Visible to Intel only — GUID: ewa1398441237755
Ixiasoft
1. Introduction to Intel® FPGA SDK for OpenCL™ Pro Edition Best Practices Guide
2. Reviewing Your Kernel's report.html File
3. OpenCL Kernel Design Concepts
4. OpenCL Kernel Design Best Practices
5. Profiling Your Kernel to Identify Performance Bottlenecks
6. Strategies for Improving Single Work-Item Kernel Performance
7. Strategies for Improving NDRange Kernel Data Processing Efficiency
8. Strategies for Improving Memory Access Efficiency
9. Strategies for Optimizing FPGA Area Usage
10. Strategies for Optimizing Intel® Stratix® 10 OpenCL Designs
11. Strategies for Improving Performance in Your Host Application
12. Intel® FPGA SDK for OpenCL™ Pro Edition Best Practices Guide Archives
A. Document Revision History for the Intel® FPGA SDK for OpenCL™ Pro Edition Best Practices Guide
2.1. High-Level Design Report Layout
2.2. Reviewing the Summary Report
2.3. Viewing Throughput Bottlenecks in the Design
2.4. Using Views
2.5. Analyzing Throughput
2.6. Reviewing Area Information
2.7. Optimizing an OpenCL Design Example Based on Information in the HTML Report
2.8. Accessing HLD FPGA Reports in JSON Format
4.1. Transferring Data Via Intel® FPGA SDK for OpenCL™ Channels or OpenCL Pipes
4.2. Unrolling Loops
4.3. Optimizing Floating-Point Operations
4.4. Allocating Aligned Memory
4.5. Aligning a Struct with or without Padding
4.6. Maintaining Similar Structures for Vector Type Elements
4.7. Avoiding Pointer Aliasing
4.8. Avoid Expensive Functions
4.9. Avoiding Work-Item ID-Dependent Backward Branching
5.1. Best Practices for Profiling Your Kernel
5.2. Instrumenting the Kernel Pipeline with Performance Counters (-profile)
5.3. Obtaining Profiling Data During Runtime
5.4. Reducing Area Resource Use While Profiling
5.5. Temporal Performance Collection
5.6. Performance Data Types
5.7. Interpreting the Profiling Information
5.8. Profiler Analyses of Example OpenCL Design Scenarios
5.9. Intel® FPGA Dynamic Profiler for OpenCL™ Limitations
8.1. General Guidelines on Optimizing Memory Accesses
8.2. Optimize Global Memory Accesses
8.3. Performing Kernel Computations Using Constant, Local or Private Memory
8.4. Improving Kernel Performance by Banking the Local Memory
8.5. Optimizing Accesses to Local Memory by Controlling the Memory Replication Factor
8.6. Minimizing the Memory Dependencies for Loop Pipelining
8.7. Static Memory Coalescing
Visible to Intel only — GUID: ewa1398441237755
Ixiasoft
6.1.2. Relaxing Loop-Carried Dependency
Based on the feedback from the optimization report, you can relax a loop-carried dependency by increasing the dependence distance. Increase the dependence distance by increasing the number of loop iterations that occurs between the generation of a loop-carried value and its usage.
Consider the following code example:
1 #define N 128
2
3 __kernel void unoptimized (__global float * restrict A,
4 __global float * restrict result)
5 {
6 float mul = 1.0f;
7
8 for (unsigned i = 0; i < N; i++)
9 mul *= A[i];
10
11 * result = mul;
12 }
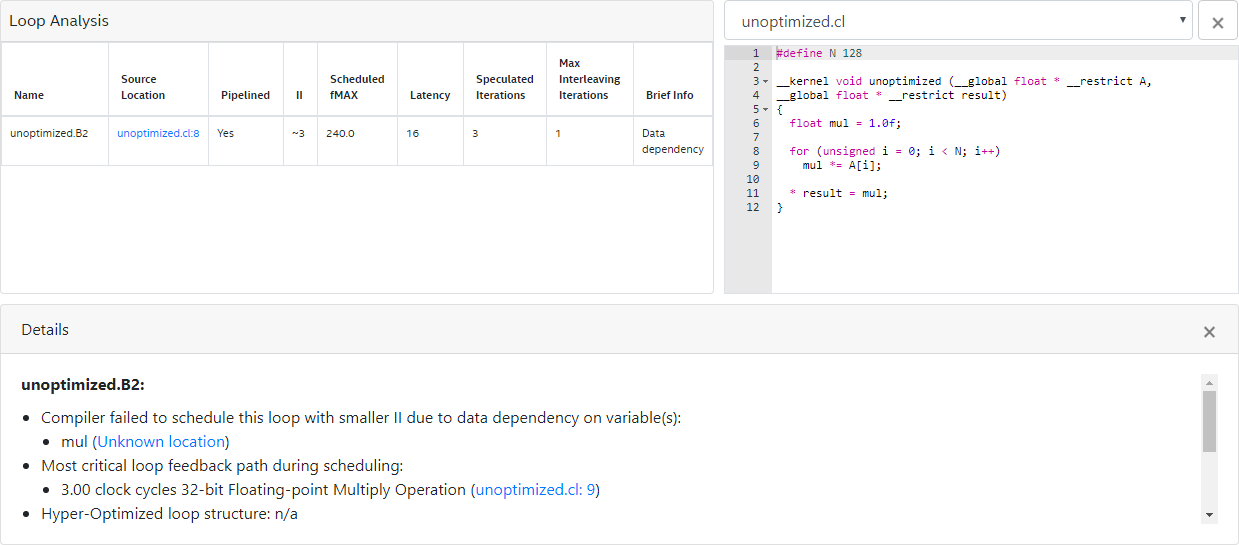
The optimization report above shows that the Intel® FPGA SDK for OpenCL™ Offline Compiler infers pipelined execution for the loop successfully. However, the loop-carried dependency on the variable mul causes loop iterations to launch every six cycles. In this case, the floating-point multiplication operation on line 9 (that is, mul *= A[i]) contributes the largest delay to the computation of the variable mul.
To relax the loop-carried data dependency, instead of using a single variable to store the multiplication results, operate on M copies of the variable and use one copy every M iterations:
- Declare multiple copies of the variable mul (for example, in an array called mul_copies).
- Initialize all the copies of mul_copies.
- Use the last copy in the array in the multiplication operation.
- Perform a shift operation to pass the last value of the array back to the beginning of the shift register.
- Reduce all the copies to mul and write the final value to result.
Below is the restructured kernel:
1 #define N 128
2 #define M 8
3
4 __kernel void optimized (__global float * restrict A,
5 __global float * restrict result)
6 {
7 float mul = 1.0f;
8
9 // Step 1: Declare multiple copies of variable mul
10 float mul_copies[M];
11
12 // Step 2: Initialize all copies
13 for (unsigned i = 0; i < M; i++)
14 mul_copies[i] = 1.0f;
15
16 for (unsigned i = 0; i < N; i++) {
17 // Step 3: Perform multiplication on the last copy
18 float cur = mul_copies[M-1] * A[i];
19
20 // Step 4a: Shift copies
21 #pragma unroll
22 for (unsigned j = M-1; j > 0; j--)
23 mul_copies[j] = mul_copies[j-1];
24
25 // Step 4b: Insert updated copy at the beginning
26 mul_copies[0] = cur;
27 }
28
29 // Step 5: Perform reduction on copies
30 #pragma unroll
31 for (unsigned i = 0; i < M; i++)
32 mul *= mul_copies[i];
33
34 * result = mul;
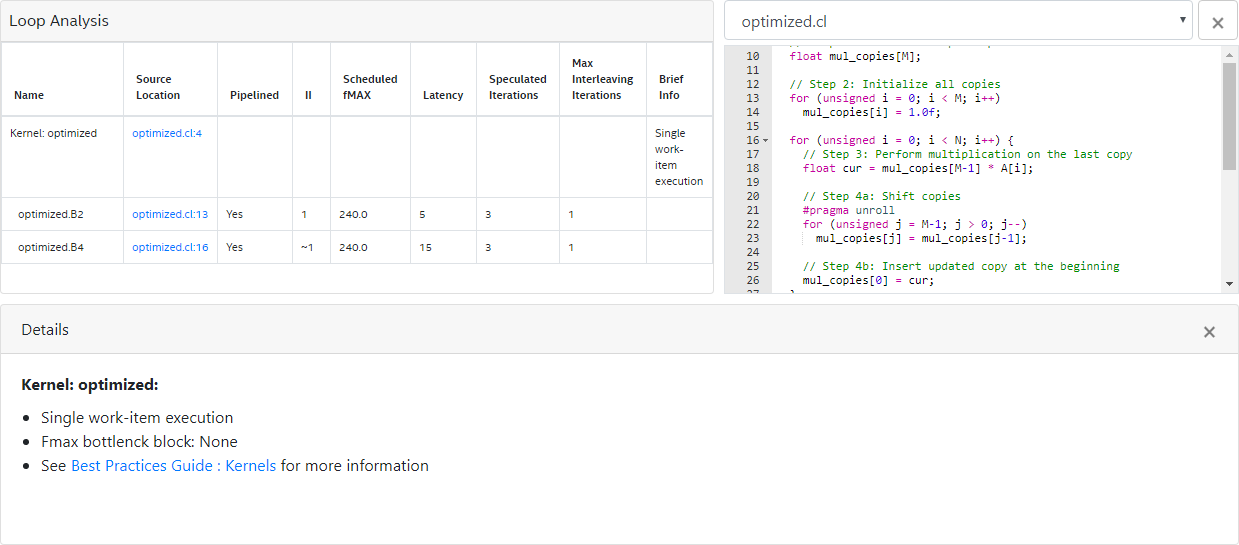
35 }An optimization report similar to the one below indicates the successful relaxation of the loop-carried dependency on the variable mul: