June 20, 2024
What is oneAPI?
It has been a few years now, since we started promoting and championing the open standards-based oneAPI multiarchitecture programming initiative.
From the very beginning, one of the most frequently asked questions was: What really is oneAPI?
In this article, we’d like to answer that question. Let's explore its vision, components, contribution to the developer ecosystem, and why it matters to software developers together.
Designed as an open software platform, oneAPI delivers both accelerated application performance and enhanced developer productivity in a multiarchitecture environment.
It prevents vendor lock-in and allows for easy code reuse and portability across diverse current and future architectures.
This overview of oneAPI’s key contributions to the developer ecosystem will highlight how and why it is the most viable approach to a community-driven Alternative to CUDA* Lock-In.
oneAPI’s Vision
oneAPI provides a comprehensive set of libraries, open source repositories, SYCL* -based C++ language extensions, and optimized reference implementations to accelerate the following goals:
- Define a common unified and open multiarchitecture multivendor software platfom.
- Ensure functional code portability and performance portability across hardware vendors and accelerator technologies, whether they are based on CPUs, GPUs, NPUs, ASICs, FPGAs, or other custom accelerators
- Maintain and nurture a comprehensive set of library APIs to cover programming domain needs across sectors and application use cases:
- industrial, transportation, aviation, health sciences, scientific research, emergency management, finance, data analytics, communications, and more.
- artificial intelligence (AI), machine learning (ML), predictive maintenance, simulation, data analytics, image processing, numerical math and equation solvers, and more.
- Provide a developer community and open forum to drive a unified API functionality an dinterfaces that meet the needs for a unified multiarchitecture software development model in this age of accelerated offload compute and wide adoption of compute offload for AI workloads across many domains.
- Encourage collaboration on oneAPI projects and compatible oneAPI implementations across the developerecosystem.

Unified Acceleration Foundation (UXL)
The oneAPI Initiative and oneAPI open source projects are a major ingredient of the Unified Acceleration (UXL) Foundation*. UXL is a cross-industry group committed to delivering an open standard accelerator software platform that simplifies the development of performant, cross-platform applications.
Hosted by the Linux Foundation's Joint Development Foundation (JDF), the Unified Acceleration Foundation brings together ecosystem participants to establish an open standard for developing applications that deliver performance across a wide range of architectures.
The UXL Foundation is the evolution of the oneAPI Initiative with the oneAPI Specification at its foundation. oneAPI, in turn, leverages SYCL* as the ISO C++ extension and abstraction layer to provide the multivendor and multiarchitecture freedom of choice at the center of oneAPIs philosophy.
It is a broad industry initiative backed by key steering committee members ARM*, Codeplay, Fujitsu*, Google Cloud*, Imagination*, Intel, Qualcomm*, Samsung*, and VMware*.
UXL Foundation and Khronos Group* on June 10, 2024, announced their collaboration on the SYCL Open Standard for C++ Programming of AI, HPC, and Safety-Critical Systems.
The direct programming model, C++ with SYCL* (pronounced “sickle”), comes from The Khronos Group. This organization provides open software standards for a variety of use cases including well-known standards OpenGL, WebGL, OpenCL™, and more. The direct programming model provides a flexible, modern C++ language that allows developers to write parallel algorithms and integrate them into existing C++ codebases. Compilers can then take this expressed parallelism and target CPUs, GPUs, FPGAs, and other hardware .
oneAPI's open source project defines a set of library interfaces that are commonly used in a variety of workflows. For example, oneAPI Math Kernel Library (oneMKL) is an open, stable API that enables users to leverage common, parallelizable, mathematical operations. The Deep Neural Network Library (oneDNN) API exposes the basic building blocks used in deep-learning applications.
As you can see below, oneAPI has a variety of library interfaces for several industry-standard workloads.
Together, oneAPI, UXL Foundation, SYCL, and Khronos Group are at the center of their common developer community-driven effort. With open, unified accelerated computing, you gain the freedom to run your code anywhere.
The oneAPI Open Source Project
oneAPI is an open source project with an open and standards-based set of well-defined interfaces, supporting multiple architecture types including but not limited to GPU, CPU, and FPGA. The low-level runtime API interface to enable this is also open and can use oneAPI’s Level Zero low-level interface or OpenCL* to communicate with hardware-specific runtime layers.
oneAPI supports both direct programming and API-based programming paradigms.
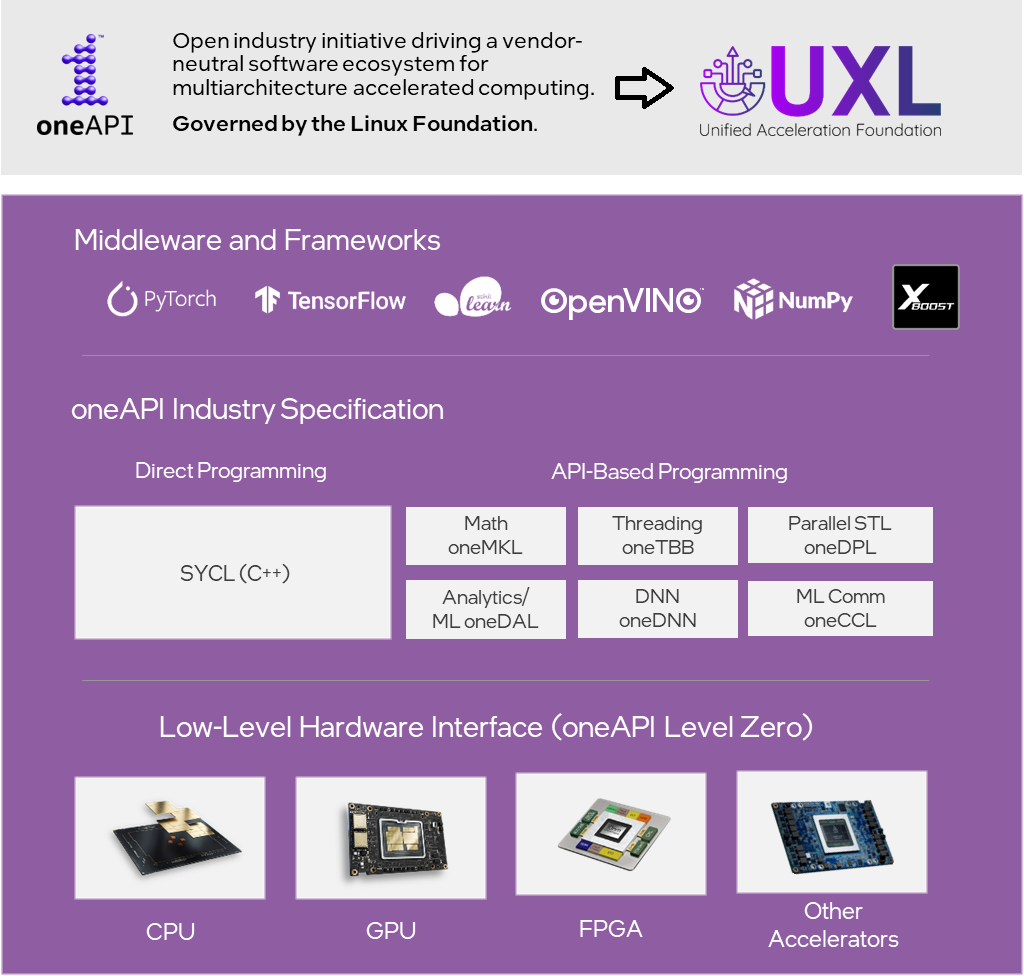
The direct programming model, C++ with SYCL* (pronounced “sickle”), comes from The Khronos Group. It provides a flexible, modern C++ language that allows developers to write parallel algorithms and integrate them into existing C++ codebases. Compilers can then take this expressed parallelism and target CPUs, GPUs, FPGAs, and other hardware.
In addition, oneAPIn defines a set of library interfaces that are commonly used in a variety of workflows:
- Level-Zero Application Programming Interface (API) direct-to-metal interfaces to offload accelerator devices.
- The oneAPI DPC++ Library (oneDPL) provides the functionality specified in the C++ standard, with extensions to support data parallelism and offloading to devices and extensions to simplify its usage for implementing data parallel algorithms.
- oneAPI Data Analytics Library (oneDAL) provides building blocks covering all stages of data analytics and AI Training: data acquisition from a data source, preprocessing, transformation, data mining, modeling, validation, and decision making.
- The oneAPI Deep Neural Network Library (oneDNN) exposes the basic building blocks used in deep-learning applications.
- The oneAPI Threading Building Blocks (oneTBB) is a hardware agnostic library for scalable parallel programming using standard ISO C++ code. A program uses oneTBB to specify logical parallelism in algorithms, while a oneTBB implementation maps that parallelism onto execution threads.
- The oneAPI Collective Communications Library (oneCCL) provides primitives for the communication patterns in deep learning applications. oneCCL supports scale-up for platforms with multiple oneAPI devices and scale-out for clusters with multiple compute nodes.
- The oneAPI Math Kernel Library (oneMKL) Interfaces Project is an open, stable API that enables users to leverage common, parallelizable mathematical operations. The functionality is subdivided into several domains: dense linear algebra, sparse linear algebra, discrete Fourier transforms, random number generators, and vector math.

Another important aspect of oneAPI is that its standards-based approach ensures it can coexist with other compute-based open standards like OpenMP*. This interoperability is important for developers taking advantage of existing parallelism who want to migrate their existing codebase into a more flexible, multiarchitecture, multivendor accelerator-based approach.
The Implementation
While having an open standard sounds great, developers need strong implementations built on top of it. Fortunately, various efforts have stepped up to meet that need.
Several compilers work with C++ with SYCL. These implementations can take C++ with SYCL code and target a variety of backends, including multivendor CPUs and GPUs.

Image courtesy of khronos.org
The API-based library specifications have open source implementations available on GitHub. They support a variety of architectures, from x86 CPUs and, in some cases, ARM* CPUs to Intel, AMD*, and NVIDIA* GPUs. The oneMKL library has had portions of the specification implemented by Codeplay to support the oneMKL Basic Linear Algebra Subprograms (BLAS) library on NVIDIA GPUs. This is, of course, an ecosystem effort and a work in progress.
With the ecosystems support multiarchitecture support evolves rapidly. Checking the progress supporting different architectures and compatibility with different vendor runtimes is very worthwhile.
CUDA to SYCL Migration
This leads us to the topic of migrating existing code and algorithms to this new, more open, and flexible way of multiarchitecture accelerator offload targeted software development.
The SYCLomatic project on GitHub is part of oneAPI, and it assists developers in migrating their existing code written in different programming languages to the SYCL* C++ heterogeneous cross-platform abstraction layer.
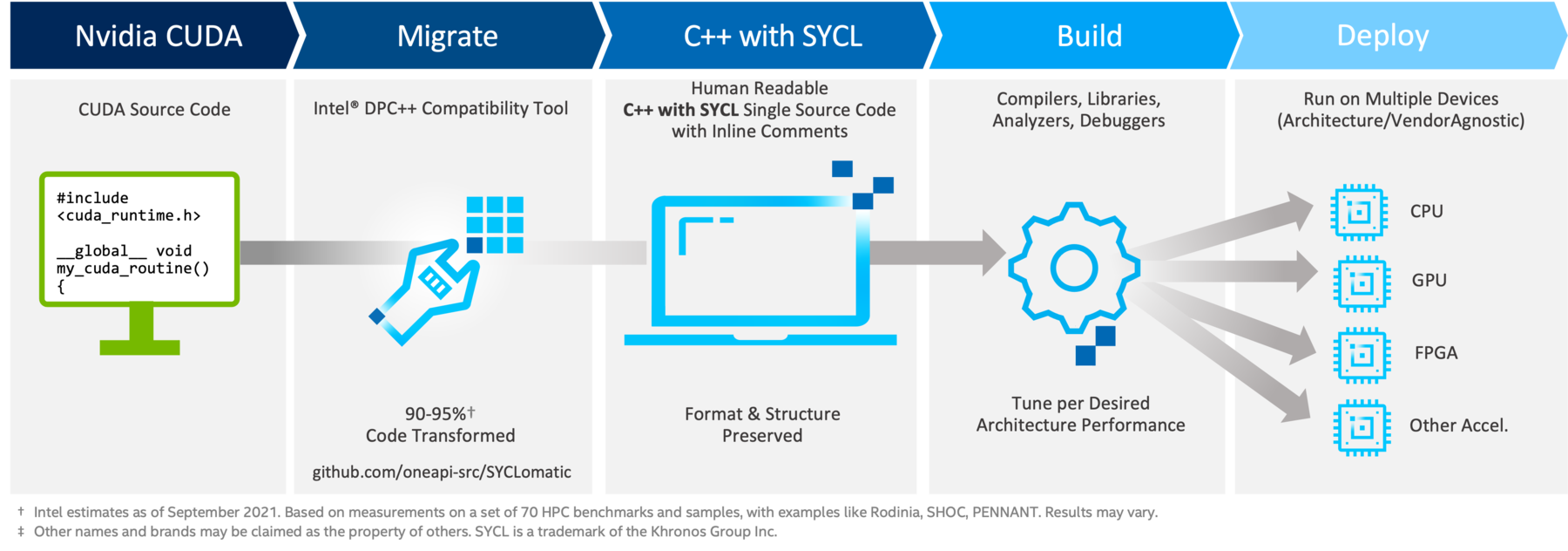
A binary distribution of SYCLomatic called the Intel® DPC++ Compatibility Tool is also available with detailed tutorials. This makes code migration a very straightforward and well-documented process, leading to a 90-95% successful port of your CUDA codebase out of the box.
There are features like:
- custom migration rule files.
- automated migration of make and cmake environments.
- verbose output file comments.
- CodePin file instrumentation for debugging and functional unit testing.
that makes it a very powerful utility adjustable to your needs.
The Community
oneAPIs and UXL's momentum and success hinge on its active developer community.
- The awesome-onapi list of oneAPI projects on GitHub provides over 80 implementation references developed by oneAPIs community members covering many different usage domains.
- The oneAPI samples repository is filled with examples of how to access and take advantage of SYCL and oneAPI libraries.
- Our partners in the research community are providing developer education, are helping to drive ongoing development and improvements and are sharing their experiences as part of the onAPI Academic Centers of Excellence.
- Innovators, Adopters, and Researchers are taking advantage of the Intel® Innovators Program for oneAPI.
- The CUDA to SYCL Catalog of Ready-to-Use Applications showcases our community partners' efforts and provides access to fully migrated application workloads just waiting for your use.
More and more simulations, applications, AI models, and frameworks are optimized using oneAPI. We are looking forward to you joining us as well.
Intel's Toolkits
Intel provides its own Intel optimized binary implementation of oneAPI—the Intel® oneAPI Toolkit.
In addition to providing oneAPI component implementations featuring the latest optimizations and support for Intel CPUs, GPUs, and NPUs, it also offers additional utilities, like Intel® VTune™ Profiler and Intel® Advisor for parallel execution performance modeling and profiling, as well as extensions for debug and Python programming.
Reflecting Intel’s strong commitment to the open standards-based software developer community, in April 2024, the LLVM* and Clang* based Intel® oneAPI DPC++/C++ Compiler became the very first compiler to achieve full SYCL 2020 standard conformance.
Dr. Tom Deakin, SYCL Working Group Chair for Khronos Group and assistant professor in Advanced Computer Systems at the University of Bristol, states:
“SYCL 2020 enables productive heterogeneous computing today, providing the necessary controls to write high-performance parallel software for the complex reality of today’s software and hardware. Intel’s commitment to supporting Open Standards is again showcased as they become a SYCL 2020 Khronos Adopter. Intel’s conformant implementation of SYCL 2020 in their latest Intel® oneAPI DPC++/C++ Compiler gives software developers the assurance they need that their code will be portable. Not only this, but Intel’s support for open standards has helped build a vibrant ecosystem of tools, libraries, and support for SYCL 2020 on CPUs, GPUs, and FPGAs.”
Hardware and Vendor Choice
oneAPI is an open source project that aims to simplify the life of developers looking to create accelerator-based applications and who want the flexibility to support a variety of hardware architectures and hardware vendors, giving them dramatically improved scalability and maintainability
As a major supporter of this effort, Intel has provided initial implementations of the specification and tooling to support developers writing oneAPI applications.
It is now a central part of the Unified Acceleration (UXL) Foundation's mission to promote an open, unified standard accelerator software platform that delivers cross-platform performance and productivity.
- Build a multi-architecture, multivendor software ecosystem for all accelerators.
- Unify the heterogeneous compute ecosystem around open standards.
- Build on and expand open-source projects for accelerated computing.
Please join us. Join oneAPI and the UXL Foundation as we usher in the future of Accelerated Compute Anywhere in Edge Computing, High Performance Computing, AI and beyond.
See Related Content
Project and Product Pages
- Unified Acceleration (UXL) Foundation
- oneAPI Initiative
- Khronos Group SYCL Project
- Intel’s oneAPI Developer Tools
CUDA to SYCL Migration
- awesome-onapi list of oneAPI projects
- oneAPI samples repository
- oneAPI Academic Centers of Excellence
- CUDA to SYCL Migration Portal
Get the Software
Download the Intel® oneAPI Base Toolkit, which includes an advanced set of foundational tools, libraries, analysis, debug and code migration tools.
You may also want to check out the oneAPI GitHub repository and our contributions to the LLVM compiler project on GitHub.