Visible to Intel only — GUID: GUID-22C6F8F6-78FC-42FD-87F2-FE744935FF54
Abs
AbsBackward
Add
AvgPool
AvgPoolBackward
BatchNormForwardTraining
BatchNormInference
BatchNormTrainingBackward
BiasAdd
BiasAddBackward
Clamp
ClampBackward
Concat
Convolution
ConvolutionBackwardData
ConvolutionBackwardWeights
ConvTranspose
ConvTransposeBackwardData
ConvTransposeBackwardWeights
Dequantize
Divide
DynamicDequantize
DynamicQuantize
Elu
EluBackward
End
Exp
GELU
GELUBackward
HardSigmoid
HardSigmoidBackward
HardSwish
HardSwishBackward
Interpolate
InterpolateBackward
LayerNorm
LayerNormBackward
LeakyReLU
Log
LogSoftmax
LogSoftmaxBackward
MatMul
Maximum
MaxPool
MaxPoolBackward
Minimum
Mish
MishBackward
Multiply
Pow
PReLU
PReLUBackward
Quantize
Reciprocal
ReduceL1
ReduceL2
ReduceMax
ReduceMean
ReduceMin
ReduceProd
ReduceSum
ReLU
ReLUBackward
Reorder
Round
Select
Sigmoid
SigmoidBackward
SoftMax
SoftMaxBackward
SoftPlus
SoftPlusBackward
Sqrt
SqrtBackward
Square
SquaredDifference
StaticReshape
StaticTranspose
Subtract
Tanh
TanhBackward
TypeCast
Wildcard
enum dnnl_alg_kind_t
enum dnnl_normalization_flags_t
enum dnnl_primitive_kind_t
enum dnnl_prop_kind_t
enum dnnl_query_t
enum dnnl::normalization_flags
enum dnnl::query
struct dnnl_exec_arg_t
struct dnnl_primitive
struct dnnl_primitive_desc
struct dnnl::primitive
struct dnnl::primitive_desc
struct dnnl::primitive_desc_base
enum dnnl_rnn_direction_t
enum dnnl_rnn_flags_t
enum dnnl::rnn_direction
enum dnnl::rnn_flags
struct dnnl::augru_backward
struct dnnl::augru_forward
struct dnnl::gru_backward
struct dnnl::gru_forward
struct dnnl::lbr_augru_backward
struct dnnl::lbr_augru_forward
struct dnnl::lbr_gru_backward
struct dnnl::lbr_gru_forward
struct dnnl::lstm_backward
struct dnnl::lstm_forward
struct dnnl::rnn_primitive_desc_base
struct dnnl::vanilla_rnn_backward
struct dnnl::vanilla_rnn_forward
Visible to Intel only — GUID: GUID-22C6F8F6-78FC-42FD-87F2-FE744935FF54
CNN int8 inference example
This C++ API example demonstrates how to run AlexNet’s conv3 and relu3 with int8 data type.
This C++ API example demonstrates how to run AlexNet’s conv3 and relu3 with int8 data type.
Example code: cnn_inference_int8.cpp
Configure tensor shapes
// AlexNet: conv3
// {batch, 256, 13, 13} (x) {384, 256, 3, 3}; -> {batch, 384, 13, 13}
// strides: {1, 1}
memory::dims conv_src_tz = {batch, 256, 13, 13};
memory::dims conv_weights_tz = {384, 256, 3, 3};
memory::dims conv_bias_tz = {384};
memory::dims conv_dst_tz = {batch, 384, 13, 13};
memory::dims conv_strides = {1, 1};
memory::dims conv_padding = {1, 1};Next, the example configures the scales used to quantize f32 data into int8. For this example, the scaling value is chosen as an arbitrary number, although in a realistic scenario, it should be calculated from a set of precomputed values as previously mentioned.
// Choose scaling factors for input, weight and output
std::vector<float> src_scales = {1.8f};
std::vector<float> weight_scales = {2.0f};
std::vector<float> dst_scales = {0.55f};The source, weights, bias and destination datasets use the single-scale format with mask set to ‘0’.
const int src_mask = 0;
const int weight_mask = 0;
const int dst_mask = 0;Create the memory primitives for user data (source, weights, and bias). The user data will be in its original 32-bit floating point format.
auto user_src_memory = memory({{conv_src_tz}, dt::f32, tag::nchw}, eng);
write_to_dnnl_memory(user_src.data(), user_src_memory);
auto user_weights_memory
= memory({{conv_weights_tz}, dt::f32, tag::oihw}, eng);
write_to_dnnl_memory(conv_weights.data(), user_weights_memory);
auto user_bias_memory = memory({{conv_bias_tz}, dt::f32, tag::x}, eng);
write_to_dnnl_memory(conv_bias.data(), user_bias_memory);Create a memory descriptor for each convolution parameter. The convolution data uses 8-bit integer values, so the memory descriptors are configured as:
8-bit unsigned (u8) for source and destination.
8-bit signed (s8) for bias and weights.
Note The destination type is chosen as unsigned because the convolution applies a ReLU operation where data results 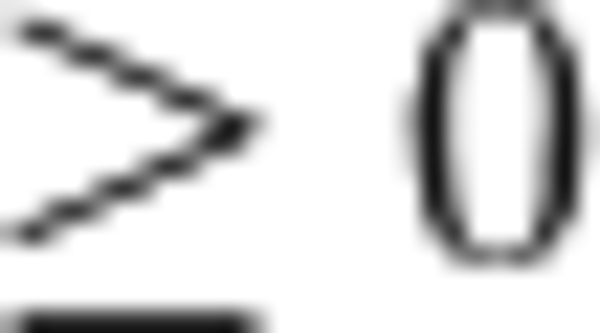 .
.
auto conv_src_md = memory::desc({conv_src_tz}, dt::u8, tag::any);
auto conv_bias_md = memory::desc({conv_bias_tz}, dt::s8, tag::any);
auto conv_weights_md = memory::desc({conv_weights_tz}, dt::s8, tag::any);
auto conv_dst_md = memory::desc({conv_dst_tz}, dt::u8, tag::any);Configuring int8-specific parameters in an int8 primitive is done via the Attributes Primitive. Create an attributes object for the convolution and configure it accordingly.
primitive_attr conv_attr;
conv_attr.set_scales_mask(DNNL_ARG_SRC, src_mask);
conv_attr.set_scales_mask(DNNL_ARG_WEIGHTS, weight_mask);
conv_attr.set_scales_mask(DNNL_ARG_DST, dst_mask);
// Prepare dst scales
auto dst_scale_md = memory::desc({1}, dt::f32, tag::x);
auto dst_scale_memory = memory(dst_scale_md, eng);
write_to_dnnl_memory(dst_scales.data(), dst_scale_memory);The ReLU layer from Alexnet is executed through the PostOps feature. Create a PostOps object and configure it to execute an eltwise relu operation.
const float ops_alpha = 0.f; // relu negative slope
const float ops_beta = 0.f;
post_ops ops;
ops.append_eltwise(algorithm::eltwise_relu, ops_alpha, ops_beta);
conv_attr.set_post_ops(ops);Create a primitive descriptor passing the int8 memory descriptors and int8 attributes to the constructor. The primitive descriptor for the convolution will contain the specific memory formats for the computation.
auto conv_prim_desc = convolution_forward::primitive_desc(eng,
prop_kind::forward, algorithm::convolution_direct, conv_src_md,
conv_weights_md, conv_bias_md, conv_dst_md, conv_strides,
conv_padding, conv_padding, conv_attr);Create a memory for each of the convolution’s data input parameters (source, bias, weights, and destination). Using the convolution primitive descriptor as the creation parameter enables oneDNN to configure the memory formats for the convolution.
Scaling parameters are passed to the reorder primitive via the attributes primitive.
User memory must be transformed into convolution-friendly memory (for int8 and memory format). A reorder layer performs the data transformation from f32 (the original user data) into int8 format (the data used for the convolution). In addition, the reorder transforms the user data into the required memory format (as explained in the simple_net example).
auto conv_src_memory = memory(conv_prim_desc.src_desc(), eng);
primitive_attr src_attr;
src_attr.set_scales_mask(DNNL_ARG_DST, src_mask);
auto src_scale_md = memory::desc({1}, dt::f32, tag::x);
auto src_scale_memory = memory(src_scale_md, eng);
write_to_dnnl_memory(src_scales.data(), src_scale_memory);
auto src_reorder_pd
= reorder::primitive_desc(eng, user_src_memory.get_desc(), eng,
conv_src_memory.get_desc(), src_attr);
auto src_reorder = reorder(src_reorder_pd);
src_reorder.execute(s,
{{DNNL_ARG_FROM, user_src_memory}, {DNNL_ARG_TO, conv_src_memory},
{DNNL_ARG_ATTR_SCALES | DNNL_ARG_DST, src_scale_memory}});
auto conv_weights_memory = memory(conv_prim_desc.weights_desc(), eng);
primitive_attr weight_attr;
weight_attr.set_scales_mask(DNNL_ARG_DST, weight_mask);
auto wei_scale_md = memory::desc({1}, dt::f32, tag::x);
auto wei_scale_memory = memory(wei_scale_md, eng);
write_to_dnnl_memory(weight_scales.data(), wei_scale_memory);
auto weight_reorder_pd
= reorder::primitive_desc(eng, user_weights_memory.get_desc(), eng,
conv_weights_memory.get_desc(), weight_attr);
auto weight_reorder = reorder(weight_reorder_pd);
weight_reorder.execute(s,
{{DNNL_ARG_FROM, user_weights_memory},
{DNNL_ARG_TO, conv_weights_memory},
{DNNL_ARG_ATTR_SCALES | DNNL_ARG_DST, wei_scale_memory}});
auto conv_bias_memory = memory(conv_prim_desc.bias_desc(), eng);
write_to_dnnl_memory(conv_bias.data(), conv_bias_memory);Create the convolution primitive and add it to the net. The int8 example computes the same Convolution +ReLU layers from AlexNet simple-net.cpp using the int8 and PostOps approach. Although performance is not measured here, in practice it would require less computation time to achieve similar results.
auto conv = convolution_forward(conv_prim_desc);
conv.execute(s,
{{DNNL_ARG_SRC, conv_src_memory},
{DNNL_ARG_WEIGHTS, conv_weights_memory},
{DNNL_ARG_BIAS, conv_bias_memory},
{DNNL_ARG_DST, conv_dst_memory},
{DNNL_ARG_ATTR_SCALES | DNNL_ARG_SRC, src_scale_memory},
{DNNL_ARG_ATTR_SCALES | DNNL_ARG_WEIGHTS, wei_scale_memory},
{DNNL_ARG_ATTR_SCALES | DNNL_ARG_DST, dst_scale_memory}});Finally, dst memory may be dequantized from int8 into the original f32 format. Create a memory primitive for the user data in the original 32-bit floating point format and then apply a reorder to transform the computation output data.
auto user_dst_memory = memory({{conv_dst_tz}, dt::f32, tag::nchw}, eng);
write_to_dnnl_memory(user_dst.data(), user_dst_memory);
primitive_attr dst_attr;
dst_attr.set_scales_mask(DNNL_ARG_SRC, dst_mask);
auto dst_reorder_pd
= reorder::primitive_desc(eng, conv_dst_memory.get_desc(), eng,
user_dst_memory.get_desc(), dst_attr);
auto dst_reorder = reorder(dst_reorder_pd);
dst_reorder.execute(s,
{{DNNL_ARG_FROM, conv_dst_memory}, {DNNL_ARG_TO, user_dst_memory},
{DNNL_ARG_ATTR_SCALES | DNNL_ARG_SRC, dst_scale_memory}});[Dequantize the result]