
Intel® Data Streaming Accelerator (Intel® DSA) is a high-performance data copy and transformation accelerator, available starting from 4th Gen Intel® Xeon® Scalable processors. It supports various data operations such as memory copy, compare, fill, compare, etc. Intel DSA employs work queues and descriptors to interact with the CPU software. The descriptor contains information about the desired operation such as operation type, source and destination address, data length, etc. For additional information, see Beyond Direct Memory Access: Reducing the Data Center Tax with Intel® Data Streaming Accelerator in The Parallel Universe, Issue 53.
Many scientific and commercial applications require efficient CPU’s and high memory bandwidth to achieve optimal performance. While CPU’s receive significant performance enhancements with each generation through additional cores, wider SIMD units, and new ISA extensions among other microarchitectural features, the gains in DRAM bandwidth have historically lagged the CPU improvements. This leads to a scenario where real-world applications do not observe expected performance gains, as the speed at which data is fetched from DRAM is not fast enough to prevent stalls of CPU execution units. This has been a well-known observation for many years and is popularly known as “memory wall.”
CPUs have architectural buffers in the form of load/store queues and super queues and hardware prefetchers that mitigate some of the memory wall effects. However, their impact on memory bandwidth is limited at low core counts because each CPU core can only have a limited number of entries in hardware queues. When the data needs to be fetched from DRAM, the queues become the bottleneck as each memory request occupies the buffer slots for a longer duration to cover the DRAM latency. Hence, it is often common to use more CPU cores to generate memory access requests simultaneously to fully saturate available DRAM bandwidth. However, it’s still a challenge to achieve higher memory bandwidth at lower core counts.
This article discusses techniques to complement the strengths of Intel DSA in combination with CPUs to accelerate memory-bound kernels (i.e., operations where performance is primarily determined by how fast the memory subsystem can deliver the data operands for computations to the CPU cores).
We will use the standard STREAM benchmark to measure performance. STREAM is used to characterize the memory performance of CPUs. It consists of four kernels: Copy, Scale, Add, and Triad (Table 1). All four kernels are memory-bound operations.
|
Kernel |
Operation |
Bytes Read (with cache-bypassing stores) |
Bytes Written |
FLOPs |
|---|---|---|---|---|
|
COPY |
A[i] = B[i] |
8 |
8 |
0 |
|
SCALE |
A[i] = scalar × B[i] |
8 |
8 |
1 |
|
ADD |
C[i] = A[i] + B[i] |
16 |
8 |
1 |
|
TRIAD |
C[i] = A[i] + scalar × B[i] |
16 |
8 |
2 |
Table 1. STREAM kernel characteristics
While Intel DSA acts as a powerful data copy/transformation engine, it does not support execution of arithmetic operations like multiplication, addition, fused multiply-add, etc. on data operands. So on its own, it cannot be used in execution of application kernels that contain a mix of memory and compute operations. However, Intel DSA provides the unique capability to control the location of destination data produced from its operations: DRAM or last-level-cache (LLC) on CPUs. For example, DSA can copy data from a source buffer residing in DRAM to a destination located either in DRAM (bypassing the CPU caches) or LLC.
We can exploit the cache writing capability of Intel DSA and use it as a proxy hardware prefetch engine from DRAM to LLC and rely on the CPU cores for computation operations. The core of the solution works by efficiently overlapping Intel DSA data transfers (from DRAM to LLC) with CPU computations happening from LLC to CPU registers through asynchronous copies. By default, Intel DSA can write to an approximately 14 MB portion of LLC (two out of 15-way LLC, effective size = 2/15 * size of LLC = 14 MB on Intel 4th Gen Xeon Scalable Processors). Figure 1 shows the high-level differences between the CPU-only approach compared to the hybrid CPU + Intel DSA workflow.
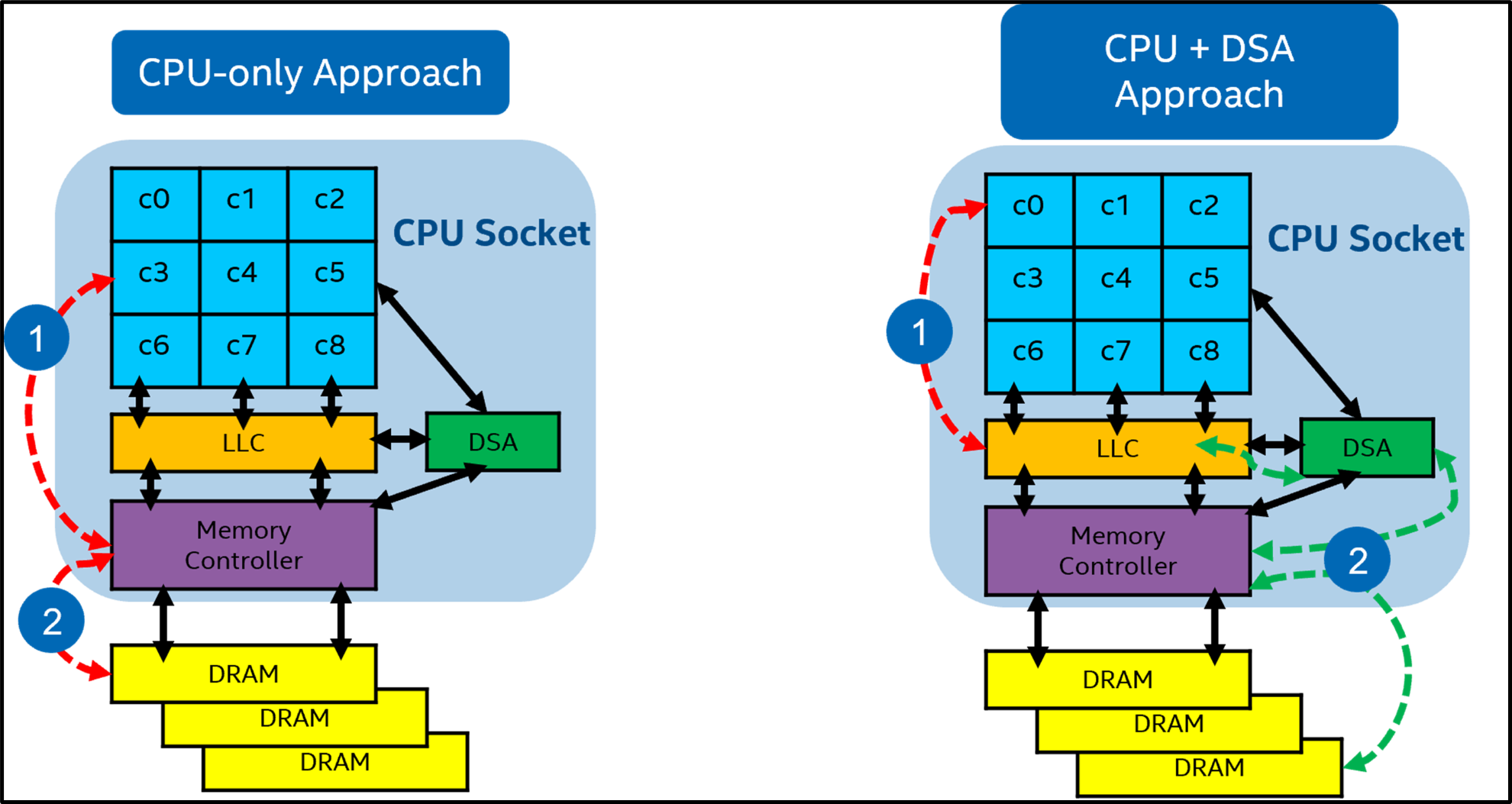
Figure 1. High-level differences between the CPU-only approach and the hybrid CPU + Intel DSA implementation
In the CPU-only approach, steps 1 and 2 refer to the load/store requests originating from CPU cores for data residing in DRAM and going to the memory controllers. In step 1 of the CPU + Intel DSA approach, the CPU loads data from LLC instead of DRAM. In step 2, Intel DSA initiates the data transfer from DRAM (through the memory controller) to LLC. Steps 1 and 2 happen in a pipelined and asynchronous manner such that the data the CPU needs to read at time Tx is already copied to LLC by DSA in T(x-1). In other words, while Intel DSA will concurrently fetch the next iteration’s data from DRAM and write them to LLC, the CPUs will read the current iteration’s data from LLC to perform compute operations. Software pipelining will ensure that all DSA engines are efficiently used.
Figure 2 shows the workflow of the hybrid CPU + Intel DSA pipelining approach for an elementary CPU operation like reading a data array from DRAM. Here, for each CPU thread, we use a queue depth of four with each entry holding 1 MB of data of input buffers. So, basically, while the CPU is reading 4 MB from LLC, DSA will fetch the next chunk of 4MB from DRAM.
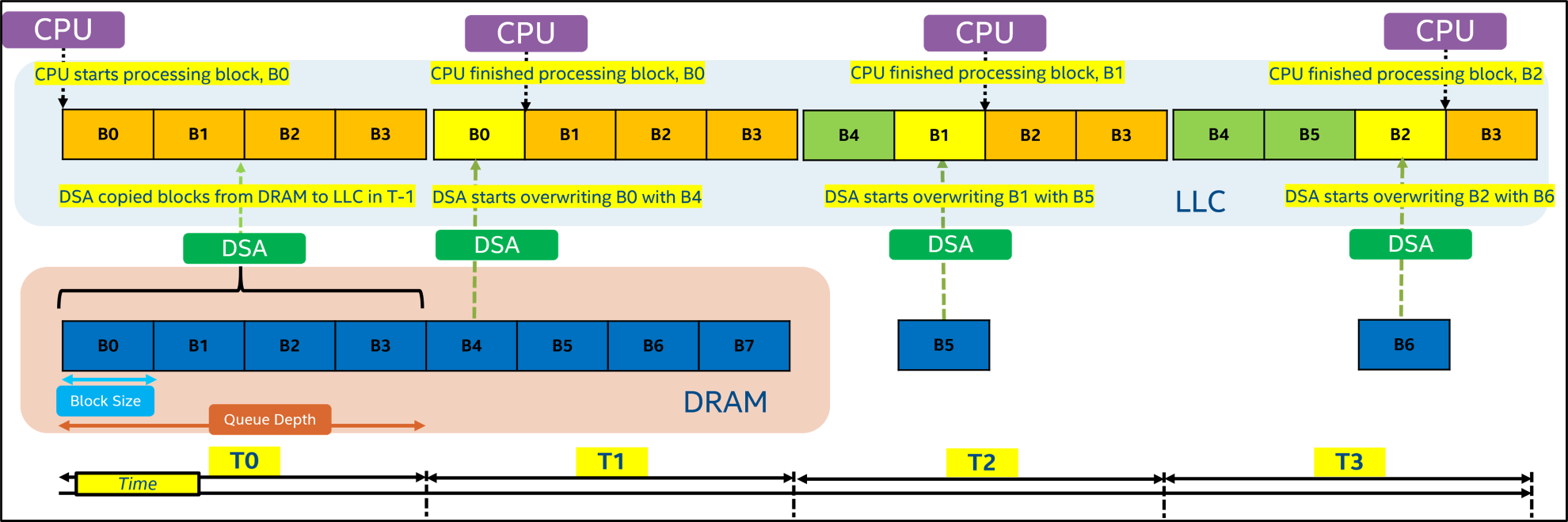
Figure 2. Sample pipeline of data operations in hybrid CPU + Intel DSA implementation showing access for one buffer with one CPU core
Intel® Data Mover Library (Intel® DML) is an open source library providing C/C++ API’s to execute data operations using Intel DSA. We use Intel DML to initialize the Intel DSA, create work descriptors, and submit and query job status for STREAM kernels. An example is shown in Figure 3. Briefly, the Triad operation is parallelized using OpenMP* threads. Each thread partitions the data buffers equally and uses a queue-like mechanism to further divide the thread chunk into blocks. Each CPU thread submits asynchronous copy operations to Intel DSA and waits for its completion before accessing the data to compute the Triad operation. In the loop, the asynchronous copy operations are submitted for data that are to be accessed in a future iteration, which is the depth of the queue. Figure 4 shows the code for the asynchronous copy operation with the destination to be in LLC (DML_FLAG_PREFETCH_CACHE) using Intel DML.

Figure 3. Hybrid CPU + Intel DSA implementation of the STREAM Triad kernel using OpenMP and Intel DML

Figure 4. Asynchronous copy to LLC using Intel DML
In addition to the standard STREAM kernels, we also benchmarked a vector dot-product operation (res += a[i] × b[i]; all reads, no writes) as it is a commonly encountered operation in many application domains. We benchmark the kernels as follows:
- The size of each input buffer is 1 GB. The memory footprint for Scale and Dot-product is 2 GB and Triad is 3 GB. Each kernel is executed 100 times, and the best performance is reported.
- The CPU-only implementation relies on the CPU cores to perform the operations with OpenMP parallelization. Cache-bypassing/non-temporal stores (vmovntpd) are used.
- In the Intel DSA + CPU implementation, DSA is used to fetch the input buffers from DRAM to LLC. It relies on non-temporal stores by the CPU’s to directly update destination buffers in memory.
Figure 5 shows performance at various core counts on a 4th Gen Intel Xeon Scalable Processor (56-cores, 8-channel DDR5@4800MT/s, theoretical peak bandwidth is 8 channels x 8 bytes x 4.8 GT/s = 307 GB/s). Intel DSA+CPU speedup over the CPU-only implementation is color-coded as a heatmap.
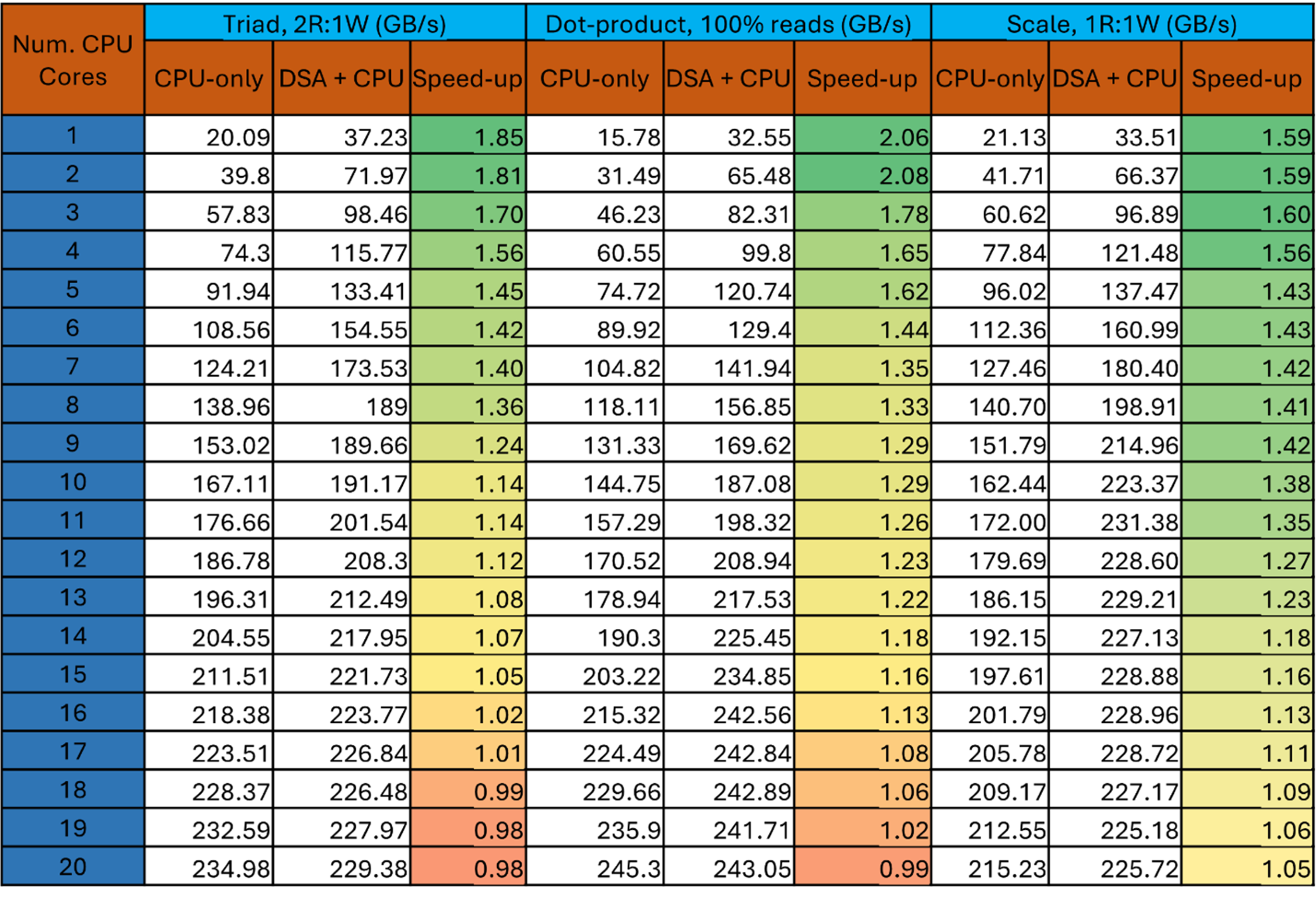
Figure 5. Performance comparison between the CPU-only and hybrid CPU + Intel DSA implementations
As mentioned earlier, 1-core CPU memory performance is determined by the size of the architectural load/store buffers, whereas Intel DSA does not have this limitation. So, in the hybrid CPU + Intel DSA method, as the Intel DSA copies data from DRAM to LLC in a pipelined manner, all the data read by the CPUs will be hit in LLC. This reduces the amount of time that memory requests reside in the load/store queues as they now are held only to meet LLC hit latency over DRAM access latency. This results in 1-core bandwidth gains of 1.6x to 2x depending on the kernel type.
At lower core counts (<4), even though the CPU is reading from LLC, the time taken to process a block of data from LLC is greater than the time the Intel DSA takes to fetch a block from DRAM. So, we get higher gains at lower core counts as we are entirely hiding the DRAM latency. As we add more CPU cores to the workflow, CPU read bandwidth from LLC is faster than Intel DSA and now CPUs are waiting for Intel DSA to finish the copies to LLC. To mitigate this issue, we use two different implementations depending on how many cores are being used. At higher core counts, there is greater contention at Intel DSA queues when there are too many outstanding requests. So, we switch to a different implementation such that the CPU also handles some memory requests along with Intel DSA. For Triad and Dot, we use the CPU as well to fetch one of the input buffers (src1) while the Intel DSA fetches the other input buffers (src2). This has the following benefits at higher core counts. First, it puts the CPU to work instead of waiting for Intel DSA to finish copying from DRAM to LLC. Second, since DSA is required to only fetch one buffer from DRAM to LLC, the number of outstanding DSA requests is cut in half, which reduces contention at the Intel DSA queues. Overall, the performance benefits of Intel DSA + CPU method gradually decrease as we increase the number of cores.
In conclusion, our STREAM benchmarks show that Intel DSA can boost performance using fewer CPU cores. For example, the Scale kernel achieves the same performance at nine cores using Intel DSA as the CPU-only implementation at 20 cores. The Triad kernel achieves the same performance at eight cores using Intel DSA as the CPU-only implementation at 12 cores. The Dot kernel achieves the same performance at five cores using Intel DSA as the CPU-only implementation at eight cores. This helps accelerate heterogeneous applications because a lower number of CPUs in combination with Intel DSA can deliver higher memory performance. Heterogeneous applications with a mix of compute- and memory-bound kernels can now allocate/assign a greater number of CPUs for compute kernels to achieve higher overall performance. Single-threaded, memory-bandwidth-bound applications are also accelerated. We can view this in terms of reducing the effects of Amdahl’s law because a single CPU cannot fully saturate bandwidth, but Intel DSA can be used in such scenarios and reduce the time spent in sequential parts of a workload.