Intel® FPGA SDK for OpenCL™ Pro Edition: Best Practices Guide
A newer version of this document is available. Customers should click here to go to the newest version.
10.5. Optimizing Data Path Control
The following constructs or features prevent Intel® Stratix® 10 data path optimization:
- NDRange designs with loops
- Stallable LSUs with the exception of burst-coalesced LSUs
Burst-coalesced LSUs are the default type of LSUs that the offline compiler instantiates. Example of a burst coalesced LSU instantiation:
kernel void burst_coalesced (global int * restrict in, global int * restrict out){ int i = get_global_id(0); int value = in[i/2]; //Burst-coalesced LSU out[i] = value; }You can view the LSU type of various instructions in the High Level Design Report by hovering over the load or store operation in the System Viewer. Refer to the Load-Store Units section for more information about the types of LSUs and how you can influence the compiler on which type of LSUs to instantiate.
- Channels with multiple call sites
- Stallable RTL library calls
Refer to the Create RTL Modules section for more information.
- Reconvergent control flow in the optimized control flow graph, with the exception of loops that use the new control optimization
The following pseudocode example of a simple reconvergent control flow shows that the flow of the code goes in one of two paths. The offline compiler implements different control logic for each path. It also implements logic to reconverge the control flow after the two paths are completed.
while (some_some condition){ if (some_other_condition){ for(...){ } } else{ for(...){ } } } - Loops that do not use the new loop control scheme
Refer to the Loop Control Optimization section for more information about what loops are affected by this restriction.
- Basic block structures with the exception of the following:
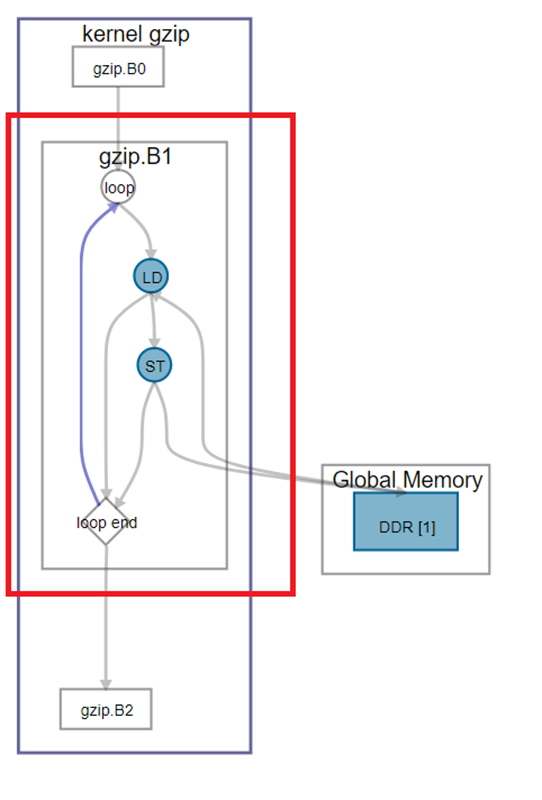
- Basic block with only one predecessor, as shown in Figure 88
- Basic block with exactly two predecessors, where one predecessor is the back-edge of a loop, as shown in Figure 89
Note: The majority of optimized designs belong to one of the two supported basic block structures. You may review images of these basic blocks in the System Viewer of the High Level Design Report.The following code example generates the two types of supported basic block structures:
__attribute__((max_global_work_dim(0))) void kernel basic_block(global unsigned int *myvar, unsigned int insize) { for(int i=0; i < insize; i++){ myvar[i] += insize; } }