Visible to Intel only — GUID: GUID-72840981-864D-4ED6-8C28-4D43984C2DB7
basic_statistics_dense_batch.cpp
basic_statistics_dense_online.cpp
column_accessor_homogen.cpp
cor_dense_batch.cpp
cor_dense_online.cpp
cov_dense_batch.cpp
cov_dense_biased_batch.cpp
cov_dense_biased_online.cpp
cov_dense_online.cpp
csr_accessor.cpp
csr_table.cpp
dbscan_brute_force_batch.cpp
df_cls_hist_batch.cpp
df_cls_hist_batch_random.cpp
df_cls_traverse_model.cpp
df_reg_hist_batch.cpp
df_reg_hist_batch_random.cpp
df_reg_traverse_model.cpp
heterogen_table.cpp
homogen_table.cpp
kmeans_init_dense.cpp
kmeans_lloyd_dense_batch.cpp
knn_cls_brute_force_dense_batch.cpp
knn_reg_brute_force_dense_batch.cpp
knn_search_brute_force_dense_batch.cpp
linear_kernel_dense_batch.cpp
linear_regression_dense_batch.cpp
linear_regression_dense_online.cpp
logistic_regression_dense_batch.cpp
pca_cor_dense_batch.cpp
pca_cor_dense_online.cpp
pca_cov_dense_batch.cpp
pca_cov_dense_online.cpp
pca_precomputed_cor_dense_batch.cpp
pca_precomputed_cov_dense_batch.cpp
pca_svd_dense_batch.cpp
rbf_kernel_dense_batch.cpp
read_batch.cpp
svm_two_class_thunder_dense_batch.cpp
basic_statistics_dense_batch.cpp
basic_statistics_dense_online.cpp
column_accessor_homogen.cpp
connected_components_batch.cpp
cor_dense_batch.cpp
cor_dense_online.cpp
cov_dense_batch.cpp
cov_dense_biased_batch.cpp
cov_dense_biased_online.cpp
cov_dense_online.cpp
csr_accessor.cpp
csr_table.cpp
dbscan_brute_force_batch.cpp
df_cls_dense_batch.cpp
df_reg_dense_batch.cpp
directed_graph.cpp
graph_service_functions.cpp
heterogen_table.cpp
homogen_table.cpp
jaccard_batch.cpp
jaccard_batch_app.cpp
kmeans_init_dense.cpp
kmeans_lloyd_dense_batch.cpp
knn_cls_brute_force_dense_batch.cpp
knn_cls_kd_tree_dense_batch.cpp
knn_search_brute_force_dense_batch.cpp
linear_kernel_dense_batch.cpp
linear_regression_dense_batch.cpp
linear_regression_dense_online.cpp
logloss_dense_batch.cpp
louvain_batch.cpp
pca_cor_dense_batch.cpp
pca_cor_dense_online.cpp
pca_cov_dense_batch.cpp
pca_cov_dense_online.cpp
pca_precomputed_dense_batch.cpp
pca_svd_dense_batch.cpp
pca_svd_dense_online.cpp
polynomial_kernel_dense_batch.cpp
rbf_kernel_dense_batch.cpp
read_batch.cpp
shortest_paths_batch.cpp
sigmoid_kernel_dense_batch.cpp
subgraph_isomorphism_batch.cpp
svm_multi_class_thunder_csr_batch.cpp
svm_multi_class_thunder_dense_batch.cpp
svm_nu_cls_thunder_csr_batch.cpp
svm_nu_cls_thunder_dense_batch.cpp
svm_nu_reg_thunder_csr_batch.cpp
svm_nu_reg_thunder_dense_batch.cpp
svm_reg_thunder_csr_batch.cpp
svm_reg_thunder_dense_batch.cpp
svm_two_class_smo_csr_batch.cpp
svm_two_class_smo_dense_batch.cpp
svm_two_class_thunder_csr_batch.cpp
svm_two_class_thunder_dense_batch.cpp
triangle_counting_batch.cpp
K-Means Clustering
Density-Based Spatial Clustering of Applications with Noise
Correlation and Variance-Covariance Matrices
Principal Component Analysis
Principal Components Analysis Transform
Singular Value Decomposition
Association Rules
Kernel Functions
Expectation-Maximization
Cholesky Decomposition
QR Decomposition
Outlier Detection
Distance Matrix
Distributions
Engines
Moments of Low Order
Quantile
Quality Metrics
Sorting
Normalization
Optimization Solvers
Decision Forest
Decision Trees
Gradient Boosted Trees
Stump
Linear and Ridge Regressions
LASSO and Elastic Net Regressions
k-Nearest Neighbors (kNN) Classifier
Implicit Alternating Least Squares
Logistic Regression
Naïve Bayes Classifier
Support Vector Machine Classifier
Multi-class Classifier
Boosting
Visible to Intel only — GUID: GUID-72840981-864D-4ED6-8C28-4D43984C2DB7
Stochastic Gradient Descent Algorithm
The stochastic gradient descent (SGD) algorithm is a special case of an iterative solver. See Iterative Solver for more details.
Computation methods
The following computation methods are available in oneDAL for the stochastic gradient descent algorithm:
Default method (a special case of mini-batch used by default)
Mini-batch method
The mini-batch method (miniBatch) of the stochastic gradient descent algorithm [Mu2014] follows the algorithmic framework of an iterative solver with an empty set of intrinsic parameters of the algorithm 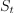 , algorithm-specific transformation T defined for the learning rate sequence
, algorithm-specific transformation T defined for the learning rate sequence 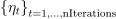 , conservative sequence
, conservative sequence 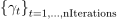 and the number of iterations in the internal loop L, algorithm-specific vector U and power d of Lebesgue space defined as follows:
and the number of iterations in the internal loop L, algorithm-specific vector U and power d of Lebesgue space defined as follows:
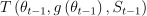
For l from 1 until L:
Update the function argument:
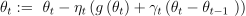
Compute the gradient:
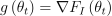
Convergence check: 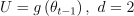
Default method
The default method (defaultDense) is a particular case of the mini-batch method with the batch size 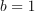 ,
, 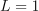 , and conservative sequence
, and conservative sequence 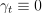 .
.
Momentum method
The momentum method (momentum) of the stochastic gradient descent algorithm [Rumelhart86] follows the algorithmic framework of an iterative solver with the set of intrinsic parameters , algorithm-specific transformation T defined for the learning rate sequence and momentum parameter 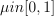 , and algorithm-specific vector U and power d of Lebesgue space defined as follows:
, and algorithm-specific vector U and power d of Lebesgue space defined as follows:
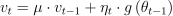
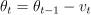
For the momentum method of the SGD algorithm, the set of intrinsic parameters only contains the last update vector 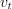 .
.
Convergence check:
Computation
The stochastic gradient descent algorithm is a special case of an iterative solver. For parameters, input, and output of iterative solvers, see Computation.
Algorithm Parameters
In addition to parameters of the iterative solver, the stochastic gradient descent algorithm has the following parameters. Some of them are required only for specific values of the computation method parameter method:
Parameter |
method |
Default Value |
Description |
|---|---|---|---|
algorithmFPType |
defaultDense, miniBatch, momentum |
float |
The floating-point type that the algorithm uses for intermediate computations. Can be float or double. |
method |
Not applicable |
defaultDense |
Available computation methods: For CPU:
For GPU:
|
batchIndices |
defaultDense, miniBatch, momentum |
Not applicable |
The numeric table with 32-bit integer indices of terms in the objective function. The method parameter determines the size of the numeric table:
If no indices are provided, the implementation generates random indices. |
batchSize |
miniBatch,``momentum`` |
128 |
The number of batch indices to compute the stochastic gradient. If batchSize equals the number of terms in the objective function, no random sampling is performed, and all terms are used to calculate the gradient. The algorithm ignores this parameter if the batchIndices parameter is provided. For the defaultDense value of method, one term is used to compute the gradient on each iteration. |
conservativeSequence |
miniBatch |
A numeric table of size |
The numeric table of size
|
innerNIterations |
miniBatch |
5 |
The number of inner iterations for the miniBatch method. |
learningRateSequence |
defaultDense, miniBatch, momentum |
A numeric table of size |
The numeric table of size
|
momentum |
momentum |
0.9 |
The momentum value. |
engine |
defaultDense, miniBatch, momentum |
SharePtr< engines:: mt19937:: Batch>() |
Pointer to the random number generator engine that is used internally for generation of 32-bit integer indices of terms in the objective function. |
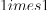 that contains the default conservative coefficient equal to 1.
that contains the default conservative coefficient equal to 1. or
or 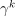 for
for 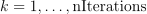 .
.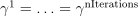 .
.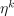 for
for 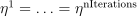 .
.Examples
C++ (CPU)
Batch Processing:
Python*
Batch Processing: