Visible to Intel only — GUID: chn1469549457114
Ixiasoft
1. Introduction to Intel® FPGA SDK for OpenCL™ Pro Edition Best Practices Guide
2. Reviewing Your Kernel's report.html File
3. OpenCL Kernel Design Concepts
4. OpenCL Kernel Design Best Practices
5. Profiling Your Kernel to Identify Performance Bottlenecks
6. Strategies for Improving Single Work-Item Kernel Performance
7. Strategies for Improving NDRange Kernel Data Processing Efficiency
8. Strategies for Improving Memory Access Efficiency
9. Strategies for Optimizing FPGA Area Usage
10. Strategies for Optimizing Intel® Stratix® 10 OpenCL Designs
11. Strategies for Improving Performance in Your Host Application
12. Intel® FPGA SDK for OpenCL™ Pro Edition Best Practices Guide Archives
A. Document Revision History for the Intel® FPGA SDK for OpenCL™ Pro Edition Best Practices Guide
2.1. High-Level Design Report Layout
2.2. Reviewing the Summary Report
2.3. Viewing Throughput Bottlenecks in the Design
2.4. Using Views
2.5. Analyzing Throughput
2.6. Reviewing Area Information
2.7. Optimizing an OpenCL Design Example Based on Information in the HTML Report
2.8. Accessing HLD FPGA Reports in JSON Format
4.1. Transferring Data Via Intel® FPGA SDK for OpenCL™ Channels or OpenCL Pipes
4.2. Unrolling Loops
4.3. Optimizing Floating-Point Operations
4.4. Allocating Aligned Memory
4.5. Aligning a Struct with or without Padding
4.6. Maintaining Similar Structures for Vector Type Elements
4.7. Avoiding Pointer Aliasing
4.8. Avoid Expensive Functions
4.9. Avoiding Work-Item ID-Dependent Backward Branching
5.1. Best Practices for Profiling Your Kernel
5.2. Instrumenting the Kernel Pipeline with Performance Counters (-profile)
5.3. Obtaining Profiling Data During Runtime
5.4. Reducing Area Resource Use While Profiling
5.5. Temporal Performance Collection
5.6. Performance Data Types
5.7. Interpreting the Profiling Information
5.8. Profiler Analyses of Example OpenCL Design Scenarios
5.9. Intel® FPGA Dynamic Profiler for OpenCL™ Limitations
8.1. General Guidelines on Optimizing Memory Accesses
8.2. Optimize Global Memory Accesses
8.3. Performing Kernel Computations Using Constant, Local or Private Memory
8.4. Improving Kernel Performance by Banking the Local Memory
8.5. Optimizing Accesses to Local Memory by Controlling the Memory Replication Factor
8.6. Minimizing the Memory Dependencies for Loop Pipelining
8.7. Static Memory Coalescing
Visible to Intel only — GUID: chn1469549457114
Ixiasoft
3.3. Local Memory
Local memory is a complex system. Unlike the typical GPU architecture where there are different levels of caches, FPGA implements local memory in dedicated memory blocks inside the FPGA.
Local Memory Characteristics
- Ports: Each read or write access to a local memory is mapped to a port.
- Banks: The contents of a local memory can be partitioned into one or more banks, such that each bank contains a subset of data contained in a local memory.
- Replicate: A bank consists of one or more replicates. Each replicate in a bank has the same data as the other replicates. Replicates are created to efficiently support multiple accesses to a local memory. Each replicate has one write port and one read port that your design can access simultaneously. If your local memory is double pumped, each replicate has four physical ports, of which up to three can be read ports. Refer to the Double Pumping section for more information.
- Private copies: A replicate can contain one or more private copies to allow pipelined execution of multiple workgroups. Refer to the Local Memory Banks and Private Copies section for more information.
Figure 38. Implementation of Local Memory in One or Multiple M20K Blocks
In your kernel code, declare local memory as a variable with type local:
local int lmem[1024];The Intel® FPGA SDK for OpenCL™ Offline Compiler customizes the local memory properties such as width, depth, banks, replication, number of private copies, and interconnect. The offline compiler analyzes the access pattern based on your code and then optimizes the local memory to minimize access contention.
The following diagrams illustrate these basic local memory properties (size, width, depth, banks, replication, and number of private copies):
Figure 39. Local Memory Examples Explaining Local Memory Properties
In the HTML report, the overall state of the local memory is reported as stall-free, stall-free with replication, and potentially inefficient.
The key to designing a highly efficient kernel is to have memory accesses that never stall. For a stall-free memory configuration, all possible concurrent memory access sites in the data path are guaranteed to access memory without contention.
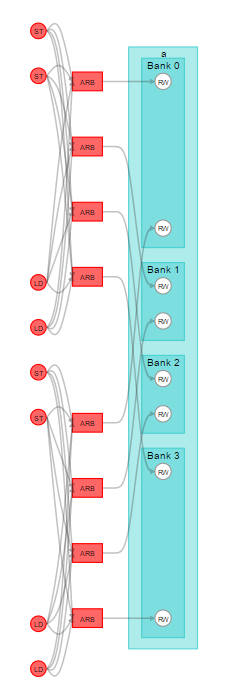
The offline compiler always attempts to find a stall-free configuration for all local memories in your kernel code. However, in a complex kernel, the offline compiler might not have enough information to infer whether a memory access has any conflict. As a result, the offline compiler infers local interconnect arbitration to arbitrate the memory access. However, inferring arbitration might cause degradation in performance. Refer to Load-Store Units for more information.
Figure 40. Complex Local Memory Systems
The offline compiler does not always implement local memory with the exact size that you specified. Since FPGA RAM blocks have specific dimensions, the offline compiler implements a local memory size that rounds up to the next supported RAM block dimension. Refer to device-specific information for more details on RAM blocks.
Local Memory Banks and Private Copies
Local memory banking works only on the lowest dimension by default. Having multiple banks allow simultaneous writes to take place. In the following code example, each local memory access in a loop has a separate address. The offline compiler can infer the access pattern to create four separate banks for lmem. Four separate banks allow four simultaneous accesses to lmem[][], which achieves the stall-free configuration. In addition, the offline compiler creates two private copies for lmem to allow pipelined execution of two simultaneous workgroups.
#define BANK_SIZE 4
__attribute__((reqd_work_group_size(8, 1, 1)))
kernel void bank_arb_consecutive_multidim (global int* restrict in,
global int* restrict out) {
local int lmem[1024][BANK_SIZE];
int gi = get_global_id(0);
int gs = get_global_size(0);
int li = get_local_id(0);
int ls = get_local_size(0);
int res = in[gi];
#pragma unroll
for (int i = 0; i < BANK_SIZE; i++) {
lmem[((li+i) & 0x7f)][i] = res + i;
res = res >> 1;
}
int rdata = 0;
barrier(CLK_GLOBAL_MEM_FENCE);
#pragma unroll
for (int i = 0; i < BANK_SIZE; i++) {
rdata ^= lmem[((li+i) & 0x7f)][i];
}
out[gi] = rdata;
return;
}The following figure illustrates the implementation (as shown in the Kernel memory Viewer) of the following local variable:
local int lmem[1024][4];
Figure 41. Implementation of lmem[1024][4]Local memory size = 32768 bytes = 2 private copies x (1024 x 4) x 4 bytes. The size of each bank is 8192 bytes.
If the number of private copies increase your design area significantly, consider reducing the number of barriers in the kernel or increasing the max_work_group_size value to reduce the inferred number of private copies.
You can specify the number of banks for your memory system by using __attribute__((numbanks(N)). For more information, refer to Improving Kernel Performance by Banking the Local Memory.
If you do not want to bank on the lowest dimension, use the bank_bits attribute to specify bits from a memory address to use as bank-select bits. By using the bank_bits attribute, you can separate memory data into multiple banks while specifying which address bits to use to select the bank. In the following example, the banking is done on seventh and eighth bits instead of the lowest two dimensions:
#define BANK_SIZE 4
kernel void bank_arb_consecutive_multidim_origin (global int* restrict in,
global int* restrict out) {
local int a[BANK_SIZE][128] __attribute__((bank_bits(8,7),bankwidth(4)));
int gi = get_global_id(0);
int li = get_local_id(0);
int res = in[gi];
#pragma unroll
for (int i = 0; i < BANK_SIZE; i++) {
a[i][((li+i) & 0x7f)] = res + i;
res = res >> 1;
}
int rdata = 0;
barrier(CLK_GLOBAL_MEM_FENCE);
#pragma unroll
for (int i = 0; i < BANK_SIZE; i++) {
rdata ^= a[i][((li+i) & 0x7f)];
}
out[gi] = rdata;
return;
}The view of the resulting memory is the same as the initial view from the first example, except that the size of the memory is now 4096 bytes = 2 private copies x (4 x 128) x 4 bytes. The Details pane of the Kernel Memory Viewer shows the address bit information, which also contains the bank_bits information.
The following figure illustrates the address bit information, as shown in the local memory report, for the following local variable declaration:
local int a[4][128] __attribute__((bank_bits(8,7),bankwidth(4)));
Figure 42. Address Bit Information for a[4][128] with Requested bank_bits(8,7)
The choice of bank-bits can alter the structure of the memory. If bank-bits (4,3) are specified in the previous example, it results in an arbitrated memory system. In this banking configuration, the local memory accesses no longer target separate banks. The compiler must build a local memory interconnect to arbitrate these accesses, which degrades performance.
local int a[4][128] __attribute__((bank_bits(4,3),bankwidth(4)));
Figure 43. Local Memory System for a[4][128] With Requested bank_bits (4,3)
Local Memory Replication
To achieve a stall-free configuration, the compiler may decide to replicate a local memory system to increase the number of available read ports. Each store operation to a local memory system is performed simultaneously on every replicate, so each replicate contains identical data. Each replicate can be independently read from. This increases the number of simultaneous read operations the local memory system can support.
Double Pumping
By default, each local memory replicate has two physical ports. The double pumping feature allows each local memory replicate to support up to four physical ports.
The underlying mechanism that enables double pumping is running the underlying M20K at double the frequency of the kernel logic. This enables two read or write operations to take place every clock cycle. From the perspective of kernel logic, a double-pumped memory has four effective physical ports.
Figure 44. Hardware Architecture of Double Pumping in Local Memory
By enabling the double pumping feature, the offline compiler trades off area versus maximum frequency.
Advantages of double pumping:
- Increases the number of available physical ports
- May reduce RAM usage by reducing replication
Disadvantages of double pumping:
- Higher logic and latency as compared to single pumped configuration
- Might reduce kernel clock frequency
You can control the pump configuration of your local memory system by using __attribute__((singlepump)) and __attribute__((doublepump)). For more information, refer to Kernel Attributes for Configuring Local and Private Memory Systems.
The following code example illustrates the implementation of local memory with three read ports and three write ports. The offline compiler enables double pumping and replicates the local memory three times to implement a stall-free memory configuration.
#define BANK_SIZE 4
kernel void bank_arb_consecutive_multidim_origin (global int* restrict in,
global int* restrict out) {
local int a[BANK_SIZE][128];
int gi = get_global_id(0);
int li = get_local_id(0);
int res = in[gi];
#pragma unroll 1
for (int i = 0; i < BANK_SIZE; i++) {
a[i][li+i] = res + i;
a[gi][li+i] = res + i;
a[gi+i][li] = res + i;
res = res >> 1;
}
int rdata = 0;
barrier(CLK_GLOBAL_MEM_FENCE);
#pragma unroll 1
for (int i = 0; i < BANK_SIZE; i++) {
rdata ^= a[i][li+i];
rdata += a[gi+i][li+i];
rdata += a[gi][li];
}
out[gi] = rdata;
return;
}The following figure illustrates the implementation (as shown in the Kernel Memory Viewer) for the following local variable declaration:
local int a[4][128];
Figure 45. Local Memory System for a[4][128] Local memory size = 6144 bytes = 3 replicates x 512 words x 4 bytes. Each replicate has identical memory contents.