A newer version of this document is available. Customers should click here to go to the newest version.
Visible to Intel only — GUID: GUID-1E38385E-36F8-48C4-B9E2-0C07A65598C5
Visible to Intel only — GUID: GUID-1E38385E-36F8-48C4-B9E2-0C07A65598C5
omatcopy_batch
Computes a group of out-of-place scaled matrix transpose or copy operations using general matrices.
Description
The omatcopy_batch routines perform a series of out-of-place scaled matrix copies or transpositions. They are similar to the omatcopy routines, but the omatcopy_batch routines perform matrix operations with a group of matrices.
omatcopy_batch supports the following precisions:
T |
|---|
float |
double |
std::complex<float> |
std::complex<double> |
omatcopy_batch (Buffer Version)
Buffer version of omatcopy_batch supports only strided API.
Strided API
The operation for the strided API is defined as:
for i = 0 … batch_size – 1 A and B are matrices at offset i * stride_a in a and i * stride_b in b B = alpha * op(A) end for
where:
op(X) is one of op(X) = X, op(X) = X', or op(X) = conjg(X')
alpha is a scalar
A and B are matrices
For the strided API, the single input buffer contains all the input matrices, and the single output buffer contains all the output matrices. The locations of the individual matrices within the buffer are given by stride lengths, while the number of matrices is given by the batch_size parameter.
Syntax
namespace oneapi::mkl::blas::column_major { void omatcopy_batch(sycl::queue &queue, transpose trans, std::int64_t m, std::int64_t n, T alpha, sycl::buffer<T, 1> &a, std::int64_t lda, std::int64_t stride_a, sycl::buffer<T, 1> &b, std::int64_t ldb, std::int64_t stride_b, std::int64_t batch_size); }
namespace oneapi::mkl::blas::row_major { void omatcopy_batch(sycl::queue &queue, transpose trans, std::int64_t m, std::int64_t n, T alpha, sycl::buffer<T, 1> &a, std::int64_t lda, std::int64_t stride_a, sycl::buffer<T, 1> &b, std::int64_t ldb, std::int64_t stride_b, std::int64_t batch_size); }
Input Parameters
- queue
-
The queue where the routine should be executed.
- trans
-
Specifies op(A), the transposition operation applied to the matrices A.
- m
-
Number of rows for each matrix A. Must be at least zero.
- n
-
Number of columns for each matrix A. Must be at least zero.
- alpha
-
Scaling factor for the matrix transposition or copy.
- a
-
Buffer holding the input matrices A. Must have size at least stride_a*batch_size.
- lda
-
Leading dimension of the A matrices. If matrices are stored using column major layout, lda must be at least m. If matrices are stored using row major layout, lda must be at least n. Must be positive.
- stride_a
-
Stride between the different A matrices. If matrices are stored using column major layout, stride_a must be at least lda*n. If matrices are stored using row major layout, stride_a must be at least lda*m.
- ldb
-
Leading dimension of the matrices B. Must be positive and satisfy:
trans = transpose::nontrans
trans = transpose::trans or trans = transpose::conjtrans
Column major
Must be at least m
Must be at least n
Row major
Must be at least n
Must be at least m
- stride_b
-
Stride between the different B matrices in the buffer b. Must be positive and satisfy:
trans = transpose::nontrans
trans = transpose::trans or trans = transpose::conjtrans
Column major
Must be at least ldb*n
Must be at least ldb*m
Row major
Must be at least ldb*m
Must be at least ldb*n
- batch_size
-
Specifies the number of matrices to transpose or copy. Must be at least zero.
Output Parameters
- b
-
Output buffer, overwritten by batch_size matrix transpose or copy operations of the form alpha*op(A). Must have size at least stride_b*batch_size.
omatcopy_batch (USM Version)
USM version of omatcopy_batch supports group API and strided API.
Group API
The type Ti of integer pointers in the group API may be either std::int64_t or std::int32_t.
The operation for the group API is defined as:
idx = 0 for i = 0 … group_count – 1 m, n, alpha, lda, ldb and group_size at position i in their respective arrays for j = 0 … group_size – 1 A and B are matrices at position idx in their respective arrays B = alpha * op(A) idx := idx + 1 end for end for
where:
op(X) is one of op(X) = X, op(X) = X', or op(X) = conjg(X')
alpha is a scalar
A and B are matrices
For the group API, the matrices are given by arrays of pointers. A and B represent matrices stored at addresses pointed to by a and b respectively. The total number of entries in a and b are given by:
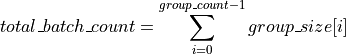
Syntax
namespace oneapi::mkl::blas::column_major { sycl::event omatcopy_batch(sycl::queue &queue, const transpose *trans, const Ti *m, const Ti *n, const T *alpha, const T **a, const Ti *lda, T **b, const Ti *ldb, std::int64_t group_count, const Ti *groupsize, const std::vector<sycl::event> &dependencies = {}); }
namespace oneapi::mkl::blas::row_major { sycl::event omatcopy_batch(sycl::queue &queue, const transpose *trans, const Ti *m, const Ti *n, const T *alpha, const T **a, const Ti *lda, T **b, const Ti *ldb, std::int64_t group_count, const Ti *groupsize, const std::vector<sycl::event> &dependencies = {}); }
Input Parameters
- queue
-
The queue where the routine should be executed.
- trans
-
Array of size group_count. Each element i in the array specifies op(A) the transposition operation applied to the matrices A.
- m
-
Array of group_count integers. m[i] specifies the number of rows of A[i]. Each entry must be at least zero.
- n
-
Array of group_count integers. n[i] specifies the number of columns of A[i]. Each entry must be at least zero.
- alpha
-
Array of size group_count containing scaling factors for the operation.
- a
-
Array of size total_batch_count of pointers to A matrices. If matrices are stored in column major layout, the array allocated for each A matrix of the group i must be of size at least lda[i] * n[i]. If matrices are stored in row major layout, the array allocated for each A matrix of the group i must be of size at least lda[i]*m[i].
- lda
-
Array of group_count integers. lda[i] specifies the leading dimension of the A[i] matrix. If matrices are stored using column major layout, lda[i] must be at least m[i]. If matrices are stored using row major layout, lda[i] must be at least n[i]. Each must be positive.
- ldb
-
Array of group_count integers. ldb[i] specifies the leading dimension of the B[i] matrix. Each ldb[i] must be positive and satisfy:
trans[i] = transpose::nontrans
trans[i] = transpose::trans or trans[i] = transpose::conjtrans
Column major
Must be at least m[i]
Must be at least n[i]
Row major
Must be at least n[i]
Must be at least m[i]
- group_count
-
Number of groups. Must be at least 0.
- group_size
-
Array of size group_count`. The element ``group_size[i] is the number of matrices in the group i. Each element in group_size must be at least 0.
- dependencies
-
List of events to wait for before starting computation, if any. If omitted, defaults to no dependencies.
Output Parameters
- b
-
Output array of pointers to B matrices, overwritten by total_batch_count matrix transpose or copy operations of the form alpha*op(A). If matrices are stored using column major layout, the array allocated for each B matrix of the group i must be of size at least ldb[i] * n[i] if B is not transposed or ldb[i]*m[i] if B is transposed. If matrices are stored using row major layout, the array allocated for each B matrix of the group i must be of size at least ldb[i] * m[i] if B is not transposed or ldb[i]*n[i] if B is transposed.
Return Values
Output event to wait on to ensure computation is complete.
Strided API
The operation for the strided API is defined as:
for i = 0 … batch_size – 1 A and B are matrices at offset i * stride_a in a and i * stride_b in b B = alpha * op(A) end for
where:
op(X) is one of op(X) = X, op(X) = X', or op(X) = conjg(X')
alpha is a scalar
A and B are matrices
For the strided API, the single input array contains all the input matrices, and the single output array contains all the output matrices. The locations of the individual matrices within the array are given by stride lengths, while the number of matrices is given by the batch_size parameter.
Syntax
namespace oneapi::mkl::blas::column_major { sycl::event omatcopy_batch(sycl::queue &queue, transpose trans, std::int64_t m, std::int64_t n, oneapi::mkl::value_or_pointer<T> alpha, const T *a, std::int64_t lda, std::int64_t stride_a, T *b, std::int64_t ldb, std::int64_t stride_b, std::int64_t batch_size, const std::vector<sycl::event> &dependencies = {}); }
namespace oneapi::mkl::blas::row_major { sycl::event omatcopy_batch(sycl::queue &queue, transpose trans, std::int64_t m, std::int64_t n, oneapi::mkl::value_or_pointer<T> alpha, const T *a, std::int64_t lda, std::int64_t stride_a, T *b, std::int64_t ldb, std::int64_t stride_b, std::int64_t batch_size, const std::vector<sycl::event> &dependencies = {}); }
Input Parameters
- trans
-
Specifies op(A), the transposition operation applied to the matrices A.
- m
-
Number of rows for each matrix A. Must be at least zero.
- n
-
Number of columns for each matrix A. Must be at least zero.
- alpha
-
Scaling factor for the matrix transposition or copy. See Scalar Arguments for more information on the value_or_pointer data type.
- a
-
Array holding the input matrices A. Must have size at least stride_a*batch_size.
- lda
-
Leading dimension of the A matrices. If matrices are stored using column major layout, lda must be at least m. If matrices are stored using row major layout, lda must be at least n. Must be positive.
- stride_a
-
Stride between the different A matrices. If matrices are stored using column major layout, stride_a must be at least lda*n. If matrices are stored using row major layout, stride_a must be at least lda*m.
- ldb
-
Leading dimension of the matrices B. Must be positive and satisfy:
trans = transpose::nontrans
trans = transpose::trans or trans = transpose::conjtrans
Column major
Must be at least m
Must be at least n
Row major
Must be at least n
Must be at least m
- stride_b
-
Stride between the different B matrices in the array b. Must be positive and satisfy:
trans = transpose::nontrans
trans = transpose::trans or trans = transpose::conjtrans
Column major
Must be at least ldb*n
Must be at least ldb*m
Row major
Must be at least ldb*m
Must be at least ldb*n
- batch_size
-
Specifies the number of matrices to transpose or copy. Must be at least zero.
- dependencies
-
List of events to wait for before starting computation, if any. If omitted, defaults to no dependencies.
Output Parameters
- b
-
Output array, overwritten by batch_size matrix transpose or copy operations of the form alpha*op(A). Must have size at least stride_b*batch_size.
Return Values
Output event to wait on to ensure computation is complete.