Intel® oneAPI Deep Neural Network Developer Guide and Reference
A newer version of this document is available. Customers should click here to go to the newest version.
Visible to Intel only — GUID: GUID-928AF07C-0BBF-4BDE-AEEE-9539BE367D7B
Visible to Intel only — GUID: GUID-928AF07C-0BBF-4BDE-AEEE-9539BE367D7B
Concat
General
The concat primitive concatenates  tensors over concat_dimension (here designated
tensors over concat_dimension (here designated  ) and is defined as (the variable names follow the standard Naming Conventions):
) and is defined as (the variable names follow the standard Naming Conventions):
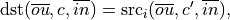
where  .
.
The concat primitive does not have a notion of forward or backward propagation. The backward propagation for the concatenation operation is simply an identity operation.
Execution Arguments
When executed, the inputs and outputs should be mapped to an execution argument index as specified by the following table.
Primitive input/output |
Execution argument index |
|---|---|
|
DNNL_ARG_MULTIPLE_SRC |
|
DNNL_ARG_DST |

Implementation Details
General Notes
The
 memory format can be either specified by a user or derived by the primitive. The recommended way is to allow the primitive to choose the most appropriate format.
memory format can be either specified by a user or derived by the primitive. The recommended way is to allow the primitive to choose the most appropriate format.The concat primitive requires all source and destination tensors to have the same shape except for the concat_dimension. The destination dimension for the concat_dimension must be equal to the sum of the concat_dimension dimensions of the sources (i.e.
 ). Implicit broadcasting is not supported.
). Implicit broadcasting is not supported.
Data Types Support
The concat primitive supports arbitrary data types for source and destination tensors according to the Data Types page. However, it is required that all source tensors are of the same data type (but not necessarily matching the data type of the destination tensor).
Data Representation
The concat primitive works with arbitrary data tensors. There is no special meaning associated with any logical dimensions.
Post-Ops and Attributes
Type |
Operation |
Description |
Res |
|---|---|---|---|
Attribute |
Scales the corresponding input tensor by the given scale factor(s). |
Only one scale per tensor is supported. Input tensors only. |
Implementation Limitations
The primitive works with several memory formats, such as plain formats dnnl_nchw, dnnl_nhwc, and blocked formats dnnl_nChw16c, dnnl_nCdhw8c that appear in convolutions. The primitive does not support non-blocked formats that are typically used in prepacked weights, such as:
Winograd format dnnl_format_kind_opaque,
RNN format dnnl_format_kind_opaque, or
In some cases for blocked format with attached compensation that is used in s8s8 convolutions (see Nuances of int8 Computations).
Refer to Data Types for limitations related to data types support.
GPU
Only tensors of 6 or fewer dimensions are supported.
Performance Tips
Whenever possible, avoid specifying the destination memory format so that the primitive is able to choose the most appropriate one.
The concat primitive is highly optimized for the cases in which all source tensors have same memory format and data type matches the destination tensor data type. For other cases, more general but slower code is working. Consider reordering sources to the same data format before using the concat primitive.
Example
This C++ API example demonstrates how to create and execute a Concat primitive.
Key optimizations included in this example:
Identical source (src) memory formats.
Creation of optimized memory format for destination (dst) from the primitive descriptor