
GGUF (GPT-Generated Unified Format) is a new binary format that allows quick inspection of tensors and metadata within the file (Figure 1). It represents a substantial leap in language model file formats, optimizing the efficiency of storing and processing large language models (LLMs) like GPT. Converting a PyTorch* model to the GGUF format is straightforward.

Figure 1. GGUF format (source)
{kind=link}
HuggingFace* Transformers recently added support for GGUF with Transformers PR. Transformers performs dequantization of GGUF models to FP32 before conducting inference using PyTorch. It’s easy to use; just specify the gguf_file parameter in from_pretrained, as shown in Figure 2.
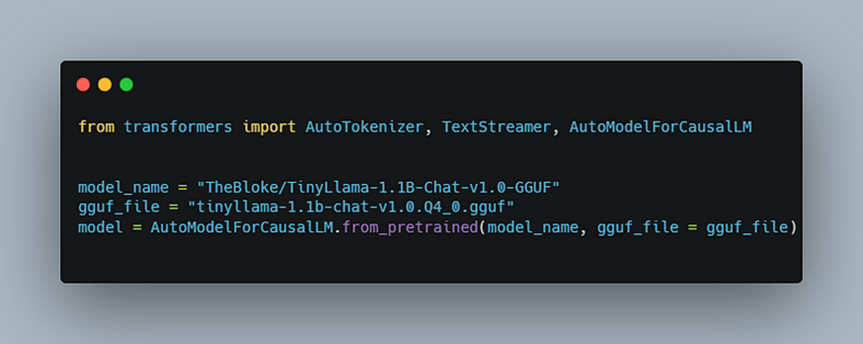
Figure 2. Using GGUF models in HuggingFace Transformers
The Intel® Extension for Transformers* accelerates low-bit LLM inference. It extends HuggingFace Transformers and enhances performance on Intel® platforms. It supports GGUF inference on a broad range of models. Its usage is also straightforward (Figure 3).
![]()
Figure 3. Using GGUF models in Intel Extension for Transformers
Currently, Transformers only supports Llama and Mistral, but we support over 50 popular LLMs (Table 1).
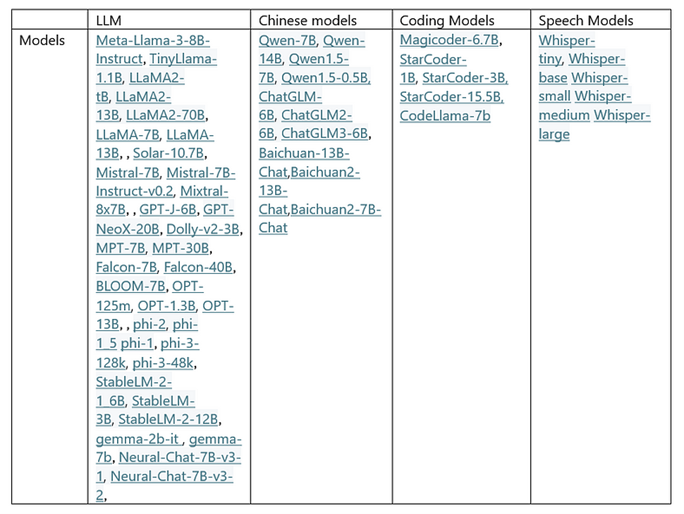
Table 1. Supported LLMs
Setup is easy. First, install Neural Speed:
git clone https://github.com/intel/neural-speed.git cd neural_speed python setup.py install
Second, install Intel Extension for Transformers:
git clone https://github.com/intel/intel-extension-for-transformers.git cd intel_extension_for_transformers python setup.py install
Finally, install Transformers:
pip install transformers
The code snippet in Figure 4 can be used to easily generate text.
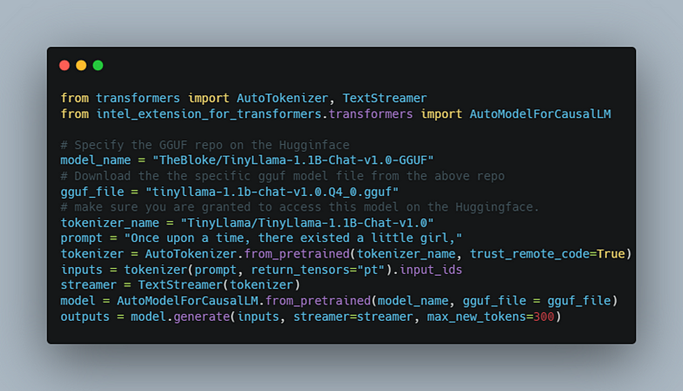
Figure 4. Example code to generate text
We conducted a performance comparison with Transformers on an Intel® Xeon® Platinum/Intel® Core™ Ultra 5 125H system (CPU max MHz: 4400.0000, CPU min MHz: 400.0000, Total Memory 32 GB (8 x 4 GB LPDDR5, [7467 MT/s]), Ubuntu* 13.2.0–9ubuntu1). Our comparison was limited to TinyLlama-1.1B-Chat because of the small memory. Intel Extension for Transformers provided superior latency and memory usage compared to Transformers (Table 2).
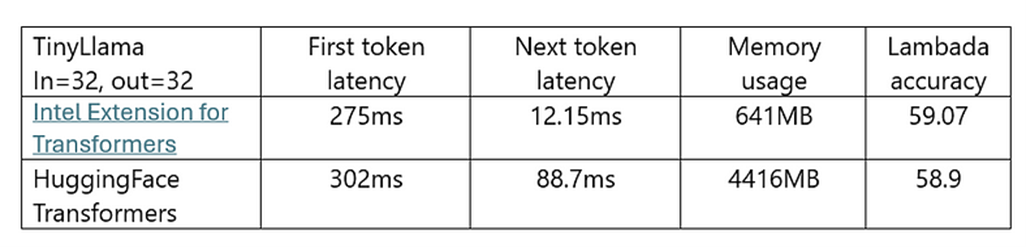
Table 2. Performance, memory usage, and accuracy comparisons
Intel Extension for Transformers is a great way to minimize token latency on memory-constrained systems, while requiring only small code changes. Kernel support ranges from 1 to 8 bits. There are also more advanced features like StreamingLLM and Tensor Parallelism, so we encourage you to take a look at Intel Extension for Transformers.