Managing Offload Resource Competition and Latency
Machine learning (ML) and deep learning programs frequently consist of a sequence of many small offload kernels. Offload latency overhead can thus easily dominate the execution time of these and similar workloads. To improve performance for such applications, SYCL* Graph was released as an experimental feature in the Intel® oneAPI Base Toolkit 2024.0.
This short article demonstrates the core advantages of using SYCL Graph and introduces its API.
SYCL and Command Graphs
SYCL naturally supports graph execution of SYCL kernels. For example, if a developer uses memory buffers and accessors for data copy between devices, specifying access modes and memory types, a directed acyclic dependency graph (DAG) of kernels is built implicitly at runtime. That graph will then determine the execution flow of the kernels.
So, what is a SYCL Graph, exactly? What is the difference between it and the regular execution of SYCL kernels?
A lot of applications contain many small kernels, whose duration of execution on the device could be comparable to or smaller than the launching cost, typically in the scale of “µs.” This is especially true in the artificial intelligence (AI) domain, where small kernels must be run repeatedly during the training process. In such a scenario, if the launching overhead or latency are not properly managed, they can be easily exposed and add to the total running time.
The motivation behind SYCL Graph is to solve this problem. It is currently an experimental feature, available as part of the Intel® oneAPI DPC++/C++ Compiler since version 2024.0. SYCL Graph is defined as a directed and acyclic graph of commands (nodes) and their dependencies (edges) and is represented by the command_graph class. It does not change the functionality of the code. Its sole purpose is to improve the performance of repeatedly executed commands.
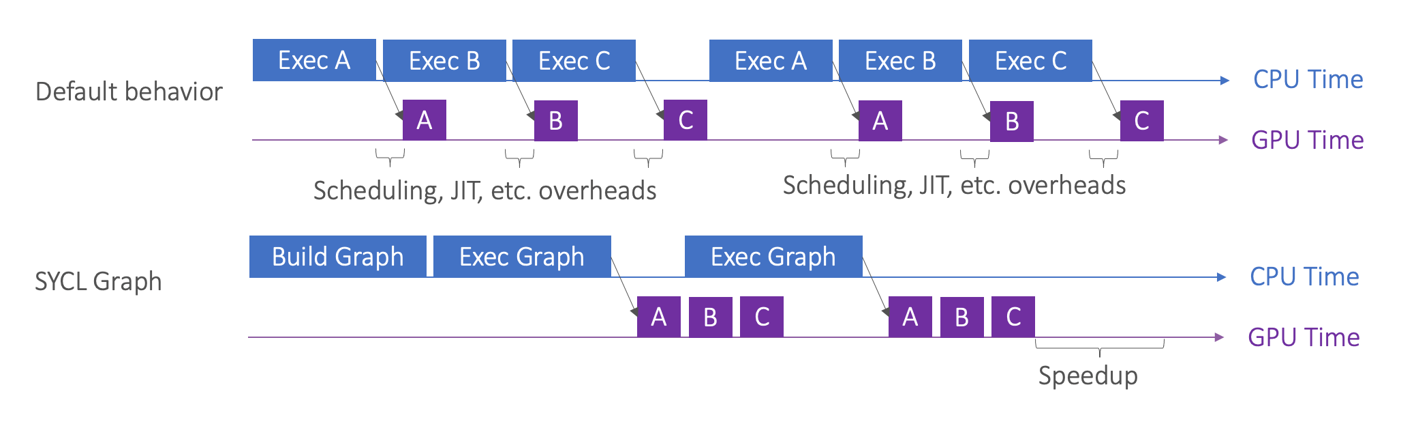
Figure 1: SYCL Graph reduces overhead during kernel launching
The Benefits of SYCL Graph
- SYCL Graph reduces launch overhead. As shown in Figure 1, for short kernels with execution time shorter than the host launch duration, the host launch overhead dominates the total running time. If SYCL Graph is used, the accumulative cost of launching multiple kernels will be replaced by a one-time cost of launching the graph.
- SYCL Graph enables more work to be done ahead of time. This is especially significant if Just-In-Time (JIT) compilation is used. The bulk of the compilation can be performed only once during the “Build Graph” stage instead of every time during the kernel launching. Note that the JIT compilation overhead can also be reduced by kernel caching, but the SYCL runtime manages that, and that approach is thus out of the control of developers.
- SYCL Graph exposes and enables additional optimization opportunities:
- kernel fusion/fission,
- inter-node memory reuse from data staying resident on the device,
- identification of the peak intermediate output memory requirement for more optimal memory allocation.
SYCL Graph API Primer
A SYCL Graph can be declared using a SYCL queue or SYCL context and device:
namespace sycl_ext = sycl::ext::oneapi::experimental;
sycl::queue q;
sycl_ext::command_graph graph {q};
This experimental Intel extension to the SYCL Specification provides two ways to construct a SYCL graph: explicit graph building and queue recording.
1. Explicit Graph Building
For example, to add a memcpy operation and a SYCL kernel to the graph:
auto memcpy_node = graph.add([&](sycl::handler& h){
h.memcpy( … );
});
auto kernel_node = graph.add([&](sycl::handler &h){
h.parallel_for( … , [=](sycl::item<1> item) { … });
});
When the queue is constructed manually, this extension also provides an additional mechanism to establish the edge between nodes,
i.e. sycl_ext::property::node::depends_on( … );
For example, if we want to create an edge between the 2 nodes, we can add this property to the 2nd node,
auto kernel_node = graph.add([&](sycl::handler &h){
h.parallel_for( … , [=](sycl::item<1> item) { … });
}, sycl_ext::property::node::depends_on(memcpy_node));
The same edge can also be built via,
graph.make_edge(memcpy_node, kernel_node);
2. Queue Recording
For example, to add the same kernels to a graph via queue recording can be done as follows:
graph.begin_recording(q);
q.memcpy( … );
q.submit([&](sycl::handler &h) {
h.parallel_for( … , [=](sycl::item<1> item) { … });
});
graph.end_recording(q);
The edge between nodes in the recording mode will be determined exactly the same way as for regular SYCL code without a graph. For example, the same dependencies can be specified via,
sycl::handler::depends_on( sycl::event e );
, or determined by the runtime if the buffer/accessor memory model is used, or if the recording queue is an in-order queue.
It is worth noting that the recording queue should share the same SYCL context and SYCL device used on creation of the graph.
Once the graph is constructed, it needs to be finalized so that it can be submitted to and executed on a SYCL queue. The execution queue should also share the same SYCL context and SYCL device used to create the graph.
auto execGraph = graph.finalize();
q.ext_oneapi_graph(execGraph);
Detailed Usage Example
This section illustrates the main advantages of SYCL Graph via a simplified example.
Here is the test function to be used:
void test(sycl::queue &q, float* dst, float* src, int count, int wgSize, int nker)
{
for(int i=0;i<nker;i++)
q.submit([&](sycl::handler &h) {
h.parallel_for(sycl::nd_range<1>{count, wgSize},
[=](sycl::nd_item<1> item) {
int idx = item.get_global_id(0);
dst[idx] = src[idx] * 2;
});
});
}
The kernel simply multiplies each entry of array “src” with 2 and puts the results in array “dst”. Here “count” is the length of array “dst” and “src”, and “wgSize” is the size of the workgroup. In this test function, the kernel is launched “nker” times to an in-order SYCL queue, such that the kernels will be executed serially.
std::chrono is used to time the code, and a helper timer class is defined as below:
class Timer {
public:
Timer() : start_(std::chrono::steady_clock::now()) {}
double Elapsed() {
auto now = std::chrono::steady_clock::now();
return std::chrono::duration_cast<std::chrono::nanoseconds>(now - start_).count()*1.0e-3; //in micro-seconds
}
private:
std::chrono::steady_clock::time_point start_;
};
double ts, te;
Timer tim;
The baseline is set by running the test function multiple times. A synchronization with host is added after each call to the test function, so each call is timed separately.
sycl::queue q{sycl::gpu_selector_v, {sycl::property::queue::in_order()}};
for(int i=0;i<nrun;i++){
ts = tim.Elapsed();
test(q, dst, src, count, wgSize, nker);
q.wait();
te = tim.Elapsed();
std::cout<<"Run w/o graph : "<<te - ts<<" us\n";
}
To test the performance of the SYCL graph, the test function is first recorded into a graph, and then the graph is executed multiple times. A similar synchronization with host is added each time the graph is executed.
sycl_ext::command_graph graph {q};
graph.begin_recording(q);
test(q, dst, src, count, wgSize, nker);
graph.end_recording(q);
auto execGraph = graph.finalize();
sycl::queue qexec{q.get_context(), q.get_device(), { sycl::ext::intel::property::queue::no_immediate_command_list()}};
for(int i=0;i<nrun;i++){
ts = tim.Elapsed();
qexec.ext_oneapi_graph(execGraph);
qexec.wait();
te = tim.Elapsed();
std::cout<<"Run w graph : "<<te - ts<<" us\n";
}
Note that the SYCL queue that executes the graph is supplied with a property “no_immediate_command_list”.
Note: Command list is a Level-zero (L0) concept. On Intel GPUs, L0 is used as the low-level SYCL runtime backend. If you are interested in additional details, you can find more information here.
Note: As of Intel oneAPI DPC++/C++ Compiler 2024.0, the SYCL queue that executes SYCL Graphs doesn’t support immediate command lists. This restriction only applies to Intel discrete GPUs that support immediate command lists and may not apply to future generations of Intel GPUs.
The code is compiled as a regular SYCL code using Intel DPC++ compiler with “-fsycl” option. Finally, the following is typical output:
Run w/o graph : 45665.5 us
Run w/o graph : 322.212 us
Run w/o graph : 141.267 us
Run w/o graph : 141.715 us
Run w/o graph : 140.381 us
…
Run w graph : 294.324 us
Run w graph : 121.397 us
Run w graph : 119.715 us
Run w graph : 117.274 us
Run w graph : 117.361 us
…
As we can see from the performance data, the first run without SYCL Graph takes significantly more time than the other runs, as many one-time operations are happening in this iteration. The most expensive one would be the JIT compilation process.
A similar effect is also seen in the first run with SYCL Graph. However, even the first run takes a lot less time, as many of the one-time operations have been consolidated and performed during the finalize() call. For the following runs, the duration with the SYCL graph is also consistently shorter than that without the graph.
As of Intel oneAPI DPC++/C++ Compiler 2024.1, SYCL Graph is implemented to support Intel and NVIDIA GPU. Support for AMD GPU is a work in progress and will be added in future releases. The feature is currently experimental and constantly evolving; it is not recommended to use this feature in production.
More information about the feature can be found here.
Take SYCL Graph Performance for a Spin
You can download the Intel oneAPI DPC++/C++ Compiler on Intel’s oneAPI Developer Tools product page.
This version is also in the Intel® oneAPI Base Toolkit, which includes an advanced set of foundational tools, libraries, and analysis, debug and code migration tools.
We are looking forward to your feedback and feature requests!
Additional Resources
- SYCL Graphs overview from Codeplay
- Intel Development Tools 2024.1 Feature Update Overview
- Learn C++ with SYCL* in an Hour [1:01:37]
- Reinders, James et al., Data Parallel C++: Programming Accelerated Systems Using C++ and SYCL , 2nd Edition. Springer Apress, 2023
Notices and Disclaimers
Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex. Results may vary.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates.
Intel optimizations, for Intel compilers or other products, may not optimize to the same degree for non-Intel products.
No product or component can be absolutely secure. Your costs and results may vary.
Intel technologies may require enabled hardware, software or service activation.
Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.
© Intel Corporation. Intel, the Intel logo, Xeon, Arc and other Intel marks are trademarks of Intel Corporation or its subsidiaries.
*Other names and brands may be claimed as the property of others. SYCL is a trademark of the Khronos Group Inc.