Visible to Intel only — GUID: GUID-BD4090BA-6EF3-4F76-B986-E69067B0B30C
Abs
AbsBackward
Add
AvgPool
AvgPoolBackward
BatchNormForwardTraining
BatchNormInference
BatchNormTrainingBackward
BiasAdd
BiasAddBackward
Clamp
ClampBackward
Concat
Convolution
ConvolutionBackwardData
ConvolutionBackwardWeights
ConvTranspose
ConvTransposeBackwardData
ConvTransposeBackwardWeights
Dequantize
Divide
DynamicDequantize
DynamicQuantize
Elu
EluBackward
End
Exp
GELU
GELUBackward
HardSigmoid
HardSigmoidBackward
HardSwish
HardSwishBackward
Interpolate
InterpolateBackward
LayerNorm
LayerNormBackward
LeakyReLU
Log
LogSoftmax
LogSoftmaxBackward
MatMul
Maximum
MaxPool
MaxPoolBackward
Minimum
Mish
MishBackward
Multiply
PReLU
PReLUBackward
Quantize
General
Operation attributes
Execution arguments
Supported data types
Reciprocal
ReduceL1
ReduceL2
ReduceMax
ReduceMean
ReduceMin
ReduceProd
ReduceSum
ReLU
ReLUBackward
Reorder
Round
Sigmoid
SigmoidBackward
Softmax
SoftmaxBackward
SoftPlus
SoftPlusBackward
Sqrt
SqrtBackward
Square
SquaredDifference
StaticReshape
StaticTranspose
Subtract
Tanh
TanhBackward
TypeCast
Wildcard
enum dnnl_alg_kind_t
enum dnnl_normalization_flags_t
enum dnnl_primitive_kind_t
enum dnnl_prop_kind_t
enum dnnl_query_t
enum dnnl::normalization_flags
enum dnnl::query
struct dnnl_exec_arg_t
struct dnnl_primitive
struct dnnl_primitive_desc
struct dnnl::primitive
struct dnnl::primitive_desc
struct dnnl::primitive_desc_base
enum dnnl_rnn_direction_t
enum dnnl_rnn_flags_t
enum dnnl::rnn_direction
enum dnnl::rnn_flags
struct dnnl::augru_backward
struct dnnl::augru_forward
struct dnnl::gru_backward
struct dnnl::gru_forward
struct dnnl::lbr_augru_backward
struct dnnl::lbr_augru_forward
struct dnnl::lbr_gru_backward
struct dnnl::lbr_gru_forward
struct dnnl::lstm_backward
struct dnnl::lstm_forward
struct dnnl::rnn_primitive_desc_base
struct dnnl::vanilla_rnn_backward
struct dnnl::vanilla_rnn_forward
Visible to Intel only — GUID: GUID-BD4090BA-6EF3-4F76-B986-E69067B0B30C
Quantize
General
Quantize operation converts a f32 tensor to a quantized (u8/s8) tensor. It supports both per-tensor and per-channel asymmetric linear quantization. Output data type is specified in output tensor data type. Rounding mode is library-implementation defined.
For per-tensor quantization:
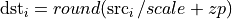
For per-channel quantization, taking channel axis = 1 as an example:
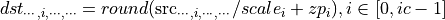
where  is the number of channels.
is the number of channels.
Operation attributes
Attribute Name |
Description |
Value Type |
Supported Values |
Required or Optional |
|---|---|---|---|---|
Specifies which quantization type is used. |
string |
per_tensor (default), per_channel |
Optional |
|
Specifies dimension on which per-channel quantization is applied. |
s64 |
A s64 value in the range of [-r, r-1] where r = rank(src), 1 by default |
Optional |
|
Scalings applied on the src data. |
f32 |
A f32 list (only contain one element if qtype is per_tensor ) |
Required |
|
Offset values that maps to float zero. |
s64 |
A s64 list (only contain one element if qtype is per_tensor ) |
Required |
Execution arguments
The inputs and outputs must be provided according to below index order when constructing an operation.
Inputs
Index |
Argument Name |
Required or Optional |
|---|---|---|
0 |
src |
Required |
Outputs
Index |
Argument Name |
Required or Optional |
|---|---|---|
0 |
dst |
Required |
Supported data types
Quantize operation supports the following data type combinations.
Src |
Dst |
|---|---|
f32 |
s8, u8 |
NOTE:
This operation is to support int8 quantization model.