Visible to Intel only — GUID: GUID-9D7B2EF7-D3C2-4AF8-B16A-C2773945BBFE
Execution Model Overview
Thread Mapping and GPU Occupancy
Kernels
Using Libraries for GPU Offload
Host/Device Memory, Buffer and USM
Unified Shared Memory Allocations
Performance Impact of USM and Buffers
Avoiding Moving Data Back and Forth between Host and Device
Optimizing Data Transfers
Avoiding Declaring Buffers in a Loop
Buffer Accessor Modes
Host/Device Coordination
Using Multiple Heterogeneous Devices
Compilation
OpenMP Offloading Tuning Guide
Multi-GPU and Multi-Stack Architecture and Programming
Level Zero
Performance Profiling and Analysis
Configuring GPU Device
Sub-Groups and SIMD Vectorization
Removing Conditional Checks
Registers and Performance
Shared Local Memory
Pointer Aliasing and the Restrict Directive
Synchronization among Threads in a Kernel
Considerations for Selecting Work-Group Size
Tuning Kernels with Local and Global Work-group Sizes in OpenMP Offload Mode
Prefetch
Reduction
Kernel Launch
Executing Multiple Kernels on the Device at the Same Time
Submitting Kernels to Multiple Queues
Avoiding Redundant Queue Constructions
Programming Intel® XMX Using SYCL Joint Matrix Extension
Doing I/O in the Kernel
Optimizing Explicit SIMD Kernels
Visible to Intel only — GUID: GUID-9D7B2EF7-D3C2-4AF8-B16A-C2773945BBFE
Considerations for Selecting Work-Group Size
In SYCL you can select the work-group size for nd_range kernels. The size of work-group has important implications for utilization of the compute resources, vector lanes, and communication among the work-items. The work-items in the same work-group may have access to hardware resources like shared local memory and hardware synchronization capabilities that will allow them to run and communicate more efficiently than work-items across work-groups. So in general you should pick the maximum work-group size supported by the accelerator. The maximum work-group size can be queried by the call device::get_info<cl::sycl::info::device::max_work_group_size>().
To illustrate the impact of the choice of work-group size, consider the following reduction kernel, which goes through a large vector to add all the elements in it. The function that runs the kernels takes in the work-group-size and sub-group-size as arguments, which lets you run experiments with different values. The performance difference can be seen from the timings reported when the kernel is called with different values for work-group size.
void reduction(sycl::queue &q, std::vector<int> &data, std::vector<int> &flush,
int iter, int work_group_size) {
const size_t data_size = data.size();
const size_t flush_size = flush.size();
int sum = 0;
const sycl::property_list props = {sycl::property::buffer::use_host_ptr()};
// int vec_size =
// q.get_device().get_info<sycl::info::device::native_vector_width_int>();
int num_work_items = data_size / work_group_size;
sycl::buffer<int> buf(data.data(), data_size, props);
sycl::buffer<int> flush_buf(flush.data(), flush_size, props);
sycl::buffer<int> sum_buf(&sum, 1, props);
init_data(q, buf, data_size);
double elapsed = 0;
for (int i = 0; i < iter; i++) {
q.submit([&](auto &h) {
sycl::accessor sum_acc(sum_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(1, [=](auto index) { sum_acc[index] = 0; });
});
// flush the cache
q.submit([&](auto &h) {
sycl::accessor flush_acc(flush_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(flush_size, [=](auto index) { flush_acc[index] = 1; });
});
Timer timer;
// reductionMapToHWVector main begin
q.submit([&](auto &h) {
sycl::accessor buf_acc(buf, h, sycl::read_only);
sycl::local_accessor<int, 1> scratch(work_group_size, h);
sycl::accessor sum_acc(sum_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(
sycl::nd_range<1>(num_work_items, work_group_size),
[=](sycl::nd_item<1> item) [[intel::reqd_sub_group_size(16)]] {
auto v =
sycl::atomic_ref<int, sycl::memory_order::relaxed,
sycl::memory_scope::device,
sycl::access::address_space::global_space>(
sum_acc[0]);
int sum = 0;
int glob_id = item.get_global_id();
int loc_id = item.get_local_id();
for (unsigned int i = glob_id; i < data_size; i += num_work_items)
sum += buf_acc[i];
scratch[loc_id] = sum;
for (int i = work_group_size / 2; i > 0; i >>= 1) {
item.barrier(sycl::access::fence_space::local_space);
if (loc_id < i)
scratch[loc_id] += scratch[loc_id + i];
}
if (loc_id == 0)
v.fetch_add(scratch[0]);
});
});
q.wait();
elapsed += timer.Elapsed();
sycl::host_accessor h_acc(sum_buf);
sum = h_acc[0];
}
elapsed = elapsed / iter;
std::string msg = "with work-groups=" + std::to_string(work_group_size);
check_result(elapsed, msg, sum);
} // reduction end
In the code below, the above kernel is called with two different values: 2*vec-size and the maximum possible work-group size supported by the accelerator. The performance of the kernel when work-group size is equal to 2*vec-size will be lower than when the work-group size is the maximum possible value.
int vec_size = 16;
int work_group_size = vec_size;
reduction(q, data, extra, 16, work_group_size);
work_group_size =
q.get_device().get_info<sycl::info::device::max_work_group_size>();
reduction(q, data, extra, 16, work_group_size);
In situations where there are no barriers nor atomics used, the work-group size will not impact the performance. To illustrate this, consider the following vec_copy kernel where there are no atomics or barriers.
void vec_copy(sycl::queue &q, std::vector<int> &src, std::vector<int> &dst,
std::vector<int> &flush, int iter, int work_group_size) {
const size_t data_size = src.size();
const size_t flush_size = flush.size();
const sycl::property_list props = {sycl::property::buffer::use_host_ptr()};
int num_work_items = data_size;
double elapsed = 0;
{
sycl::buffer<int> src_buf(src.data(), data_size, props);
sycl::buffer<int> dst_buf(dst.data(), data_size, props);
sycl::buffer<int> flush_buf(flush.data(), flush_size, props);
for (int i = 0; i < iter; i++) {
// flush the cache
q.submit([&](auto &h) {
sycl::accessor flush_acc(flush_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(flush_size, [=](auto index) { flush_acc[index] = 1; });
});
Timer timer;
q.submit([&](auto &h) {
sycl::accessor src_acc(src_buf, h, sycl::read_only);
sycl::accessor dst_acc(dst_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(sycl::nd_range<1>(num_work_items, work_group_size),
[=](sycl::nd_item<1> item)
[[intel::reqd_sub_group_size(16)]] {
int glob_id = item.get_global_id();
dst_acc[glob_id] = src_acc[glob_id];
});
});
q.wait();
elapsed += timer.Elapsed();
}
}
elapsed = elapsed / iter;
std::string msg = "with work-group-size=" + std::to_string(work_group_size);
check_result(elapsed, msg, dst);
} // vec_copy end
In the code below, the above kernel is called with different work-group sizes. All the above calls to the kernel will have similar run times which indicates that there is no impact of work-group size on performance. The reason for this is that the threads created within a work-group and threads from different work-groups behave in a similar manner from the scheduling and resourcing point of view when there are no barriers nor shared memory in the work-groups.
int vec_size = 16;
int work_group_size = vec_size;
vec_copy(q, src, dst, extra, 16, work_group_size);
work_group_size = 2 * vec_size;
vec_copy(q, src, dst, extra, 16, work_group_size);
work_group_size = 4 * vec_size;
vec_copy(q, src, dst, extra, 16, work_group_size);
work_group_size = 8 * vec_size;
vec_copy(q, src, dst, extra, 16, work_group_size);
work_group_size = 16 * vec_size;
vec_copy(q, src, dst, extra, 16, work_group_size);
In some accelerators, a minimum sub-group size is needed to obtain good performance due to the way in which threads are scheduled among the processing elements. In such a situation you may see a big performance difference when the number of sub-groups is less than the minimum. The call to the kernel on line 3 above has only one sub-group, while the call on line 5 has two sub-groups. There will be a significant performance difference in the timings for these two kernel invocations on an accelerator that performs scheduling of of two sub-groups at a time.
Tuning Kernels with Local and Global Work-group Sizes in OpenMP Offload Mode
The approach of tuning kernel performance on accelerator devices as explained above for SYCL, is also applicable for implementations via OpenMP in offload mode. It is possible to customize an application kernel along with the use of OpenMP directives to make use of appropriate work-group sizes. However, this may require significant modifications to the code. The OpenMP implementation provides an option to custom tune kernels with the use of environment variables. The local and global work-group sizes for kernels in an app can be customized with the the use of two environment variables – OMP_THREAD_LIMIT and OMP_NUM_TEAMS help in setting up the local work-group size (LWS) and global work-group size (GWS) as shown below:
LWS = OMP_THREAD_LIMIT
GWS = OMP_THREAD_LIMIT * OMP_NUM_TEAMSWith the help of following reduction kernel example, we show the use of LWS and GWS in tuning kernel performance on accelerator device.
int N = 2048;
double* A = make_array(N, 0.8);
double* B = make_array(N, 0.65);
double* C = make_array(N*N, 2.5);
if ((A == NULL) || (B == NULL) || (C == NULL))
exit(1);
int i, j;
double val = 0.0;
#pragma omp target map(to:A[0:N],B[0:N],C[0:N*N]) map(tofrom:val)
{
#pragma omp teams distribute parallel for collapse(2) reduction(+ : val)
for (i = 0; i < N; i++) {
for (j = 0; j < N; j++) {
val += C[i * N + j] * A[i] * B[j];
}
}
}
printf("val = %f10.3\n", val);
free(A);
free(B);
free(C);
e.g. by choosing OMP_THREAD_LIMIT = 1024 and OMP_NUM_TEAMS = 120, the LWS and GWS parameters are set to 1024 and 122880, respectively.
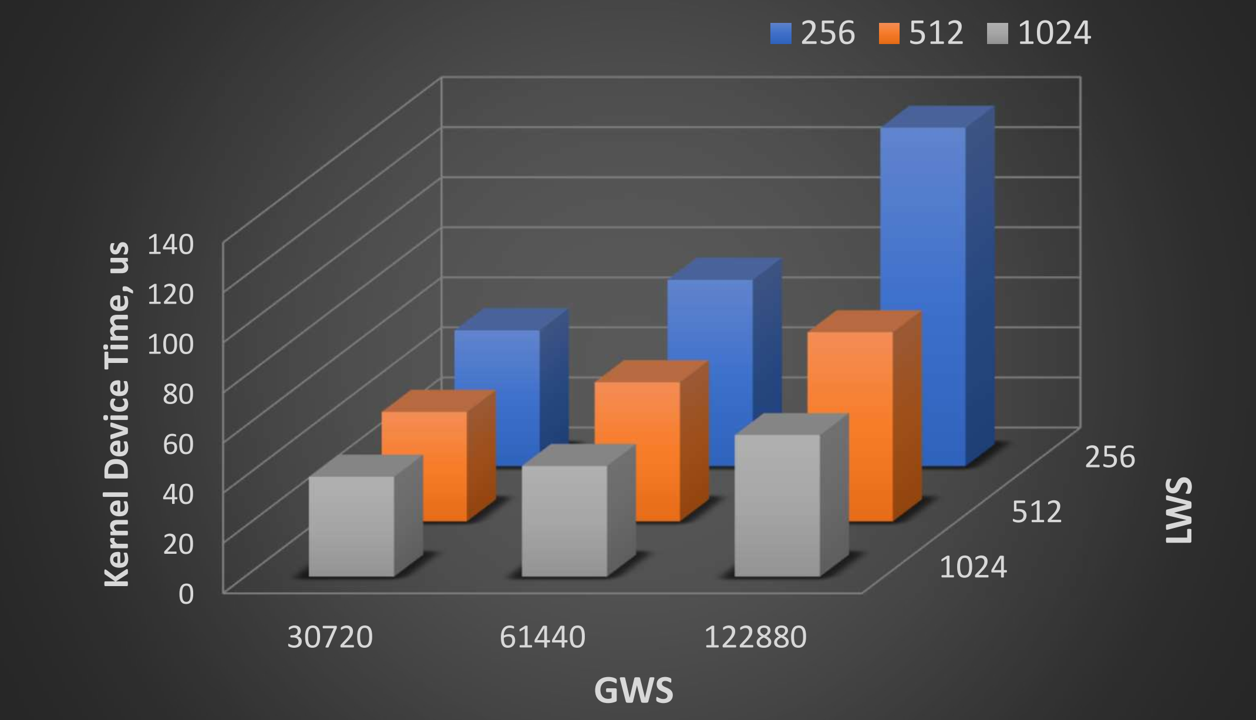
The figure above shows that the best performance for this kernel comes with LWS = 1024 and GWS = 30720 which corresponds to OMP_THREAD_LIMIT = 1024 and OMP_NUM_TEAMS = 30. These environment variables will set the LWS and GWS values to a fixed numbers for all kernels offloaded via OpenMP. However, these environment variables will not affect the LWS and GWS used by highly tuned library kernels like OneMKL.