Identify Bottlenecks Iteratively: Cache-Aware Roofline
Improving an application’s performance is often a multi-step process. You can take advantage of the Intel® Advisor Cache-Aware Roofline feature and supporting analysis types to perform step-by-step, systematic optimization: identify and address bottlenecks, then re-run analyses to see how your code improves with each iteration and what to do next. This section provides an illustrated example of a workflow that uses the Recommendations tab, Code Analytics tab, refinement reports, and other features to address a range of real-world issues that may be affecting your code.
Scenario
While the first versions of the Roofline feature supported only floating-point operations, the Intel Advisor 2019 added support for integer operations as well, extending its usefulness to integer-heavy domains like machine learning.
The process of optimizing an application with the Roofline feature is essentially the same for both types of operations, but the algorithm in this recipe uses integers. It is a standard matrix multiplication application and is subject to several performance bottlenecks.
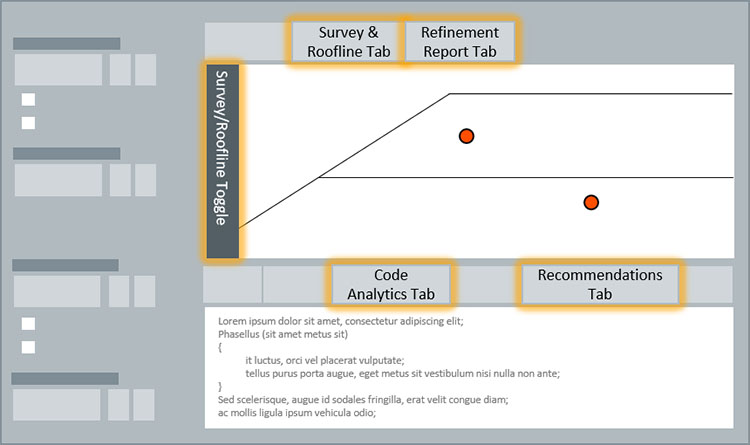
The process of iteratively addressing bottlenecks uses multiple analysis types and reports found throughout the Intel Advisor interface, as shown in the diagram below.
Ingredients
This section lists the hardware and software used to produce the specific results shown in this recipe:
Performance analysis tools: Intel Advisor
The latest version is available for download at https://www.intel.com/content/www/us/en/developer/tools/oneapi/advisor.html.
Application: Matrix multiplication application described in Scenario.
Not available for download.
Compiler: Intel® C++ Compiler 19.0.3 (2019 Update 3)
Operating system: Microsoft Windows* 10 Enterprise
CPU: Intel® Core™ i5-6300U processor
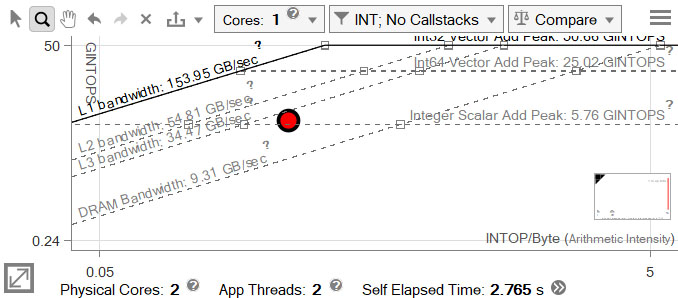
Collect Baseline Results
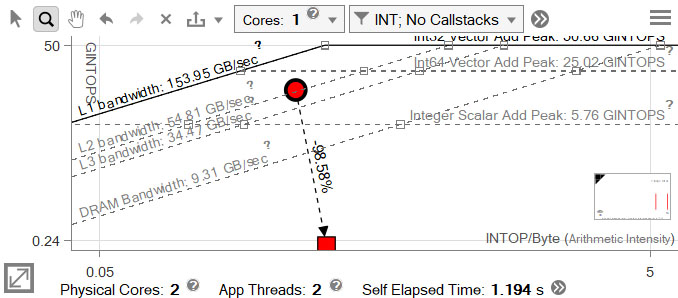
Run a standard Roofline analysis on the compiled application and view the result in the GUI.
Change the Roofline chart settings as necessary - in this case, set the data type to INT and the core count to 1 (the second thread in this application is a launch/setup thread).
Save the result for later with the
 control.
control.
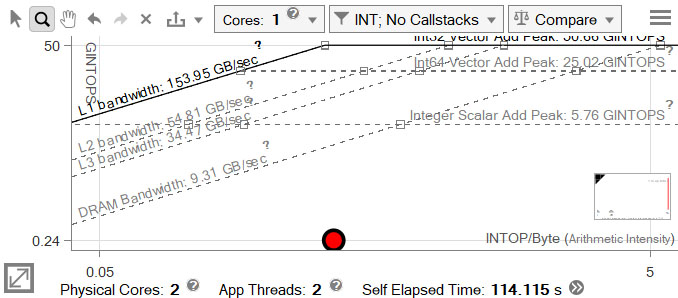
The large red dot is the matrix multiplication loop, which took approximately 166 seconds to run.
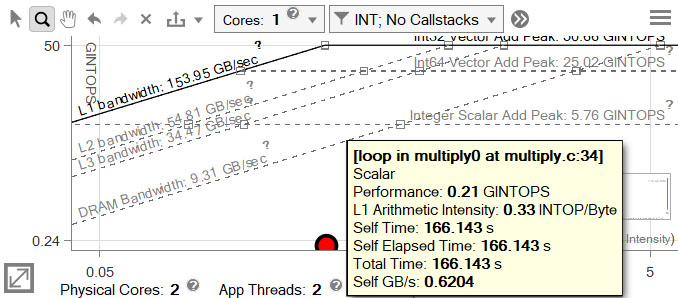
Vectorize the Loop
The position of the loop on the chart indicates that either the Scalar Add Peak or DRAM Bandwidth roofs likely represent the bottleneck.
Check the Recommendations tab for hints about which problem to address first.

Run a Dependencies analysis on the loop to determine whether it can be safely vectorized.
The result can be found in the Refinement report. There is a dependency, but the Recommendations tab provides a suggested workaround.
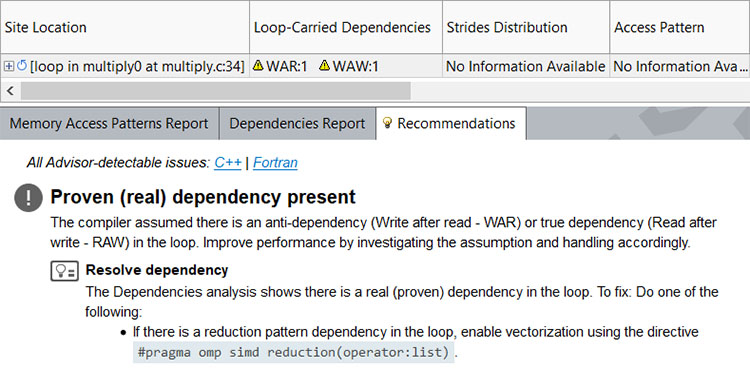
Add a reduction pragma to the code as the Intel Advisor suggests.
Recompile, re-run the Roofline analysis, and view the result.
Despite the change, there is little improvement.
Transpose a Matrix
Search the Survey report for clues about the lack of improvement.
The Efficiency bar in Vectorized Loops is grey, indicating the loop is no faster than the compiler estimation of its scalar performance. There is also a possible inefficient memory access pattern listed in Performance Issues.

Check the Recommendations tab for more details on the possible performance issue.

Run a Memory Access Patterns analysis on the loop.
In the resulting Refinement report, we can see one of the matrices is traversed by column, which results in a poor stride of 32768.
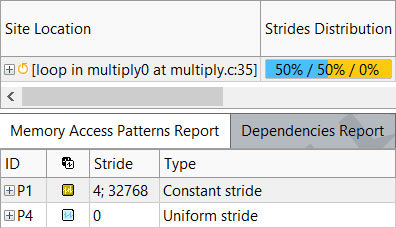
Create a transposed version of matrix b that can be traversed by row rather than by column.
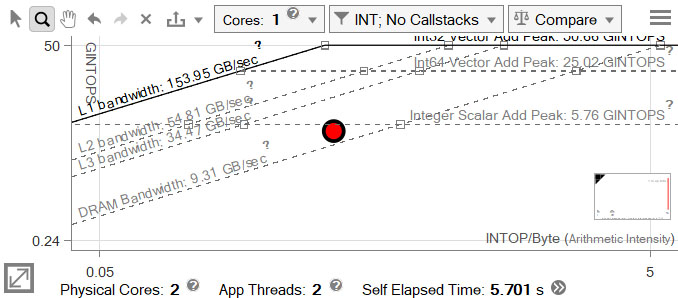
Recompile and re-run the Roofline analysis.
Performance is now drastically improved, but despite vectorization, the loop now rests under the Scalar Add Peak.
Use the AVX2 Instruction Set
Check the Vectorized Loops data in the Survey report.
Efficiency is now high; however, the loop is only using SSE2 instructions, because the compiler defaults to this instruction set when no other is specified. Intel Advisor indicates a higher instruction set is available.

Recompile with AVX2 instructions and re-run the Roofline analysis.
The loop runs more than a full second faster.

Block for L2 Cache
The Scalar Add Peak is completely addressed. The next roofs are the L3 and L2 Bandwidth roofs.
Run a Memory Access Patterns analysis on all three levels of the loop to evaluate memory usage.
The memory footprint for the outer two loops is much larger than the caches on this machine.

Divide the calculation into blocks sized for the L2 cache, to maximize the amount of work done for each piece of data loaded into the cache.
Recompile and re-run the Roofline analysis.
While the dot did not move far, the time is cut nearly in half.
Align Data
There are no Recommendations at this point, so check the Code Analytics tab.
The Compiler Notes on Vectorization indicate the data is unaligned. This can result in excessive memory operations, visible in the instruction mixes.

Use the appropriate aligned allocation, such as _mm_malloc(), to allocate the data. Add an alignment pragma to the loop, and recompile with /Oa or -fno-alias.
Recompile, re-run the Roofline analysis, and use Compare to load the baseline result.
The loop time drops to about 1 second from its original 166 seconds.