
The Algorithmic Adjoint Differentiation Compiler (AADC) stands at the forefront of computational optimization. It was originally designed for use with C++ because of its efficiency in handling computationally intensive tasks, but today it accelerates a wide range of applications beyond its initial focus, extending into simulations and inference tasks that require high-performance computing. Using operator overloading to effectively extract directed acyclic graphs (DAG), AADC excels in environments where computational graphs comprise a vast number of nodes. This distinguishes it from typical machine learning (ML) or deep neural network frameworks, which are geared towards handling dense tensor operations. AADC, in contrast, specializes in rapidly compiling extremely large computational graphs primarily composed of scalar operations, making it an essential tool for domains requiring the swift processing of complex, high-volume computations.
The landscape of computational tools, especially in Python*, has been predominantly shaped by the needs of ML and deep learning (DL) applications. These applications are centered around frameworks that excel in managing tensor operations. Prominent examples include TensorFlow* and PyTorch*, which are designed to handle neural network computations. However, these frameworks have inherent limitations when applied outside their primary domain. One limitation is the requirement for these frameworks to store the full DAG in memory.
In many computational tasks, especially those involving simulations and adjoint differentiation techniques in finance, the ability to quickly compile large graphs directly impacts performance. Just-in-Time (JIT) compilation becomes crucial in these contexts. However, the benefits of JIT can only be fully realized if the compilation is fast. Slow compilation can negate the runtime performance gains that JIT is supposed to provide.
AADC Architecture
AADC is designed to meet the demanding needs of high-performance computational tasks by implementing a streaming graph compiler framework. This innovative architecture functions by dynamically generating x64 AVX2/AVX512 machine code instructions as the user program executes. This mechanism not only compiles a vectorized kernel to replicate user function from input to output, but also manages the adjoint or backward propagation. Such capabilities allow AADC to maintain a small memory footprint while achieving high performance. This is shown diagrammatically in Figure 1.
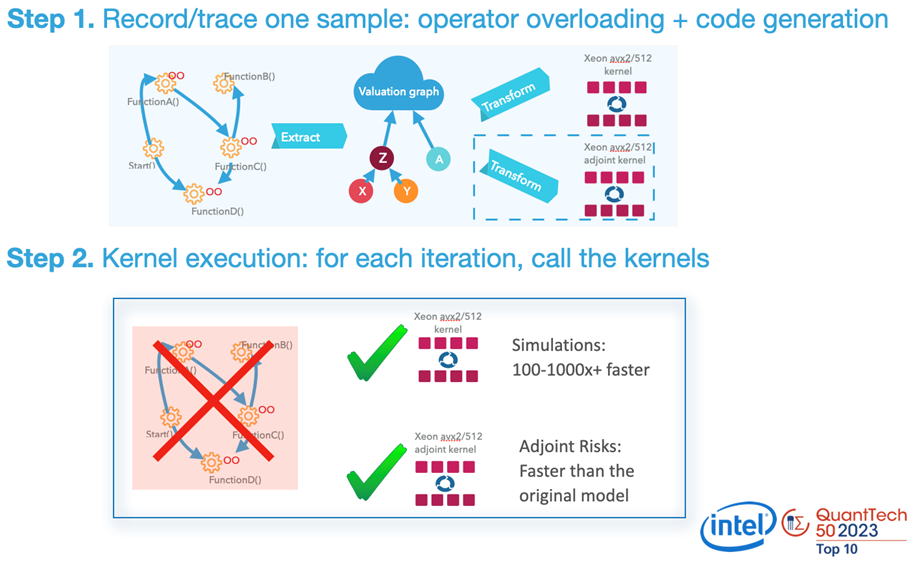
Figure 1. AADC explained
At the core of AADC's design is its ability to directly trace the elementary operations and recompile them into machine-level instructions as part of the program’s runtime. This process eliminates the inefficiencies typically associated with higher-level programming languages. By directly translating operations into x64 machine code, AADC can execute computational tasks with the utmost efficiency, leveraging modern processor capabilities like multithreading, AVX2, or AVX512.
A significant architectural advantage of AADC is its advanced code folding and compression techniques. Traditional automated differentiation tools often suffer from bloated memory usage because of the need to store large amounts of intermediate data. In contrast, AADC employs sophisticated algorithms to minimize the memory required to store computational graphs and intermediate results. This is achieved by intelligently folding and compressing the code, which not only reduces memory demands, but also enhances the execution speed by reducing the amount of data processed and moved during computation.
AADC employs an “active type” to trace calculations across both the C++ and Python analytics to maintain a consistent and accurate record of computational operations across different programming environments. This ensures that all calculations are captured and optimized, irrespective of their origin. Users initiate this process by triggering tracing and employing JIT compilation on a single instance of input data. This compiled DAG then serves as the kernel for processing multiple samples, thus executing at low-level machine code speed without the overhead of high-level programming constructs.
Case Study: Enhancing xVA Performance
Credit valuation adjustment (xVA) calculations are integral to managing credit risk and valuation in financial markets. These computations are notoriously resource-intensive, demanding robust simulation and pricing models to accurately assess risk and value. In this demonstration, we show the enhanced performance achieved by integrating the MatLogica AADC into a xVA simulation framework. The xVA computation in question uses a combination of Python and C++, where Python serves as the orchestration layer, connecting the simulation model to pricing functions using the QuantLib library as the backend.
The original Python code, while functionally comprehensive, lacks the ability to use vector or multicore execution. As a result, the performance is suboptimal, taking approximately 35 seconds to complete a single run of valuation without any risk calculations. This is impractical for scenarios requiring rapid recalculations or large-scale simulations. By incorporating AADC, the same computational tasks are transformed significantly. AADC extracts a DAG for a single Monte Carlo path from the existing Python and C++ code and forms a kernel that takes advantage of AVX2/AVX512 and multithreading.
With AADC, the execution time for the xVA simulation is dramatically reduced from 35 seconds to just one second on a single CPU core, including not just the valuation but also all first-order risk sensitivities. For comparison, see the xVA-QL-Original vs. the xVA-QL-Example Jupyter* notebooks.
The use of AVX512 instructions and multithreading offers additional performance benefits. When these features are activated, the simulations exhibit even greater efficiency (Figure 2). These enhancements are crucial in a financial context where speed and accuracy directly influence decision-making and financial outcomes.
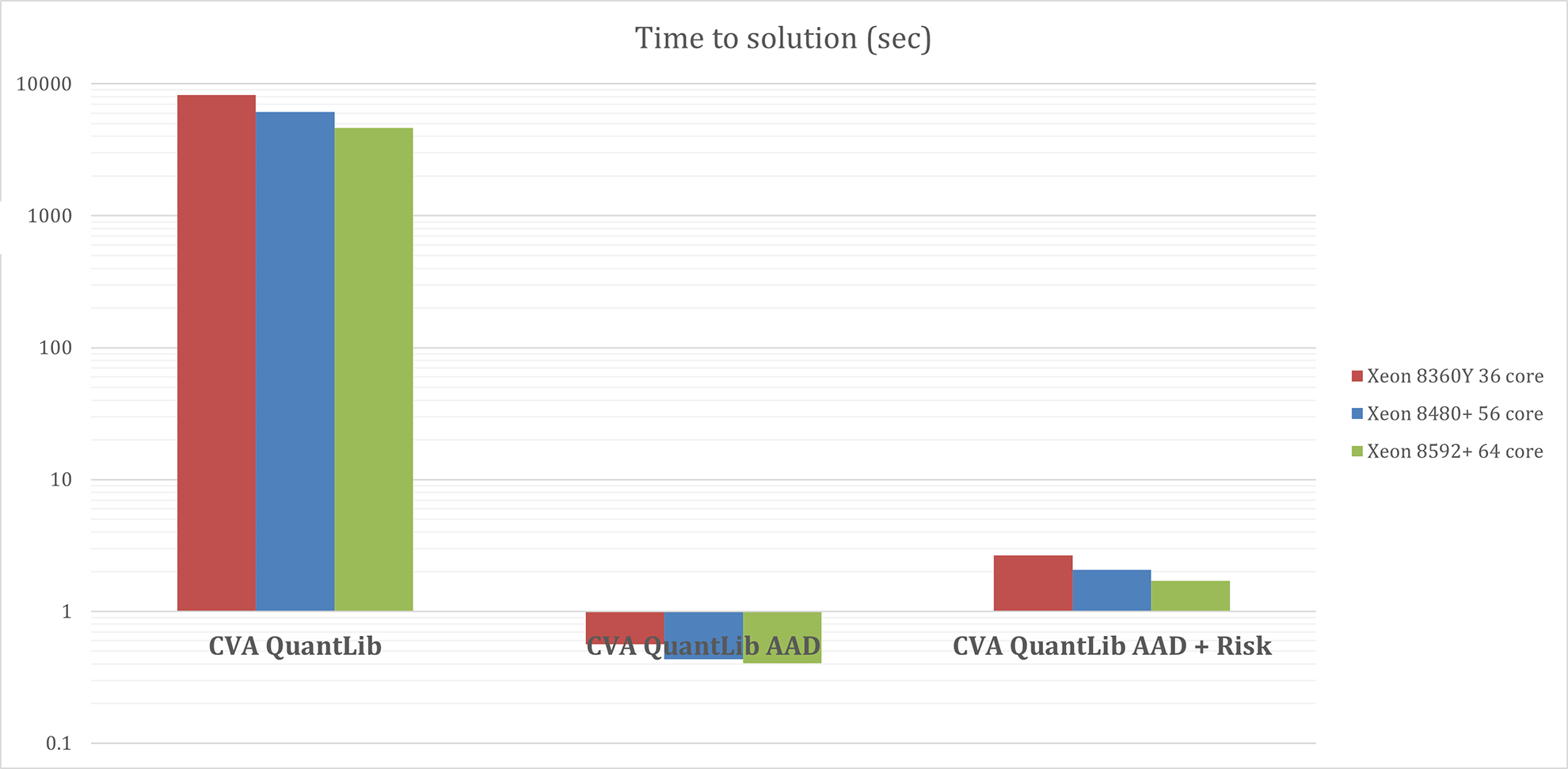
Figure 2. Performance improvements
Instrumentation of C++ Libraries
One primary technical requirement for utilizing AADC is the instrumentation of the underlying C++ library to use the “active” idouble type, which is essential to trace user program and extract DAG. Although this can typically be achieved with a simple search-and-replace operation, it often leads to annoying C++ compilation errors. These errors, while manageable, can pose initial hurdles that need to be addressed to ensure smooth integration and operation. To facilitate this process, AADC includes an LLVM*/Clang-based tool designed to perform the necessary fixes automatically. This tool helps streamline the modification process, reducing the manual effort required and minimizing the potential for error during the instrumentation phase.
Handling of Branching in Code
For AADC's recording/replaying pattern to function correctly, it is imperative that no branching in the code is missed. This is because missed branches can lead to inconsistencies in the recorded computations, limiting the ability to apply the recorded execution for arbitrary inputs. While this setup works for linear problems out of the box, it can be more challenging for algorithms involving conditional statements.
In practice, statements like if (x < K) return 0; else return (x-K); need to be transformed into max(0, x-K) to eliminate conditional branching. AADC facilitates the tracking of all missed branches, and if the recording is devoid of missed branches, it is considered consistent and can be safely used for arbitrary inputs. Furthermore, AADC is equipped to pinpoint the exact location of required modifications in the user's code, aiding developers in optimizing their code for better compatibility with the compiler.
Compatibility with QuantLib and Other Libraries
In our demonstration using the open source QuantLib library, modifications were necessary to make it compatible with AADC's recording requirements. However, not all instrument types within QuantLib are currently supported, indicating a limitation in the range of direct applicability of AADC without prior modification. This limitation underscores the ongoing need for more analytics to be converted into a format that is compatible with fully differentiable code.
Conclusion
This use case vividly illustrates how AADC can transform computational finance tasks by leveraging vectorization and efficient compilation techniques as well as the adjoint differentiation method. The dramatic reduction in execution time, coupled with the ability to perform more complex analyses swiftly, positions AADC as a crucial tool in the arsenal of financial institutions and quantitative analysts (Figure 3). This practical demonstration not only highlights the capabilities of AADC but also underscores its potential to redefine performance benchmarks in computational finance and beyond.

Figure 3. From technical aspects to business benefits