Intel® oneAPI Data Analytics Library Developer Guide and Reference
A newer version of this document is available. Customers should click here to go to the newest version.
k-Nearest Neighbors Classification, Regression, and Search (k-NN)
k-NN classification, regression, and search algorithms are based on finding the k nearest observations to the training set. For classification, the problem is to infer the class of a new feature vector by computing the majority vote of its k nearest observations from the training set. For regression, the problem is to infer the target value of a new feature vector by computing the average target value of its k nearest observations from the training set. For search, the problem is to identify the k nearest observations from the training set to a new feature vector. The nearest observations are computed based on the chosen distance metric.
Operation |
Computational methods |
Programming Interface |
|||
Mathematical formulation
Training
Classification
Let 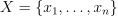 be the training set of p-dimensional feature vectors, let
be the training set of p-dimensional feature vectors, let 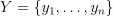 be the set of class labels, where
be the set of class labels, where  ,
, 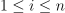 , and C is the number of classes. Given X, Y, and the number of nearest neighbors k, the problem is to build a model that allows distance computation between the feature vectors in training and inference sets at the inference stage.
, and C is the number of classes. Given X, Y, and the number of nearest neighbors k, the problem is to build a model that allows distance computation between the feature vectors in training and inference sets at the inference stage.
Regression
Let be the training set of p-dimensional feature vectors, let be the corresponding continuous target outputs, where 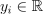 . Given X, Y, and the number of nearest neighbors k, the problem is to build a model that allows distance computation between the feature vectors in training and inference sets at the inference stage.
. Given X, Y, and the number of nearest neighbors k, the problem is to build a model that allows distance computation between the feature vectors in training and inference sets at the inference stage.
Search
Let be the training set of p-dimensional feature vectors. Given X and the number of nearest neighbors k, the problem is to build a model that allows distance computation between the feature vectors in training and inference sets at the inference stage.
Training method: brute-force
The training operation produces the model that stores all the feature vectors from the initial training set X.
Training method: k-d tree
The training operation builds a k-d tree that partitions the training set X (for more details, see k-d Tree).
Inference
Classification
Let 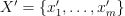 be the inference set of p-dimensional feature vectors. Given
be the inference set of p-dimensional feature vectors. Given 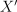 , the model produced at the training stage, and the number of nearest neighbors k, the problem is to predict the label
, the model produced at the training stage, and the number of nearest neighbors k, the problem is to predict the label 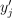 from the Y set for each
from the Y set for each 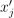 ,
, 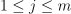 , by performing the following steps:
, by performing the following steps:
Identify the set
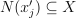 of k feature vectors in the training set that are nearest to with respect to the Euclidean distance, which is chosen by default. The distance can be customized with the predefined set of pairwise distances: Minkowski distances with fractional degree (including Euclidean distance), Chebyshev distance, and Cosine distance.
of k feature vectors in the training set that are nearest to with respect to the Euclidean distance, which is chosen by default. The distance can be customized with the predefined set of pairwise distances: Minkowski distances with fractional degree (including Euclidean distance), Chebyshev distance, and Cosine distance.Estimate the conditional probability for the l-th class as the fraction of vectors in
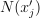 whose labels
whose labels 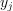 are equal to l:
are equal to l:
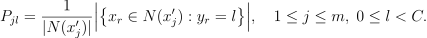
Predict the class that has the highest probability for the feature vector
:
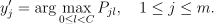
Regression
Let be the inference set of p-dimensional feature vectors. Given , the model produced at the training stage, and the number of nearest neighbors k, the problem is to predict the continuous target variable from the Y set for each , , by performing the following steps:
Identify the set
of k feature vectors in the training set that are nearest to with respect to the Euclidean distance, which is chosen by default. The distance can be customized with the predefined set of pairwise distances: Minkowski distances with fractional degree (including Euclidean distance), Chebyshev distance, and Cosine distance.Estimate the conditional expectation of the target variable based on the nearest neighbors
as the average of the target values for those neighbors:
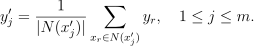
Search
Let be the inference set of p-dimensional feature vectors. Given , the model produced at the training stage, and the number of nearest neighbors k:
Identify the set
of k feature vectors in the training set that are nearest to with respect to the Euclidean distance, which is chosen by default. The distance can be customized with the predefined set of pairwise distances: Minkowski distances with fractional degree (including Euclidean distance), Chebyshev distance, and Cosine distance.
Inference method: brute-force
Brute-force inference method determines the set of the nearest feature vectors by iterating over all the pairs 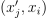 in the implementation defined order,
in the implementation defined order, 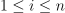 ,
, 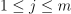 .
.
Inference method: k-d tree
K-d tree inference method traverses the k-d tree to find feature vectors associated with a leaf node that are closest to , 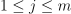 . The set
. The set 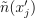 of the currently known nearest k neighbors is progressively updated during the tree traversal. The search algorithm limits exploration of the nodes for which the distance between the and respective part of the feature space is not less than the distance between and the most distant feature vector from . Once tree traversal is finished,
of the currently known nearest k neighbors is progressively updated during the tree traversal. The search algorithm limits exploration of the nodes for which the distance between the and respective part of the feature space is not less than the distance between and the most distant feature vector from . Once tree traversal is finished,  .
.
Programming Interface
Refer to API Reference: k-Nearest Neighbors Classification, Regression, and Search.
The following table describes current device support:
Task |
CPU |
GPU |
|---|---|---|
Classification |
Yes |
Yes |
Regression |
No |
Yes |
Search |
Yes |
Yes |
Distributed mode
The algorithm supports distributed execution in SPMD mode (only on GPU).
Usage Example
Training
knn::model<> run_training(const table& data,
const table& labels) {
const std::int64_t class_count = 10;
const std::int64_t neighbor_count = 5;
const auto knn_desc = knn::descriptor<float>{class_count, neighbor_count};
const auto result = train(knn_desc, data, labels);
return result.get_model();
}Inference
table run_inference(const knn::model<>& model,
const table& new_data) {
const std::int64_t class_count = 10;
const std::int64_t neighbor_count = 5;
const auto knn_desc = knn::descriptor<float>{class_count, neighbor_count};
const auto result = infer(knn_desc, model, new_data);
print_table("labels", result.get_labels());
}Examples
oneAPI DPC++
Batch Processing:
oneAPI C++
Batch Processing:
Python* with DPC++ support
Distributed Processing: