Intel® oneAPI Deep Neural Network Developer Guide and Reference
A newer version of this document is available. Customers should click here to go to the newest version.
Reorder
General
The reorder primitive copies data between different memory formats but doesn’t change the tensor from mathematical perspective (the variable names follow the standard Naming Conventions):

As described in Basic Concepts in order to achieve the best performance some primitives (such as convolution) require special memory format which is typically referred to as an optimized memory format. The optimized memory format may match or may not match memory format that data is currently kept in. In this case a user can use reorder primitive to copy (reorder) the data between the memory formats.
Using the attributes and post-ops users can also use reorder primitive to quantize the data (and if necessary change the memory format simultaneously).
Execution Arguments
When executed, the inputs and outputs should be mapped to an execution argument index as specified by the following table.
Primitive input/output |
Execution argument index |
|---|---|
|
DNNL_ARG_FROM |
|
DNNL_ARG_TO |
|
DNNL_ARG_ATTR_SCALES | DNNL_ARG_FROM |
|
DNNL_ARG_ATTR_SCALES | DNNL_ARG_TO |
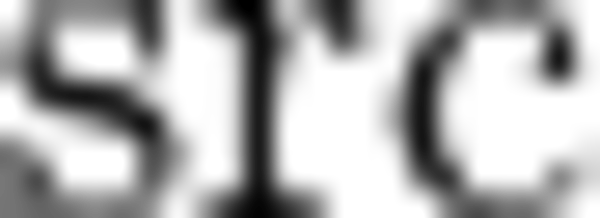
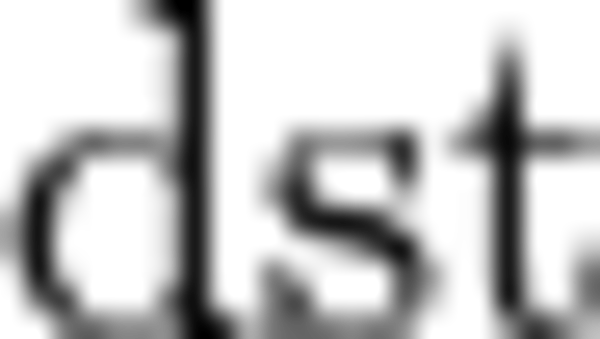
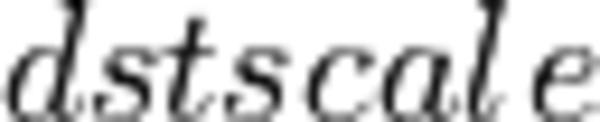
Implementation Details
General Notes
The reorder primitive requires the source and destination tensors to have the same shape. Implicit broadcasting is not supported.
While in most of the cases the reorder should be able to handle arbitrary source and destination memory formats and data types, it might happen than some combinations are not implemented. For instance:
Reorder implementations between weights in non-plain memory formats might be limited (but if encountered in real practice should be treated as a bug and reported to oneDNN team);
Weights in one Winograd format cannot be reordered to the weights of the other Winograd format;
Quantized weights for convolution with dnnl_s8 source data type cannot be dequantized back to the dnnl_f32 data type;
To alleviate the problem a user may rely on fact that the reorder from original plain memory format and user’s data type to the optimized format with chosen data type should be always implemented.
Data Types Support
The reorder primitive supports arbitrary data types for the source and destination according to the Data Types page.
When converting the data from one data type to a smaller one saturation is used. For instance:
reorder(src={1024, data_type=f32}, dst={, data_type=s8})
// dst == {127}
reorder(src={-124, data_type=f32}, dst={, data_type=u8})
// dst == {0}Data Representation
The reorder primitive works with arbitrary data tensors. There is no special meaning associated with any logical dimensions.
Post-Ops and Attributes
The reorder primitive support the following attributes and post-ops:
Attributes / Post-ops |
Meaning |
|---|---|
Scales the corresponding tensor by the given scale factor(s) |
|
Sets zero point(s) for the corresponding tensors |
|
Instead of copy the data accumulate it to the previous data |
For instance, the following pseudo-code
reorder(
src = {dims={N, C, H, W}, data_type=dt_src, memory_format=fmt_src},
dst = {dims={N, C, H, W}, data_type=dt_dst, memory_format=fmt_dst},
attr ={
scales={ src={mask=0} },
zero_points= { src={mask=0}, dst={mask=0} },
post-ops = { sum={scale=beta} },
})would lead to the following operation:
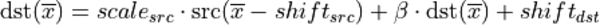
- The intermediate operations are being done using single precision floating point data type.
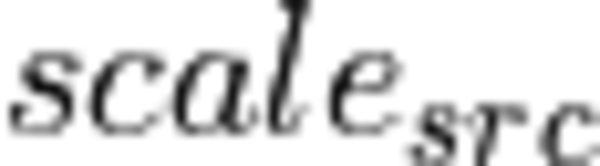 and
and 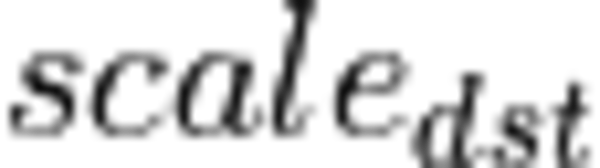 must be passed during execution runtime as a separate memory argument. Using argument will lead to multiplication of tensor values by a scale value. Using argument will lead to division of tensor values by a scale value.
must be passed during execution runtime as a separate memory argument. Using argument will lead to multiplication of tensor values by a scale value. Using argument will lead to division of tensor values by a scale value.
Implementation Limitations
Refer to Data Types for limitations related to data types support.
CPU
Reorders between bf16, f16 and s32 data types are not supported.
GPU
Only tensors of 6 or fewer dimensions are supported.
Runtime dimensions are not supported.
Performance Tips
N/A
Example
This C++ API demonstrates how to create and execute a Reorder primitive.
Key optimizations included in this example:
Primitive attributes for output scaling.