptr, B_base_ptr, A_B_offsets, C_ptr, scratchpad.data());
}
// Same set of operations for a ukernel with post-ops.
std::vector<std::pair<memory::dim, memory::dim>> A_B_po_offsets;
const memory::dim A_offset_po = batch_size * K_k * a_dt_size;
const memory::dim B_offset_po = need_pack
? batch_size * blocked_B_size
: batch_size * N * K_k * b_dt_size;
A_B_po_offsets.emplace_back(A_offset_po, B_offset_po);
// This object also requires this call.
brg_po.set_hw_context();
// Prepare post-ops arguments and put them in a vector to make sure pointers
// are sitting side by side.
std::vector<const void *> bin_po_ptrs;
bin_po_ptrs.push_back(binary_add_mem.get_data_handle());
// Setting post-ops arguments into an attributes arguments storage.
attr_params params;
params.set_post_ops_args(bin_po_ptrs.data());
params.set_B_scales(B_scales_mem.get_data_handle());
// An execute call. The difference here is an additional D tensor pointer
// to store final output result after finishing accumulation and post-ops
// application.
brg_po.execute(A_ptr, B_base_ptr, A_B_po_offsets, C_ptr,
D_mem.get_data_handle(), scratchpad.data(), params);
// Once all computations are done, need to release HW context.
brgemm::release_hw_context();
// Clean up an extra buffer.
delete B_blocked;
// Used for verification results, need unconditional reorder.
auto user_D_mem = memory(D_f32_md, engine, D_data.data());
reorder(D_mem, user_D_mem).execute(engine_stream, D_mem, user_D_mem);
// Skip the check by default as data filling doesn't help with proper
// verification of the result. Negative result doesn't necessarily mean
// the functionality is broken. This is just a general sanity check.
if (true) return;
// A simplified fast verification that ukernel returned expected results.
// Note: potential off-by-1 or 2 errors may pop up. This could be solved
// with more sparse filling.
bool to_throw = false;
for (int m = 0; m < M; m++) {
for (int n = 0; n < N; n++) {
D_user_data[m * N + n] = 0;
for (int k = 0; k < K; k++) {
D_user_data[m * N + n]
+= A_user_data[m * K + k] * B_user_data[k * N + n];
}
// B scales ref
D_user_data[m * N + n] *= B_scales_user_data[n];
// Relu post-op ref
D_user_data[m * N + n] = std::max(D_user_data[m * N + n], 0.f);
// Binary post-op ref
D_user_data[m * N + n] += binary_add_user_data[0];
const float diff
= fabsf(D_user_data[m * N + n] - D_data[m * N + n]);
if (diff > 1.19e-7) {
to_throw = true;
if (true) {
printf("Error: [%3d:%3d] Ref:%12g Got:%12g Diff:%12g\n", m,
n, D_user_data[m * N + n], D_data[m * N + n], diff);
}
}
}
}
if (to_throw) { throw status::runtime_error; }
}
int main(int argc, char **argv) {
return handle_example_errors({dnnl::engine::kind::cpu}, brgemm_example);
}