Visible to Intel only — GUID: GUID-EFA2CA20-A2B7-481B-AC2C-D2A0C0434C9B
Abs
AbsBackward
Add
AvgPool
AvgPoolBackward
BatchNormForwardTraining
BatchNormInference
BatchNormTrainingBackward
BiasAdd
BiasAddBackward
Clamp
ClampBackward
Concat
Convolution
ConvolutionBackwardData
ConvolutionBackwardWeights
ConvTranspose
ConvTransposeBackwardData
ConvTransposeBackwardWeights
Dequantize
Divide
DynamicDequantize
DynamicQuantize
Elu
EluBackward
End
Exp
GELU
GELUBackward
HardSigmoid
HardSigmoidBackward
HardSwish
HardSwishBackward
Interpolate
InterpolateBackward
LayerNorm
LayerNormBackward
LeakyReLU
Log
LogSoftmax
LogSoftmaxBackward
MatMul
Maximum
MaxPool
MaxPoolBackward
Minimum
Mish
MishBackward
Multiply
Pow
PReLU
PReLUBackward
Quantize
Reciprocal
ReduceL1
ReduceL2
ReduceMax
ReduceMean
ReduceMin
ReduceProd
ReduceSum
ReLU
ReLUBackward
Reorder
Round
Select
Sigmoid
SigmoidBackward
SoftMax
SoftMaxBackward
SoftPlus
SoftPlusBackward
Sqrt
SqrtBackward
Square
SquaredDifference
StaticReshape
StaticTranspose
Subtract
Tanh
TanhBackward
TypeCast
Wildcard
enum dnnl_alg_kind_t
enum dnnl_normalization_flags_t
enum dnnl_primitive_kind_t
enum dnnl_prop_kind_t
enum dnnl_query_t
enum dnnl::normalization_flags
enum dnnl::query
struct dnnl_exec_arg_t
struct dnnl_primitive
struct dnnl_primitive_desc
struct dnnl::primitive
struct dnnl::primitive_desc
struct dnnl::primitive_desc_base
enum dnnl_rnn_direction_t
enum dnnl_rnn_flags_t
enum dnnl::rnn_direction
enum dnnl::rnn_flags
struct dnnl::augru_backward
struct dnnl::augru_forward
struct dnnl::gru_backward
struct dnnl::gru_forward
struct dnnl::lbr_augru_backward
struct dnnl::lbr_augru_forward
struct dnnl::lbr_gru_backward
struct dnnl::lbr_gru_forward
struct dnnl::lstm_backward
struct dnnl::lstm_forward
struct dnnl::rnn_primitive_desc_base
struct dnnl::vanilla_rnn_backward
struct dnnl::vanilla_rnn_forward
Visible to Intel only — GUID: GUID-EFA2CA20-A2B7-481B-AC2C-D2A0C0434C9B
Primitive Attributes: Quantization
Introduction
Some primitives in the library support input/output tensors with the INT8 (either signed or unsigned) data type. The primary goal is to support reduced precision inference on the compatible hardware.
Related materials:
Lower Numerical Precision Deep Learning Inference and Training
An example with annotations: Int8 Inference
Quantization Model
The primary quantization model that the library assumes is the following:

where  is a scaling factor in float format,
is a scaling factor in float format,  is the zero point in int32 format, and
is the zero point in int32 format, and  is used to denote elementwise application of the formula to the arrays. In order to provide best performance, oneDNN does not compute those scaling factors and zero-points as part of primitive computation. Those should be computed and provided by the user.
is used to denote elementwise application of the formula to the arrays. In order to provide best performance, oneDNN does not compute those scaling factors and zero-points as part of primitive computation. Those should be computed and provided by the user.
These quantization parameters can either be computed ahead of time using calibration tools (static quantization) or at runtime based on the actual minimum and maximum values of a tensor (dynamic quantization). Either method can be used in conjunction with oneDNN, as the quantization parameters are passed to the oneDNN primitives at execution time.
To support int8 quantization, primitives should be created and executed as follow:
during primitive descriptor creation, if one or multiple inputs are int8 (signed or not), then the primitive will behave as a quantized integer operation.
still during primitive descriptor creation, the dimensionality of the scaling factors and zero-point should be provided using masks (e.g. one scale per tensor, one scale per channel, …).
finally, during primitive execution, the user must provide the actual quantization parameters as arguments to the execute function. Scales are f32 values, and zero-points are s32 values.
For performance reasons, each primitive implementation typically supports only a subset of quantization parameter masks. For example, convolution typically supports per-tensor or per-channel scales (no zero-point) for weights, and per-tensor scaling factor and zero-points for activation.
This guide does not cover how the appropriate scaling factor can be found. Refer to the materials in the Introduction.
Numerical behavior
Primitive implementations are allowed to convert int8 inputs to wider datatypes (e.g. int16 or int32), as those conversions do not impact accuracy.
During execution, primitives implementations avoid integer overflows and maintain integer accuracy by using wider datatypes (e.g. int32) for intermediate values and accumulators. Those are then converted as necessary before the result is written to the output memory objects. During that conversion, implementations typically saturate in case of underflow/overflow (e.g. when converting s32 to int8).
WARNING:
Depending on the architecture, the behavior of int8 computations might slightly vary. For more details, refer to Nuances of int8 Computations.
When multiple operations are fused in a single primitive using the post ops attribute, those are assumed to be computed in f32 precision. As a result the destination quantization parameters are applied after the post-ops as follow:
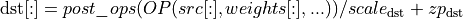
Quantizing/dequantizing values between post-operations can still be achieved using one of [eltwise](dev_guide_attributes_post_ops_eltwise), [binary](dev_guide_attributes_post_ops_binary), or the scale parameter of the appropriate post-operation.
Example: Convolution Quantization Workflow
Consider a convolution without bias. The tensors are represented as:


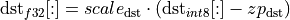
Here the  are not computed at all, the whole work happens with int8 tensors.So the task is to compute the
are not computed at all, the whole work happens with int8 tensors.So the task is to compute the 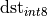 tensor, using the
tensor, using the  ,
,  tensors passed at execution time, as well as the corresponding quantization parameters scale_{ \form#12}, scale_{ \form#35}, scale_{ \form#36} and zero_point{ \form#12}, zero_point_{ \form#36}. Mathematically, the computations are:
tensors passed at execution time, as well as the corresponding quantization parameters scale_{ \form#12}, scale_{ \form#35}, scale_{ \form#36} and zero_point{ \form#12}, zero_point_{ \form#36}. Mathematically, the computations are:

where
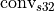 is just a regular convolution which takes source and weights with int8 data type and compute the result in int32 data type (int32 is chosen to avoid overflows during the computations);
is just a regular convolution which takes source and weights with int8 data type and compute the result in int32 data type (int32 is chosen to avoid overflows during the computations);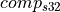 is a compensation term to account for \form#12 non-zero zero-point. This term is computed by the oneDNN library and can typically be pre-computed ahead of time, for example during weights reorder.
is a compensation term to account for \form#12 non-zero zero-point. This term is computed by the oneDNN library and can typically be pre-computed ahead of time, for example during weights reorder.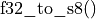 converts an f32 value to s8 with potential saturation if the values are out of the range of the int8 data type.
converts an f32 value to s8 with potential saturation if the values are out of the range of the int8 data type. converts an int8 value to f32 with potential rounding. This conversion is typically necessary to apply f32 scaling factors.
converts an int8 value to f32 with potential rounding. This conversion is typically necessary to apply f32 scaling factors.
Per-Channel Scaling
Some of the primitives have limited support of multiple scales for a quantized tensor. The most popular use case is the Convolution primitive that supports per-output-channel scaling factors for the weights, meaning that the actual convolution computations would need to scale different output channels differently. This is possible without significant performance loss because the per-output-channel re-quantization is only required at the very end of the computations. It seems impossible to implement the same trick for the input channels, since that would require re-quantization for every input data point.



Note that now the weights’ scaling factor depends on  .
.
To compute the we need to perform the following:

The user is responsible for preparing quantized weights accordingly. To do that, oneDNN provides reorders that can perform per-channel scaling:
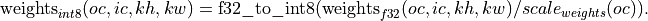
API
The library API to support for INT8 was designed for the model described above. However, it does not require users to follow exactly this model. As long as users can fit their model into the given functionality everything should work fine. Having this in mind we tried to design a minimal and simple yet powerful enough quantization API.
The most common data type for data tensors during INT8 inference is dnnl::memory::data_type::s8 and dnnl::memory::data_type::u8. All the scaling factors related to tensors are not attached in any way to the oneDNN memory objects and should be maintained by users.
The library essentially extends the ability of the primitives to scale the output before storing the result to the memory with the destination data type. That’s exactly the minimum that we need to support INT8 inference (check the equations above only 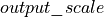 is non-standard).
is non-standard).
The scaling happens in the single precision floating point data type (dnnl::memory::data_type::f32). Before storing, the result is downconverted to the destination data type with saturation if required. The rounding happens according to the current HW setting (for instance, on CPU according to the MXCSR register).
Argument Scaling
The library uses Primitive Attributes API for setting the scaling factors for most of the primitives. The supporting attributes can be found in the documentation for each primitive. The unsupported cases are handled according to the attributes error handling section.
API:
Primitives support scales only when the data type of computation is an integer.
The parameters (C++ API for simplicity):
void dnnl::primitive_attr::set_scales_mask(int arg, int mask);
In the simplest case, when there is only one common scale the attribute changes the op behavior from
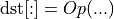
to
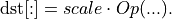
To support scales per one or several dimensions, users must set the appropriate mask.
Say the destination is a  tensor and we want to have output scales per
tensor and we want to have output scales per  dimension (where
dimension (where 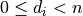 ).
).
Then the mask should be set to:
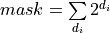 ,
,
and the number of scales should be:
scales.size() =
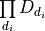 .
.
Example 1: weights quantization with per-output-channel scaling
// weights dimensions const int OC, IC, KH, KW; // original f32 weights in plain format dnnl::memory::desc wei_plain_f32_md( {OC, IC, KH, KW}, // dims dnnl::memory::data_type::f32, // the data originally in f32 dnnl::memory::format_tag::hwigo // the plain memory format ); // the scaling factors for quantized weights // An unique scale for each output-channel. std::vector<float> wei_scales(OC) = { /* values */ }; dnnl::memory(); // int8 convolution primitive descriptor dnnl::convolution_forward::primitive_desc conv_pd(/* see the next example */); // query the convolution weights memory descriptor dnnl::memory::desc wei_conv_s8_md = conv_pd.weights_desc(); // prepare the attributes for the reorder dnnl::primitive_attr attr; const int quantization_mask = 0 | (1 << 0); // scale per OC dimension, which is the dim #0 attr.set_scales_mask(DNNL_ARG_DST, quantization_mask); // create reorder that would perform: // wei_s8(oc, ic, kh, kw) <- wei_f32(oc, ic, kh, kw) / scale(oc) // including the data format conversion. auto wei_reorder_pd = dnnl::reorder::primitive_desc( wei_plain_f32_md, engine, // source wei_conv_s8_md, engine, // destination, attr); auto wei_reorder = dnnl::reorder(wei_reorder_pd); // ...
Example 2: convolution with per-output-channel quantization
This example is complementary to the previous example (which should ideally be the first one). Let’s say we want to create an int8 convolution with per-output channel scaling.
const float src_scale; // src_f32[:] = src_scale * src_s8[:] const float dst_scale; // dst_f32[:] = dst_scale * dst_s8[:] // the scaling factors for quantized weights (as declared above) // An unique scale for each output-channel. std::vector<float> wei_scales(OC) = {...}; // Src, weights, and dst memory descriptors for convolution, // with memory format tag == any to allow a convolution implementation // to chose the appropriate memory format dnnl::memory::desc src_conv_s8_any_md( {BATCH, IC, IH, IW}, // dims dnnl::memory::data_type::s8, // the data originally in s8 dnnl::memory::format_tag::any // let convolution to choose ); dnnl::memory::desc wei_conv_s8_any_md( {OC, IC, KH, KW}, // dims dnnl::memory::data_type::s8, // the data originally in s8 dnnl::memory::format_tag::any // let convolution to choose ); dnnl::memory::desc dst_conv_s8_any_md(...); // ditto // prepare the attributes for the convolution dnnl::primitive_attr attr; const int data_mask = 0; // scale and zero-point per tensor for source and destination const int wei_mask = 0 | (1 << 0); // scale per OC dimension, which is the dim #0 on weights tensor: // ( OC, IC, KH, KW) // 0 1 2 3 attr.set_scales_mask(DNNL_ARG_SRC, data_mask); attr.set_zero_points_mask(DNNL_ARG_SRC, data_mask); attr.set_scales_mask(DNNL_ARG_WEIGHTS, wei_mask); attr.set_scales_mask(DNNL_ARG_DST, data_mask); attr.set_zero_points_mask(DNNL_ARG_DST, data_mask); // create a convolution primitive descriptor auto conv_pd = dnnl::convolution_forward::primitive_desc( dnnl::prop_kind::forward_inference, dnnl::algorithm::convolution_direct, src_conv_s8_any_md, // what's important is that wei_conv_s8_any_md, // we specified that we want dst_conv_s8_any_md, // computations in s8 strides, padding_l, padding_r, dnnl::padding_kind::zero attr); // the attributes describe the quantization flow // ...