Visible to Intel only — GUID: GUID-1B9B3FAC-1902-4012-84EC-93FAC2121F31
Introduction
Getting Started
Parallelization
Intel® Iris® Xe GPU Architecture
GPU Execution Model Overview
SYCL* Thread Mapping and GPU Occupancy
Kernels
Using Libraries for GPU Offload
Host/Device Memory, Buffer and USM
Host/Device Coordination
Using Multiple Heterogeneous Devices
Compilation
Optimizing Media Pipelines
OpenMP Offloading Tuning Guide
Debugging and Profiling
GPU Analysis with Intel® Graphics Performance Analyzers (Intel® GPA)
Reference
Terms and Conditions
Sub-groups and SIMD Vectorization
Removing Conditional Checks
Registerization and Avoid Register Spills
Shared Local Memory
Pointer Aliasing and the Restrict Directive
Synchronization among Threads in a Kernel
Considerations for Selecting Work-group Size
Reduction
Kernel Launch
Executing Multiple Kernels on the Device at the Same Time
Submitting Kernels to Multiple Queues
Avoid Redundant Queue Construction
Visible to Intel only — GUID: GUID-1B9B3FAC-1902-4012-84EC-93FAC2121F31
Run a GPU Roofline Analysis
To estimate actual performance of a GPU application against hardware-imposed ceilings, you can use the GPU Roofline Insights feature. Intel® Advisor can generate a roofline model for kernels running on Intel GPUs. The GPU Roofline model offers a very efficient way to characterize your kernels and visualize how far you are from ideal performance. For details about the GPU Roofline, see the Intel Advisor User Guide.
Prerequisites: It is recommended to run the GPU Roofline with root privileges on Linux* OS or as an administrator on Windows* OS.
Linux OS Users
If you do not have root permissions on Linux, configure your system to enable collecting GPU metrics for non-root users:
Add your username to the video group. To check if you are already in the video group:
groups | grep video
If you are not part of the video group, add your username to it:
sudo usermod -a -G video <username>
Set the value of the dev.i915.perf_stream_paranoid sysctl option to 0:
sysctl -w dev.i915.perf_stream_paranoid=0
Disable time limits to run the OpenCL kernel for a longer period:
sudo sh -c "echo N> /sys/module/i915/parameters/enable_hangcheck"
All Users
Make sure that your SYCL code runs correctly on the GPU. To check which hardware you are running on, add the following to your SYCL code and run it:
sycl::default_selector selector; sycl::queue queue(delector); auto d = queue.get_device(); std::cout<<Running on :<<d.get_info<cl::sycl::info::device::name>()<<std::endl;
Set up the Intel Advisor environment for Linux OS:
source <advisor_install_dir>/env/vars.sh
and for Windows OS:
<install-dir>/advisor-vars.bat
To run the GPU Roofline analysis in the Intel Advisor CLI:
Run the Survey analysis with the profile-gpu option:
advisor -collect=survey --profile-gpu --project-dir=./advisor-project --search-dir src:r=./matrix_multiply -- matrix_multiply
Run the Trip Count and FLOP analysis with --profile-gpu::
advisor --collect=tripcounts --stacks --flop --profile-gpu --project-dir=./advisor-project --search-dir src:r=./matrix_multiply -- matrix_multiply
Open the generated GPU Roofline report in the Intel Advisor GUI. Review the following metrics for the DPC++ Matrix Multiply application:
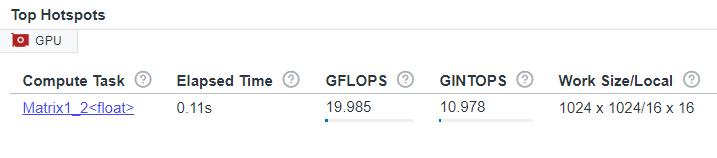
In the Summary tab, view top hotspots and the memory layout in the Top Hotspots pane.
Top Hotspots pane
See how efficiently your application uses execution units in the Performance Characteristics pane.
Performance Characteristics pane

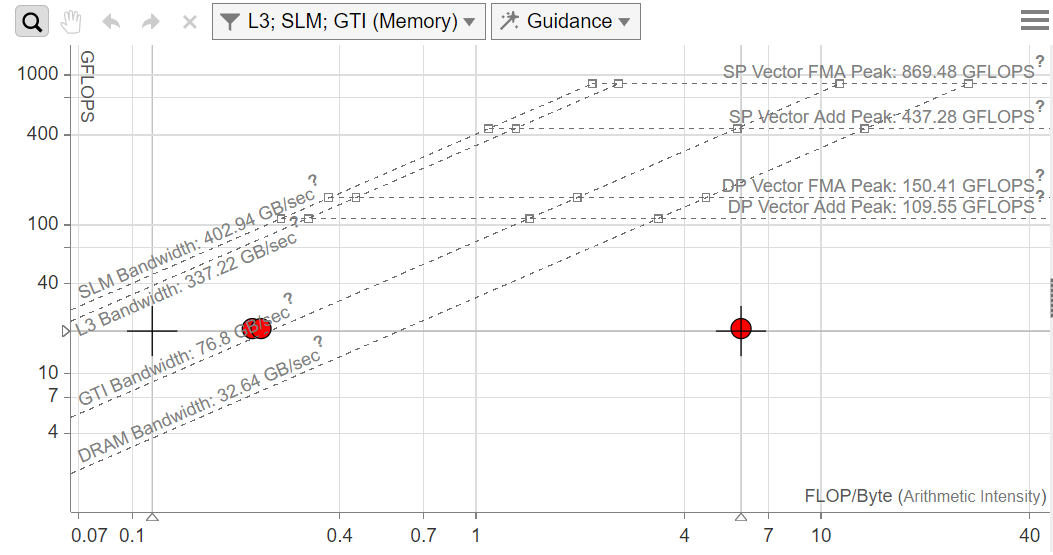
In the GPU Roofline Regions tab, see the GPU Roofline chart and performance metrics.
GPU Roofline chart and performance metrics
The Matrix Multiply application gets 10.98 GFLOPS. It uses global memory and is not optimized for local (SLM) memory because the application uses a global accessor.
The application is far from the maximum bandwidth of the GTI, as represented by the red dot on the the right.
The dot on the left represents the L3 bandwidth. As the chart shows, it is far from the L3 bandwidth maximum.
As the GPU Roofline chart suggests, several possible optimizations might result in more efficient memory usage:
Use local memory (SLM).
Use the cache blocking technique to better use SLM/L3 cache.
The following code is the optimized version of the Matrix Multiply application. In this version, we declare two tiles and define them as sycl::access::target:local. We also modify the kernel to process these tiles in some inner loops.
// Replaces accessorC reference with a local variable
void multiply1_1(int msize, int tidx, int numt, TYPE a[][NUM], TYPE b[][NUM],
TYPE c[][NUM], TYPE t[][NUM]) {
int i, j, k;
// Declare a deviceQueue
sycl::default_selector device;
sycl::queue q(device, exception_handler);
cout << "Running on " << q.get_device().get_info<sycl::info::device::name>()
<< "\n";
// Declare a 2 dimensional range
sycl::range<2> matrix_range{NUM, NUM};
// Declare 3 buffers and Initialize them
sycl::buffer<TYPE, 2> bufferA((TYPE *)a, matrix_range);
sycl::buffer<TYPE, 2> bufferB((TYPE *)b, matrix_range);
sycl::buffer<TYPE, 2> bufferC((TYPE *)c, matrix_range);
// Submit our job to the queue
q.submit([&](auto &h) {
// Declare 3 accessors to our buffers. The first 2 read and the last
// read_write
sycl::accessor accessorA(bufferA, h, sycl::read_only);
sycl::accessor accessorB(bufferB, h, sycl::read_only);
sycl::accessor accessorC(bufferC, h);
// Execute matrix multiply in parallel over our matrix_range
// ind is an index into this range
h.parallel_for(matrix_range, [=](sycl::id<2> ind) {
int k;
TYPE acc = 0.0;
for (k = 0; k < NUM; k++) {
// Perform computation ind[0] is row, ind[1] is col
acc += accessorA[ind[0]][k] * accessorB[k][ind[1]];
}
accessorC[ind[0]][ind[1]] = acc;
});
}).wait_and_throw();
}
// Replaces accessorC reference with a local variable and adds matrix tiling
void multiply1_2(int msize, int tidx, int numt, TYPE a[][NUM], TYPE b[][NUM],
TYPE c[][NUM], TYPE t[][NUM]) {
int i, j, k;
// Declare a deviceQueue
sycl::default_selector device;
sycl::queue q(device, exception_handler);
cout << "Running on " << q.get_device().get_info<sycl::info::device::name>()
<< "\n";
// Declare a 2 dimensional range
sycl::range<2> matrix_range{NUM, NUM};
sycl::range<2> tile_range{MATRIXTILESIZE, MATRIXTILESIZE};
// Declare 3 buffers and Initialize them
sycl::buffer<TYPE, 2> bufferA((TYPE *)a, matrix_range);
sycl::buffer<TYPE, 2> bufferB((TYPE *)b, matrix_range);
sycl::buffer<TYPE, 2> bufferC((TYPE *)c, matrix_range);
// Submit our job to the queue
q.submit([&](auto &h) {
// Declare 3 accessors to our buffers. The first 2 read and the last
// read_write
sycl::accessor accessorA(bufferA, h, sycl::read_only);
sycl::accessor accessorB(bufferB, h, sycl::read_only);
sycl::accessor accessorC(bufferC, h);
// Create matrix tiles
sycl::accessor<TYPE, 2, sycl::access::mode::read_write,
sycl::access::target::local>
aTile(sycl::range<2>(MATRIXTILESIZE, MATRIXTILESIZE), h);
sycl::accessor<TYPE, 2, sycl::access::mode::read_write,
sycl::access::target::local>
bTile(sycl::range<2>(MATRIXTILESIZE, MATRIXTILESIZE), h);
// Execute matrix multiply in parallel over our matrix_range
// ind is an index into this range
h.parallel_for(sycl::nd_range<2>(matrix_range, tile_range),
[=](cl::sycl::nd_item<2> it) {
int k;
const int numTiles = NUM / MATRIXTILESIZE;
const int row = it.get_local_id(0);
const int col = it.get_local_id(1);
const int globalRow =
MATRIXTILESIZE * it.get_group(0) + row;
const int globalCol =
MATRIXTILESIZE * it.get_group(1) + col;
TYPE acc = 0.0;
for (int t = 0; t < numTiles; t++) {
const int tiledRow = MATRIXTILESIZE * t + row;
const int tiledCol = MATRIXTILESIZE * t + col;
aTile[row][col] = accessorA[globalRow][tiledCol];
bTile[row][col] = accessorB[tiledRow][globalCol];
it.barrier(sycl::access::fence_space::local_space);
for (k = 0; k < MATRIXTILESIZE; k++) {
// Perform computation ind[0] is row, ind[1] is col
acc += aTile[row][k] * bTile[k][col];
}
it.barrier(sycl::access::fence_space::local_space);
}
accessorC[globalRow][globalCol] = acc;
});
}).wait_and_throw();
} // multiply1_2
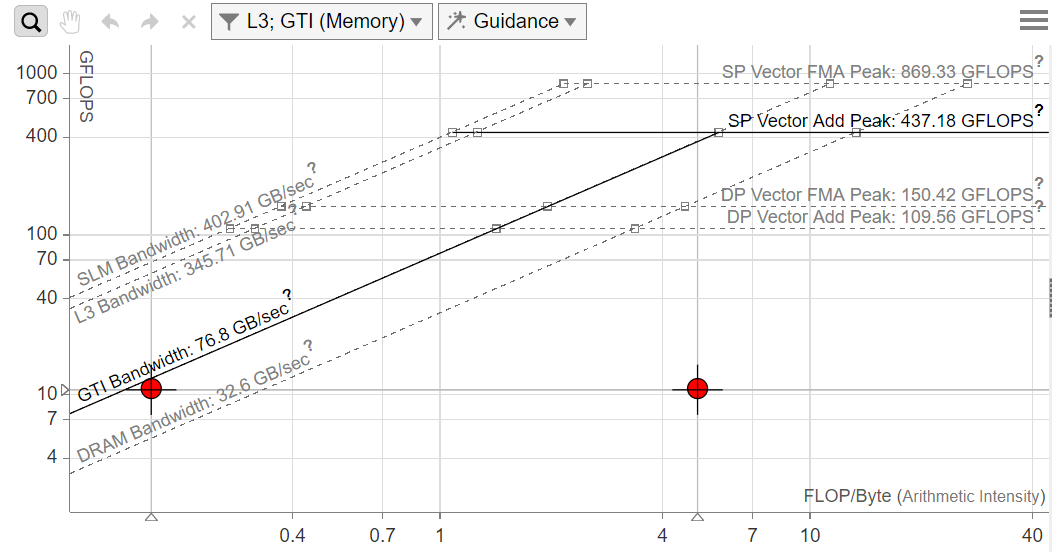
Save the optimized version as multiply_1_2 and rerun the GPU Roofline. As the new chart shows:
The optimized application gets 19.985 GFLOPS.
The application uses global and SLM memory, which represents the 16x16 tile. This increases memory bandwidth.
GPU Roofline new chart