Visible to Intel only — GUID: GUID-1E5C67F9-803A-4157-B685-FB662C170D45
Abs
AbsBackward
Add
AvgPool
AvgPoolBackward
BatchNormForwardTraining
BatchNormInference
BatchNormTrainingBackward
BiasAdd
BiasAddBackward
Clamp
ClampBackward
Concat
Convolution
ConvolutionBackwardData
ConvolutionBackwardWeights
ConvTranspose
ConvTransposeBackwardData
ConvTransposeBackwardWeights
Dequantize
Divide
DynamicDequantize
DynamicQuantize
Elu
EluBackward
End
Exp
GELU
GELUBackward
HardSigmoid
HardSigmoidBackward
HardSwish
HardSwishBackward
Interpolate
InterpolateBackward
LayerNorm
LayerNormBackward
LeakyReLU
Log
LogSoftmax
LogSoftmaxBackward
MatMul
Maximum
MaxPool
MaxPoolBackward
Minimum
Mish
MishBackward
Multiply
Pow
PReLU
PReLUBackward
Quantize
Reciprocal
ReduceL1
ReduceL2
ReduceMax
ReduceMean
ReduceMin
ReduceProd
ReduceSum
ReLU
ReLUBackward
Reorder
Round
Select
Sigmoid
SigmoidBackward
SoftMax
SoftMaxBackward
SoftPlus
SoftPlusBackward
Sqrt
SqrtBackward
Square
SquaredDifference
StaticReshape
StaticTranspose
Subtract
Tanh
TanhBackward
TypeCast
Wildcard
enum dnnl_alg_kind_t
enum dnnl_normalization_flags_t
enum dnnl_primitive_kind_t
enum dnnl_prop_kind_t
enum dnnl_query_t
enum dnnl::normalization_flags
enum dnnl::query
struct dnnl_exec_arg_t
struct dnnl_primitive
struct dnnl_primitive_desc
struct dnnl::primitive
struct dnnl::primitive_desc
struct dnnl::primitive_desc_base
enum dnnl_rnn_direction_t
enum dnnl_rnn_flags_t
enum dnnl::rnn_direction
enum dnnl::rnn_flags
struct dnnl::augru_backward
struct dnnl::augru_forward
struct dnnl::gru_backward
struct dnnl::gru_forward
struct dnnl::lbr_augru_backward
struct dnnl::lbr_augru_forward
struct dnnl::lbr_gru_backward
struct dnnl::lbr_gru_forward
struct dnnl::lstm_backward
struct dnnl::lstm_forward
struct dnnl::rnn_primitive_desc_base
struct dnnl::vanilla_rnn_backward
struct dnnl::vanilla_rnn_forward
Visible to Intel only — GUID: GUID-1E5C67F9-803A-4157-B685-FB662C170D45
Int8 Inference
Introduction
To push higher performance during inference computations, recent work has focused on computing at a lower precision (that is, shrinking the size of data for activations and weights) to achieve higher throughput. Eight-bit computations (referred to as int8) offer improved performance over higher-precision types because they enable packing more data into a single instruction, at the cost of reduced (but acceptable) accuracy.
Int8 Workflow
There are different ways to use lower precision to perform inference. The Primitive Attributes: Quantization page describes what kind of quantization model oneDNN supports.
Quantization Process
To operate with int8 data types from a higher-precision format (for example, 32-bit floating point), data must first be quantized. The quantization process converts a given input into a lower-precision format. The precision and accuracy factors are determined by the scaling factors.
Range of the Data
The data range is usually obtained by sampling the dataset of previous executions in the original data type (for example, the activations and weights from training in f32):
 .
.
Here is a tensor corresponding to either the weights or the activations. Establishing the range of values used in the computation, and selecting a proper scaling factor, prevents over- or underflows during computation of the lower-precision results.
Scaling Factor
The quantization factor is used to convert the original values into the corresponding int8 range and is calculated as:
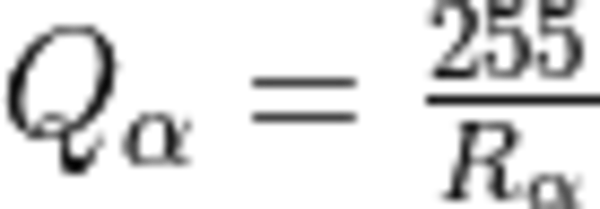 is the quantization factor for activations with non-negative values.
is the quantization factor for activations with non-negative values.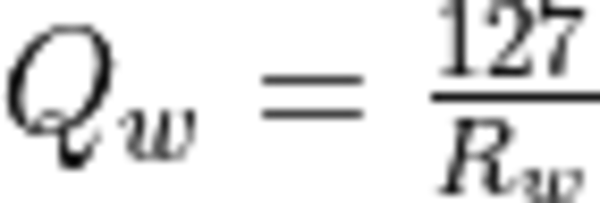 is the quantization factor for weights.
is the quantization factor for weights.
The quantized activation, weights, and bias values are calculated as:
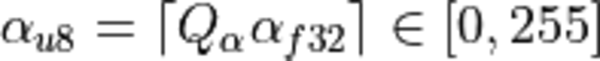 ,
,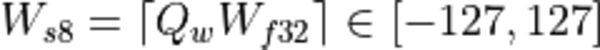 ,
,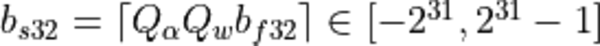 .
.
Here denotes rounding according to the active rounding mode (typically determined by the MXCSR register; the default value is RoundNearestEven).
When the destination value is stored as a signed 32-bit integer, the result is bound to the same quantization scaling factors :
- ,
where
.
Here the approximation is used to denote rounding.
The dequantized value is calculated as
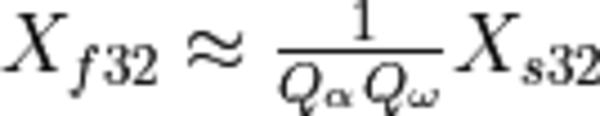 .
.
Quantization Example
To show how the quantization parameters are obtained, suppose we first start with a set of high-precision input and output values. These values come from sampling a previously executed training run and are stored as 32-bit floating point values:
activations:
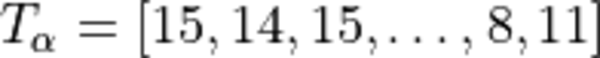 where
where 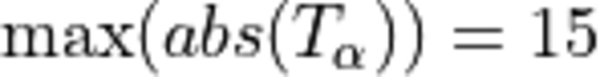
weights:
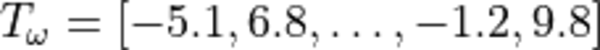 where
where 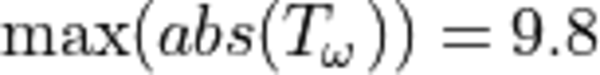
bias:
where 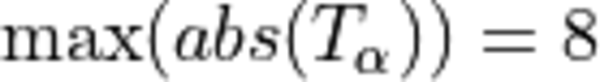
The scaling factors are:
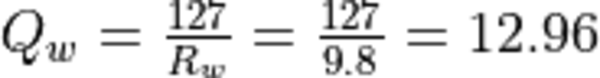
Finally, the quantized input values for the int8 operation are calculated as:
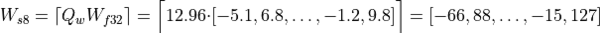
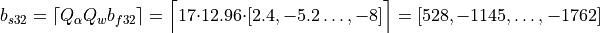
These arrays are the new inputs for the int8 net.
int8 Support
oneDNN supports int8 computations for inference by allowing one to specify that primitives’ input and output memory objects use int8 data types. int8 primitive implementations are optimized for high performance on the compatible hardware (see Data Types).
Attributes
Scaling factors and zero-points can be configured using primitive attributes”. It is also possible to specify fused post-ops. All primitives support the attributes, but not all combinations of parameters are supported. In the case of an unsupported combination, the library returns an error.
In oneDNN, the scaling factor are applied to each memory object of a primitive. Moreover, to perform input transformations (for example, source, bias, and weights), oneDNN performs quantizing and dequantizing of data for int8 using the reorder primitive.
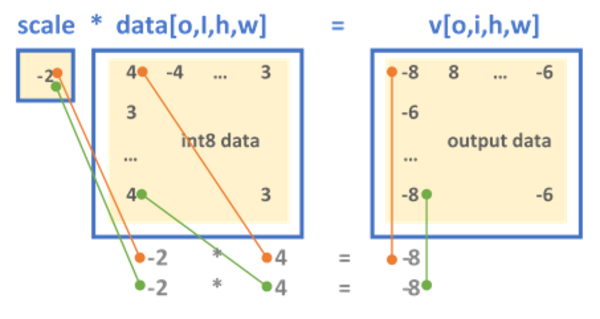
oneDNN has two formats for defining the quantization parameters. Depending on the configuration set by the scaling and zero-point masks, either the memory object is either scaled/shifted uniformly across all the dimensions (mask = 0) or a set of scaling values is applied to specific dimensions, as explained below:
A single floating point value shared across the tensor
An array of floating point values each corresponding to a specific dimension or set of dimensions
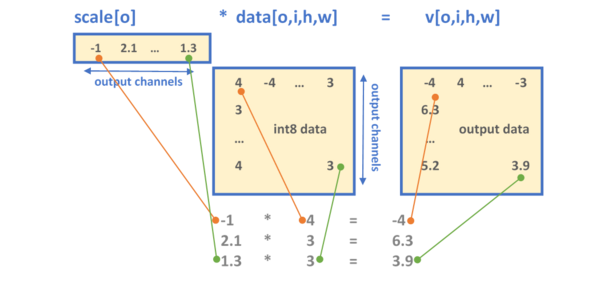
The mask parameter determines the dimension to which the scale or zero-point array is applied. The
-th bit of the mask selects the dimension 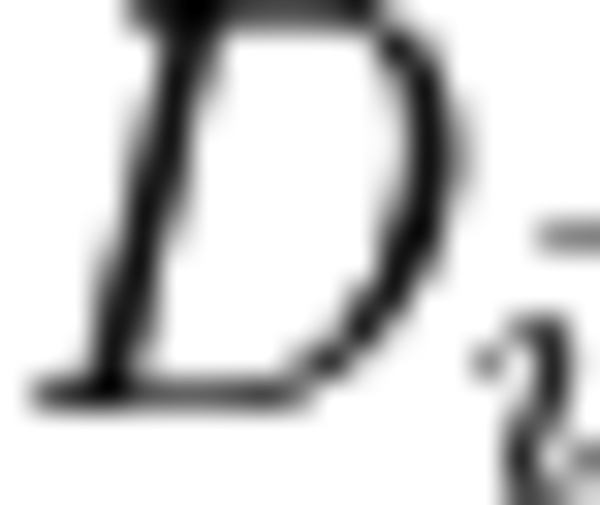 of an -dimensional tensor
of an -dimensional tensor  . For example:
. For example:The single scale/zero-point format always has mask = 0.
For a 5-dimensional tensor
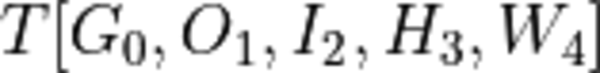 where the indices correspond to the positions of bits in the mask:
where the indices correspond to the positions of bits in the mask:A scale
selects the output channel for scaling.A scale
selects the group and output channels.
Fused post-ops allow chaining computations. Note that the resulting output value from post-ops is always affected by the scaling factor.
Example
CNN int8 inference example example walks through the steps of int8 inference.