Visible to Intel only — GUID: GUID-2C38F8AA-DDC4-4B9A-A9B8-ABCE044D3BD4
Introduction
Getting Started
Parallelization
Intel® Iris® Xe GPU Architecture
GPU Execution Model Overview
SYCL* Thread Mapping and GPU Occupancy
Kernels
Using Libraries for GPU Offload
Host/Device Memory, Buffer and USM
Host/Device Coordination
Using Multiple Heterogeneous Devices
Compilation
Optimizing Media Pipelines
OpenMP Offloading Tuning Guide
Debugging and Profiling
GPU Analysis with Intel® Graphics Performance Analyzers (Intel® GPA)
Reference
Terms and Conditions
Sub-groups and SIMD Vectorization
Removing Conditional Checks
Registerization and Avoid Register Spills
Shared Local Memory
Pointer Aliasing and the Restrict Directive
Synchronization among Threads in a Kernel
Considerations for Selecting Work-group Size
Reduction
Kernel Launch
Executing Multiple Kernels on the Device at the Same Time
Submitting Kernels to Multiple Queues
Avoid Redundant Queue Construction
Visible to Intel only — GUID: GUID-2C38F8AA-DDC4-4B9A-A9B8-ABCE044D3BD4
Optimizing Media Pipelines
Media operations are ideal candidates for hardware acceleration because they are relatively large algorithms with well-defined inputs and outputs. Video processing hardware capabilities can be accessed via industry-standard frameworks, oneVPL, or low-level/operating system specific approaches like Video Acceleration API (VA-API) for Linux or Microsoft* DirectX* for Windows. Which path to choose depends on many factors. However, the basic principles like parallelization by multiple streams and maximizing data locality apply for all options.
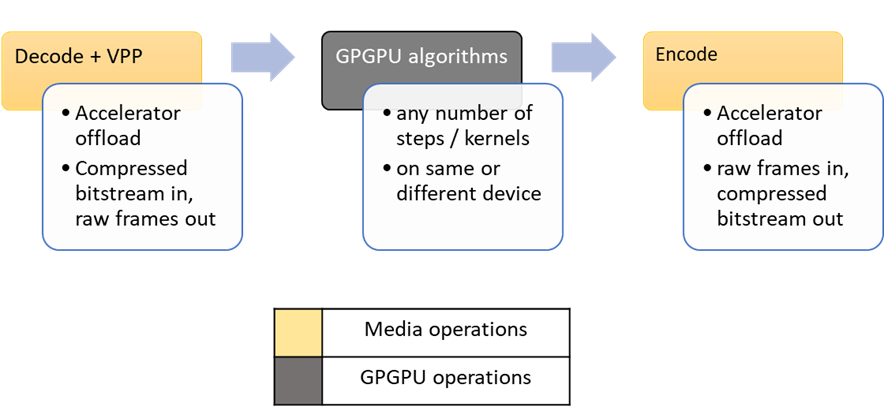
The main differences between video processing and GPGPU work apply to all accelerator API options. Many typical GPGPU optimizations focus on optimizing how large grids of work are partitioned across multiple processing units. Hardware-accelerated media operations are implemented in silicon. They work in units of frames and usually work is partitioned by streams of frames.
Media optimization steps don’t match the GPGPU workflow described in other sections. However, they can be easily added before or after GPGPU work. Media steps will supply inputs to or take outputs from GPGPU steps. For example:
- Media Engine Hardware
- Media API Options for Hardware Acceleration
- Media Pipeline Parallelism
- Media Pipeline Inter-operation and Memory Sharing
- SYCL-Blur Example
Video streaming is prevalent in our world today. We stream meetings at work. We watch movies at home. We expect good quality. Taking advantage of this new media engine hardware gives you the option to stream faster, stream at higher quality and/or stream at lower power. This hardware solution is an important consideration for End-to-End performance in pipelines working with video data.