Enable Platform-Appropriate Vectorization
Enable the use of vector registers as appropriate for your platform. Then check to see if the vectorization efficiency improves.
You use the /QxHost option to compile the matrix application using the best instruction set extension that is supported by your processor. To generate multiple code paths that enable your software to run on several microarchitectures, refer to the ax, Qax option of the Intel® oneAPI DPC++/C++ Compiler.
Enable Full Vectorization
To enable the use of a vector instruction set that is appropriate for your platform, instruct the compiler to use the same vector extension as the best one that is available for your processor.
Follow these steps to enable platform-appropriate vectorization using Visual Studio*:
In the Solution Explorer pane, right-click the matrix project and select Properties.
Open the C/C++ > Code Generation [Intel C++] menu.
Set the Intel Processor-Specific Optimization option to Same as the host processor performing the compilation (/QxHost). This setting instructs the compiler to use the best instruction set extension that is available for your processor.
Save the change.
Build the application.
Check Vectorization with HPC Performance Characterization Analysis
Repeat the HPC Performance Characterization analysis to ensure that the matrix application is properly vectorized.
Once the analysis is finished, see the result in the Summary window.
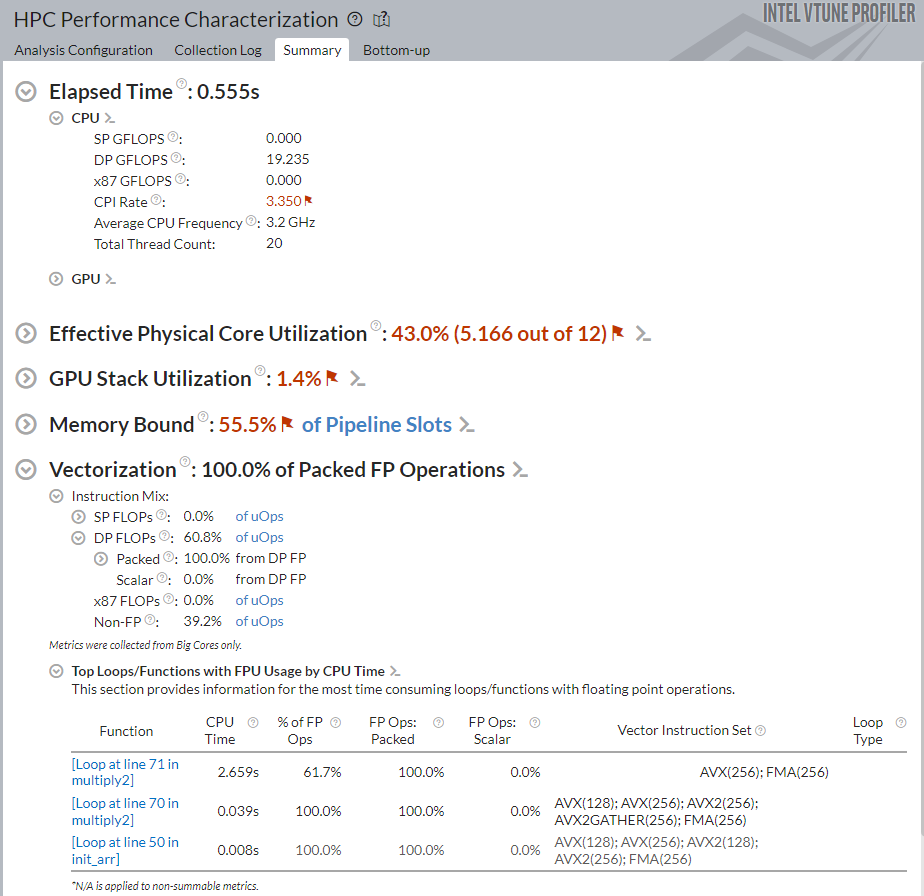
Notice that:
The Elapsed Time for the application has decreased slightly.
The Vectorization metric is 100%, so the code was fully vectorized.
100.0% of Packed DP FLOP instructions were executed using the 256-bit registers. The vector instruction set used is primarily AVX with some Fused Multiply-Add (FMA) instructions.
Although the overall speed of the application improved, some performance indicators like CPI Rate and Memory Bound worsened with the vectorization change. This is because the loop optimizations may include factors like unrolling which affects the memory access pattern. The matrix sample contains advanced techniques like cache blocking to improve this condition.
The matrix application is extremely fast. This speed makes its performance more susceptible to interference from other tasks and overhead on your system. Minor optimizations may not consistently show the performance improvement you expect. Increasing the size of the matrices can help here.
Performance optimization is an iterative process. The matrix sample contains more techniques you can consider for performance improvement.