High-Performance AI Applications for Everyone
Our latest development cycle focuses on making it even easier for software developers to efficiently bring high-performance AI applications into production with faster time-to-solution, increased choice, and reliability.
A broad spectrum of software development product updates this summer ensures that you can find highly performant tools and solutions for your multiarchitecture and AI development acceleration needs, enabling a fast path to production-readiness..
Releases of Intel® AI Tools, Intel® oneAPI Base Toolkit, and Intel® HPC Toolkit 2024.2 Now Available!
This includes faster LLM inference throughput and scalability across models. It also includes PyTorch* 2.4 support for Intel® Data Center GPU with SCYL* and, of course, readiness of our AI and software development solutions for the next generation of AI PCs powered by Intel® Core™ Processors (code-named Lunar Lake) with integrated Intel® Xe2 GPU and analytics.
We introduce broad tools support for workload acceleration on Intel® Xeon® 6 processors with E-cores and P-cores and the next generation of Intel® Xeon® Scalable Processors.
How does this help make your software development efforts easier and more productive?
Let's take a closer look at the details:

Figure 1: Intel® Software Development Tools
Quickly Deploy Fast Responsive AI
Significant updates were made to the rich and optimized solutions for PyTorch* and TensorFlow* users and the underlying tooling and libraries:
- PyTorch* Optimizations from Intel broaden platform support with Intel Xeon 6 optimizations, FP16 optimizations in eager mode, and PTQ dynamic quantization in the Torchinductor on Intel CPUs. On GPU, GenAI LLMs are now optimized for INT4, and transformer engines support FP8.
- PyTorch* 2.4 added initial support for Intel® Data Center GPU Max series, accelerating AI workloads and taking advantage of the SYCL software stack and the Unified Acceleration Foundation’s (UXL) multivendor software ecosystem.
Build environment configuration details can be found here: PyTorch Prerequisites for Intel GPUs
- Productivity and functionality using the Intel® Distribution for Python have been expanded with new sorting and summing functions (for example, dpt.searchsorted, dpt.cumulative_sum, dpt.cumulatove_prod, dpt.cumulative_logsumexp) along with updated documentation and bug fixes in the Data Parallel Control Library. The Data Parallel Extension for NumPy added a new family of cumulative functions (such as cumsum and cumprod) and improved linear algebra functions.
- TensorFlow* Optimizations from Intel are compatible with TensorFlow 2.15.
- Performance and memory footprint efficiency are central to our Intel® Neural Compressor updates. That said, this tool has taken big steps forward.
- More than 15 LLM models using INT8 and INT4 data types, along with quantization recipes, benefit from advanced performance tuning. Weight-only quantization algorithms allow you to take full advantage of these tuned LLM models while maintaining high model accuracy. Combining this with in-place mode additionally limits the memory footprint for higher model accuracy implementations.
- Pruning capabilities boosting AI inference benefit from SNIP being enabled leveraging DeepSpeed* ZeRO-3 and Wanda* and DSNOT pruning algorithms added for PyTorch LLM.
- Intel Neural Compressor now supports TensorFlow 2.15, PyTorch 2.2, and QNNXRT* 1.17
We make it easier for developers, researchers, analysts, and anyone who needs cost-efficient access to compute resources to scale their AI workloads with the Intel® Tiber™ Developer Cloud’s increased compute capacity, additional U.S. regions, and new state-of-the-art platform availability.
However, it is not only about frameworks and models. The libraries that these components benefit from have also seen significant updates.
- Intel® oneAPI Collective Communications Library (oneCCL) improvements target system resource utilization, such as memory and I/O.
- The Intel® oneAPI Data Analytics Library (oneDAL) expands sparse gemm and gemv primitive availability and includes sparsity support for the logloss function primitive.
- Deep Learning (DL) and Gen AI/RAG workflows using Intel-optimized frameworks on the latest Intel Xeon platforms benefit from the Intel® oneAPI Deep Neural Network Library (oneDNN) and its efficiency boost with int8 and int4 weight decompression in matmul accelerating LLMs with compressed weights for faster insights and results. In addition, oneDNN is ready to accelerate execution on the next generation Intel Core Ultra processors and Intel Xeon processors.
Download the latest AI Tools 2024.2 using the AI Tools Selector.
More Choice and Freedom
AI, non-AI, and mixed application development in high performance, cloud, and edge computing is aided, and sped up with the rich set of Intel Software Development Tools powered by oneAPI. oneAPI is designed as an open software platform. It delivers both accelerated application performance and enhanced developer productivity in a multiarchitecture environment. It prevents vendor lock-in with easy code reuse and portability across diverse current and future architectures. This makes it a core ingredient of the Unified Acceleration Foundation* (UXL), a cross-industry group committed to delivering an open-standard accelerator programming model that simplifies the development of performant, cross-platform applications.
Streamlining the migration of existing CUDA* code to an open source multiarchitecture multivendor C++ with SYCL GPU offload model, the Intel® DPC++ Compatibility Tool and its GitHub published counterpart SYCLomatic, add 126 new CUDA library APIs that are automatically translated to oneAPI equivalent spec element calls. Visual AI and imaging apps using bindless textures can be accelerated on multivendor GPUs with SYCL image API extension.
To accelerate not only the migration itself but also the verification of migration result correctness, we add auto-compare and report creation of kernel runtime logs. CodePin instrumentation ensures the functional correctness of migrated code and allows seamless integration of functional testing into the porting process as part of continuous integration and development (CI/CD).
Updated documentation, the ability to migrate CMAKE build environments to SYCL, and the user-defined reconfigurability of migration rules for library APIs make the move to SYCL straightforward and manageable even for complex projects.
Built on Open Standards
We wholeheartedly embrace the principles of open source and open standards based software development. We know that open standards, with open governance, are highly valuable in helping make your coding investment portable, performance portable, and free of vendor lock-in. Standard parallelism is best when supported by an open ecosystem. We have been active contributors to the GNU*, OpenMP*, OpenCL*, LLVM*, SPIRV*, MLIR*, SYCL*, and oneAPI community with frequent feature proposals and implementation recommendations over the years.
This is also reflected in this latest release of the Intel® oneAPI DPC++/C++ Compiler, the world’s first SYCL 2020 conformant compiler:
- You can accelerate and coordinate offload of many small parallel kernels even more efficiently using SYCL Graph, now featuring pause/resume support for better control and graph profiling to tune for more performance.
- Applications that frequently create and destroy device queues for offload run faster because they don’t have to pay the overhead cost of instantiating a new context each time with reusable default SYCL device queue context, on Linux* and Windows*.
- The kernel_compiler extension introduces SPIR-V support and OpenCL* query support, allowing for greater flexibility and optimization in your compute kernels.
Our ongoing and consistent contributions to the open software developer ecosystem are widely recognized:
"We appreciate the combination of full support of SYCL with the fact that all is built upon the LLVM software stack. Probably the most important feature for us is the fact that the compiler allows us to seamlessly switch from SYCL to OpenMP and back, so we can compare GPU offloading paradigms, techniques, and their efficiency."
– Professor Tobias Weinzierl, Durham University
"The motto of GROMACS is 'Fast, Flexible, Free'—values that align with those of the SYCL standard. Starting in 2020, GROMACS began to utilize SYCL as a performance-portability back end, leveraging select features of SYCL 2020 even before its official standardization. Compared to its predecessor, SYCL 1.2, the SYCL 2020 standard introduces several new features that are instrumental in enhancing both application performance and developer productivity. The achievement of Intel oneAPI DPC++/C++ Compiler in attaining certification as the first fully conformant SYCL 2020 toolchain marks a significant milestone for the widespread adoption of open standards in heterogeneous parallelization within high-performance computing."
– Andrey Alekseenko, lead researcher, KTH Royal Institute of Technology
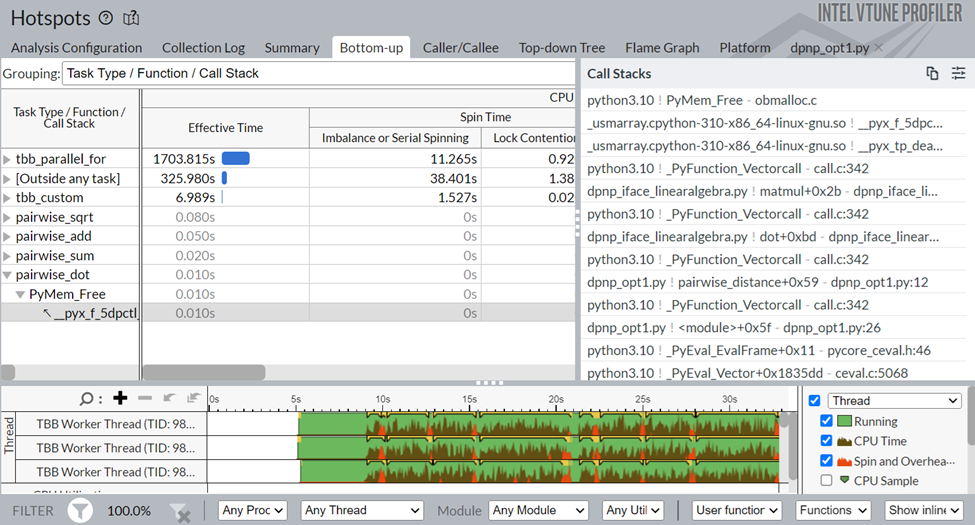
Using the Intel® Instrumentation and Tracing Technology (ITT) API for Python, the Intel VTune Profiler now enables focused analysis of highly data-parallel AI applications, making it easy and accessible to identify and fix bottlenecks in PyTorch, NumPy, and Numba workloads. Learn more on how to leverage the ITT API for performance profiling in the following article.
For distributed AI applications, the Intel® VTune™ Profiler offers insights into Intel® oneAPI Collective Communications Library (oneCCL) communication by identifying the most active communication tasks and measuring the time spent in specific oneCCL calls.
Take AI to the Next Level
The sum of all these added and enhanced capabilities in the Intel® oneAPI Base Toolkit 2024.2, the Intel® HPC Toolkit 2024.2, and the AI Tools 2024.2 allows developers to more easily deliver high-performance AI applications in production with faster time-to-solution, increased choice, and improved reliability. This applies to current and upcoming Intel® Core™ Ultra processors, Intel® Xeon® Processors, CPUs, GPUs, and distributed compute clusters.
Get ready, check it out, and join us on the journey to open multiarchitecture parallel computing and AI everywhere!
Download the Tools
The 2024.2 releases of our Software Development Tools are available for download here:
- AI Tools Selector - Achieve End-to-End Performance for AI Workloads, Powered by oneAPI
- Intel® oneAPI Base Toolkit - Multiarchitecture C++ and Python* Developer Tools for
Open Accelerated Computing - Intel® HPC Toolkit - Deliver Fast Applications That Scale across Clusters
Additional Resources
oneAPI
- oneAPI: Develop and Scale Your Code with Confidence
- What is oneAPI: Demystifying oneAPI for Developers
- AI Everywhere: 2024.2 Intel® Software Development & AI Tools Are Here
- SYCL Runtime Compilation with the kernel_compiler Extension
- Verify your CUDA* to SYCL* Migration Using CodePin
- Customize Moving Your CUDA* Code to SYCL* with User-Defined Migration Rules
- Easily Migrate CMake Scripts from CUDA* to SYCL*