Visible to Intel only — GUID: GUID-CE39C976-F535-4C27-99E8-5832AF026926
Why is FPGA Compilation Different?
Types of SYCL* FPGA Compilation
FPGA Compilation Flags
Emulate and Debug Your Design
Evaluate Your Kernel Through Simulation
Device Selectors for FPGA
FPGA IP Authoring Flow
Fast Recompile for FPGA
Generate Multiple FPGA Images (Linux only)
FPGA BSPs and Boards
Targeting Multiple Homogeneous FPGA Devices
Targeting Multiple Platforms
FPGA-CPU Interaction
FPGA Performance Optimization
Use of RTL Libraries for FPGA
Use SYCL Shared Library With Third-Party Applications
FPGA Workflows in IDEs
Intel oneAPI DPC++ Library (oneDPL)
Intel oneAPI Math Kernel Library (oneMKL)
Intel oneAPI Threading Building Blocks (oneTBB)
Intel oneAPI Data Analytics Library (oneDAL)
Intel oneAPI Collective Communications Library (oneCCL)
Intel oneAPI Deep Neural Network Library (oneDNN)
Intel oneAPI Video Processing Library (oneVPL)
Other Libraries
Visible to Intel only — GUID: GUID-CE39C976-F535-4C27-99E8-5832AF026926
SYCL* Thread and Memory Hierarchy
Thread Hierarchy
The SYCL* execution model exposes an abstract view of GPU execution. The SYCL thread hierarchy consists of a 1-, 2-, or 3-dimensional grid of work-items. These work-items are grouped into equal sized thread groups called work-groups. Threads in a work-group are further divided into equal sized vector groups called sub-groups.
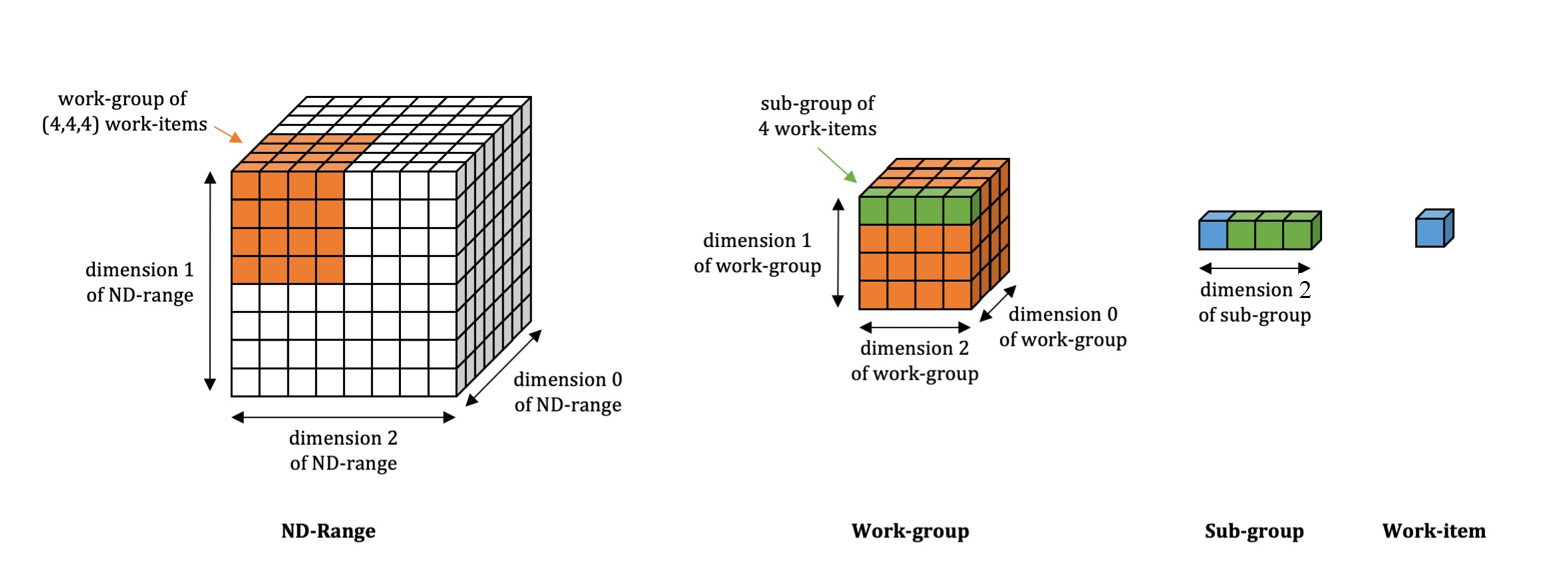
To learn more about how this hierarchy works with a GPUor a CPU with Intel® UHD Graphics, see SYCL* Thread Mapping and GPU Occupancy in the oneAPI GPU Optimization Guide.
Memory Hierarchy
The General Purpose GPU (GPGPU) compute model consists of a host connected to one or more compute devices. Each compute device consists of many GPU Compute Engines (CE), also known as Execution Units (EU) or Xe Vector Engines (XVE). The compute devices may also include caches, shared local memory (SLM), high-bandwidth memory (HBM), and so on, as shown in the figure below. Applications are then built as a combination of host software (per the host framework) and kernels submitted by the host to run on the VEs with a predefined decoupling point.
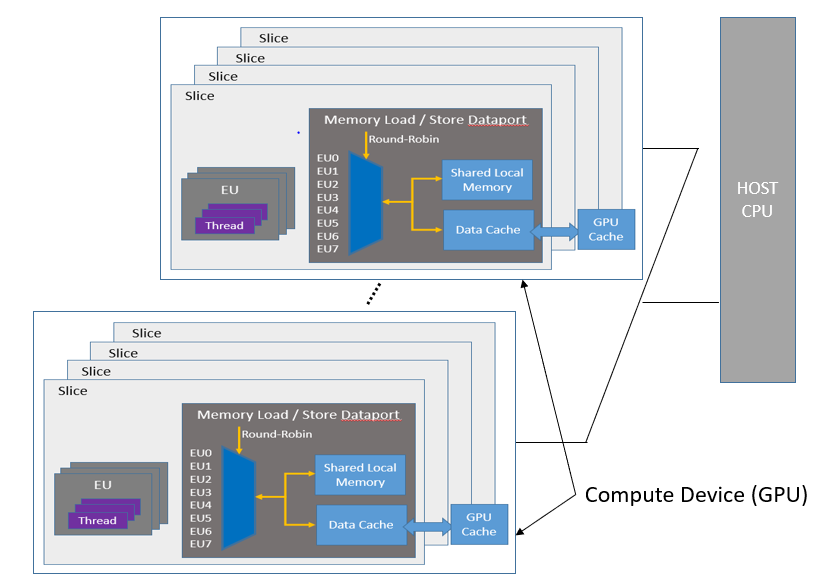
To learn more about memory hierarchy within the General Purpose GPU (GPGPU) compute model, see Execution Model Overview in the oneAPI GPU Optimization Guide.