
Hugging Face* already hosts a leaderboard, so why did we create a new one? Because comparing quantization results is not straightforward. The primary issue is the lack of accuracy results for most quantized models. Another issue is that searching for specific model names in the Hugging Face leaderboard yields numerous models, so a lot of manual effort is required to determine whether they are merged, fine-tuned, in FP16, quantized, or mixed. This poses challenges for model deployment.
Therefore, we are pleased to introduce the low-precision quantized leaderboard, which addresses these issues by focusing on quantized LLM models and enhancing the search engine. Users can now instantly search quantized LLMs by algorithm (AutoRound, GPTQ, AWQ, BitsAndBytes, and GGUF), computing data type (int8, fp16, bf16, etc.), weight data type (fp4, int4, nf4, etc.), model size, and whether or not double quantization is enabled. The low-bit quantized open LLM leaderboard is a valuable tool for finding high-quality models that can be deployed efficiently on a given client.
Quantization Approaches
A robust quantization tool is needed to effectively benchmark LLM models across diverse quantization methods and varied weight and computing data types. Our leaderboard leverages Intel® Extension for Transformers* for LLM quantization support. This solution offers a Transformer-like API with a unified interface that seamlessly integrates well-known weight-only quantization methods such as GPTQ, AWQ, etc. Additionally, the tool incorporates Intel’s AutoRound quantization algorithm for low-bit LLM inference. The quantization functionality of Intel Extension for Transformers is built on top of Intel® Neural Compressor, an open source model-compression tool.
Low-Bit Quantized Open LLM Leaderboard
The leaderboard encompasses ten distinct benchmarks: ARC-c, ARC-e, Boolq, HellaSwag, Lambada_openai, MMLU, Openbookqa, Piqa, Truthfulqa_mc1, and Winogrande. Rankings are determined by the average score across these benchmarks, with the option to prioritize specific benchmarks for reranking.
Our evaluation shows that AutoRound approaches near-lossless compression for a range of popular models. It consistently outperforms other methods such as GPTQ and AWQ, and shows better accuracy than GGUF. Llama* 2 7b-chat and Mistral*-7b-instrut comparisons are shown in Figures 1 and 2.
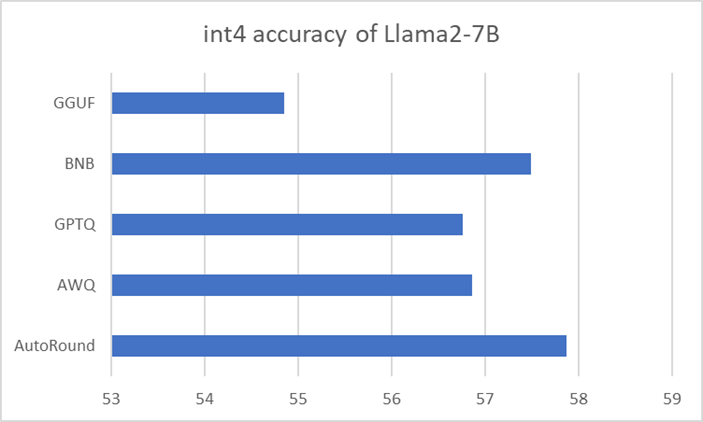
Figure 1. Average accuracy (higher is better) of int4 Llama 2 7B-chat
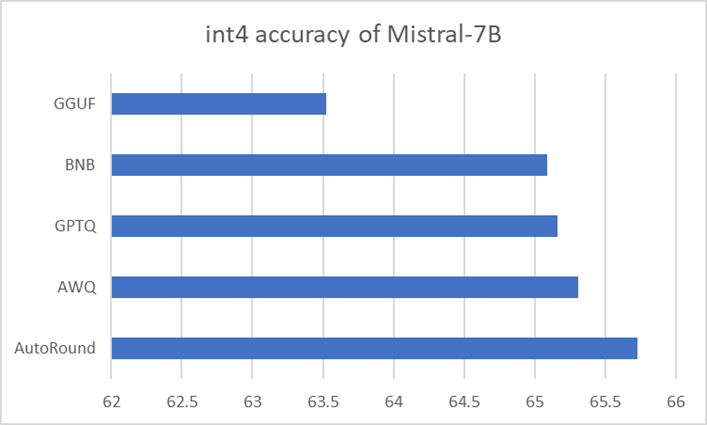
Figure 2. Average accuracy (higher is better) of int4 Mistral-7B-instruct-v0.2
We also compared the 13B AutoRound and fp16 7B models, which showed AutoRound consistently outperforming the fp16 7B in all individual metrics as well as on average (Table 1). This gives users the option of low-bit, quantized middle-sized LLMs that outperform half-precision, small-sized LLMs even though their model size is smaller.

Table 1. Accuracy (higher is better) of fp16 7B vs. 13B AutoRound models
Moreover, AutoRound can accommodate the majority of popular models, whereas other quantization algorithms have limitations. This is why AutoRound models are readily accessible (Table 2).
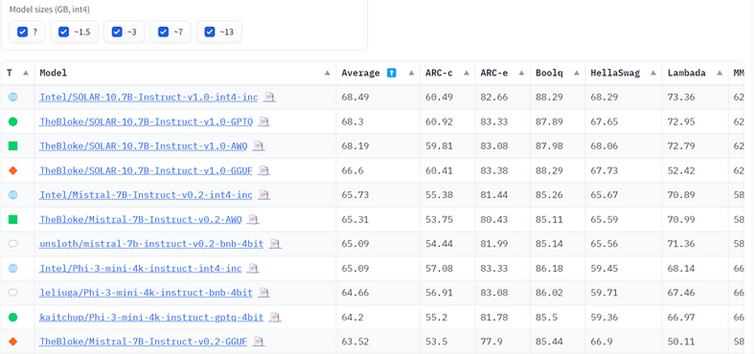
Table 2. Low-bit quantized open LLM leaderboard (as of May 11, 2024)
Additionally, AutoRound offers support for quantizing the lm_head, a feature overlooked by algorithms like AWQ. Unlike GPTQ and AWQ, AutoRound can automatically accommodate new models. Finally, AutoRound provides calibration capabilities across various datasets.
Quantization Sample Code
The following example code shows how to apply AutoRound to quantize LLMs with Transformer-like API in Intel Extension for Transformers:
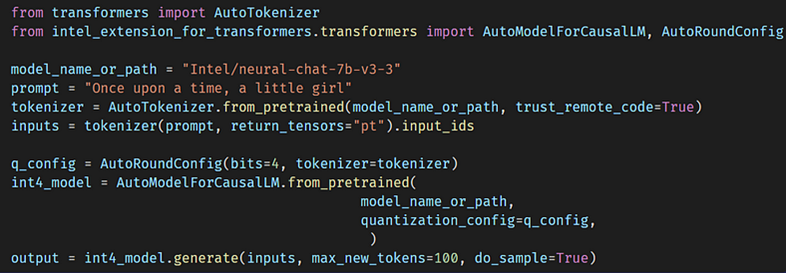
For more details, please refer to the AutoRound example in Intel Extension for Transformers.
Collaborations and Future Work
We encourage you to explore our leaderboard and upload your quantized models. We look forward to hearing your feedback, questions, or comments. If you want to give it a try on your proprietary models, kindly raise a ticket and see how we can help you.
In future, we plan to expand the leaderboard to support ultra-low-bit quantized open LLMs. If you are interest in this topic, feel free to drop us an email. Again, your feedback and contributions will be greatly appreciated.