A newer version of this document is available. Customers should click here to go to the newest version.
Visible to Intel only — GUID: GUID-96DC486F-10DE-4D02-A27D-4507DFD47EC3
Visible to Intel only — GUID: GUID-96DC486F-10DE-4D02-A27D-4507DFD47EC3
Identify Regions to Offload to GPU with Offload Modeling
The Offload Modeling feature, a part of Intel Advisor, can be used to:
Identify the portions of a code that can profitably be offloaded to a GPU.
Predict the code’s performance if run on a GPU.
Experiment with accelerator configuration parameters.
Offload Modeling produces upper-bound speedup estimates using a bounds-and-bottlenecks performance model. It takes measured x86 CPU metrics and application characteristics as an input and applies an analytical model to estimate execution time and characteristics on a target GPU.
You can run the Offload Modeling perspective from the Intel Advisor GUI by using the advisor command line interface, or by using the dedicated Python* scripts delivered with the Intel Advisor. This topic describes how to run Offload Modeling with the scripts. For detailed description of other ways to run the perspective, see the Intel Advisor User Guide.
To run Offload Modeling for a C++ Matrix Multiply application on Linux* OS:
Collect application performance metrics with collect.py:
advisor-python $APM/collect.py ./advisor_project --config gen9_gt2 -- matrix_multiply
Model your application performance on a GPU with analyze.py:
advisor-python $APM/analyze.py ./advisor_project --config gen9_gt2
Once you have run the performance modeling, you can open the results in the Intel Advisor GUI or see CSV metric reports and an interactive HTML report generated in the advisor_project/e000/pp000/data.0
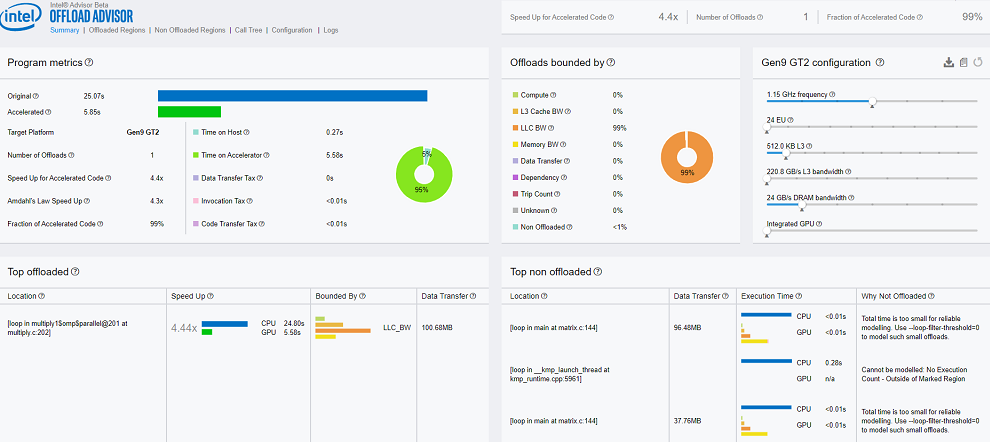
For example, in the Summary section of the report, review the following:
The original execution time on a CPU, the predicted execution time on a GPU accelerator, the number of offloaded regions, and the estimated speedup in the Program metrics pane. For Matrix Multiply, Intel Advisor reports a 4.4x potential speedup.
What the offloads are bounded by. This pane reports the main limiting factors that prevent your application from achieving better performance on a target device. The Matrix Multiply application is 99% bounded by last level cache (LLC) cache bandwidth.
Exact source lines of the Top Offloaded code regions that can benefit from offloading to the GPU and estimated performance of each code region. For Matrix Multiply, there is one code region recommended for offloading.
Exact source lines of the Top Non-Offloaded code regions that are not recommended for offloading and specific reasons for it.
Go to the Offloaded Regions tab to view the detailed measured and estimated metrics for the code regions recommended for offloading. It also reports the estimated amount of data transferred for the code regions and the corresponding offload taxes.
Use the data in the report to decide what regions of your code to port to SYCL. For example, you can port the C++ Matrix Multiply application to SYCL as follows:
// Basic matrix multiply
void multiply1(int msize, int tidx, int numt, TYPE a[][NUM], TYPE b[][NUM],
TYPE c[][NUM], TYPE t[][NUM]) {
int i, j, k;
// Declare a deviceQueue
sycl::default_selector device;
sycl::queue q(device, exception_handler);
cout << "Running on " << q.get_device().get_info<sycl::info::device::name>()
<< "\n";
// Declare a 2 dimensional range
sycl::range<2> matrix_range{NUM, NUM};
// Declare 3 buffers and Initialize them
sycl::buffer<TYPE, 2> bufferA((TYPE *)a, matrix_range);
sycl::buffer<TYPE, 2> bufferB((TYPE *)b, matrix_range);
sycl::buffer<TYPE, 2> bufferC((TYPE *)c, matrix_range);
// Submit our job to the queue
q.submit([&](auto &h) {
// Declare 3 accessors to our buffers. The first 2 read and the last
// read_write
sycl::accessor accessorA(bufferA, h, sycl::read_only);
sycl::accessor accessorB(bufferB, h, sycl::read_only);
sycl::accessor accessorC(bufferC, h);
// Execute matrix multiply in parallel over our matrix_range
// ind is an index into this range
h.parallel_for(matrix_range, [=](sycl::id<2> ind) {
int k;
for (k = 0; k < NUM; k++) {
// Perform computation ind[0] is row, ind[1] is col
accessorC[ind[0]][ind[1]] +=
accessorA[ind[0]][k] * accessorB[k][ind[1]];
}
});
}).wait_and_throw();
} // multiply1