Visible to Intel only — GUID: GUID-D4D22555-2E82-4E31-939B-B0E751BE2C7D
Execution Model Overview
Thread Mapping and GPU Occupancy
Kernels
Using Libraries for GPU Offload
Host/Device Memory, Buffer and USM
Unified Shared Memory Allocations
Performance Impact of USM and Buffers
Avoiding Moving Data Back and Forth between Host and Device
Optimizing Data Transfers
Avoiding Declaring Buffers in a Loop
Buffer Accessor Modes
Host/Device Coordination
Using Multiple Heterogeneous Devices
Compilation
OpenMP Offloading Tuning Guide
Multi-GPU and Multi-Stack Architecture and Programming
Level Zero
Performance Profiling and Analysis
Configuring GPU Device
Sub-Groups and SIMD Vectorization
Removing Conditional Checks
Registers and Performance
Shared Local Memory
Pointer Aliasing and the Restrict Directive
Synchronization among Threads in a Kernel
Considerations for Selecting Work-Group Size
Prefetch
Reduction
Kernel Launch
Executing Multiple Kernels on the Device at the Same Time
Submitting Kernels to Multiple Queues
Avoiding Redundant Queue Constructions
Programming Intel® XMX Using SYCL Joint Matrix Extension
Doing I/O in the Kernel
Optimizing Explicit SIMD Kernels
Visible to Intel only — GUID: GUID-D4D22555-2E82-4E31-939B-B0E751BE2C7D
Atomic Operations
Atomics allow multiple work-items for any cross work-item communication via memory. SYCL atomics are similar to C++ atomics and make the access to resources protected by atomics guaranteed to be executed as a single unit. The following factors affect the performance and legality of atomic operations
Data types
Local vs global address space
Host, shared and device allocated USM
Data Types in Atomic Operations
The following kernel shows the implementation of a reduction operation in SYCL where every work-item is updating a global accumulator atomically. The input data type of this addition and the vector on which this reduction operation is being applied is an integer. The performance of this kernel is reasonable compared to other techniques used for reduction, such as blocking.
q.submit([&](auto &h) {
sycl::accessor buf_acc(buf, h, sycl::read_only);
sycl::accessor sum_acc(sum_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(data_size, [=](auto index) {
size_t glob_id = index[0];
auto v = sycl::atomic_ref<int, sycl::memory_order::relaxed,
sycl::memory_scope::device,
sycl::access::address_space::global_space>(
sum_acc[0]);
v.fetch_add(buf_acc[glob_id]);
});
});
If the data type of the vector is a float or a double as shown in the kernel below, the performance on certain accelerators is impaired due to lack of hardware support for float or double atomics. The following two kernels demonstrate how the time to execute an atomic add can vary drastically based on whether native atomics are supported.
//
int VectorInt(sycl::queue &q, int iter) {
VectorAllocator<int> alloc;
AlignedVector<int> a(array_size, alloc);
AlignedVector<int> b(array_size, alloc);
InitializeArray<int>(a);
InitializeArray<int>(b);
sycl::range num_items{a.size()};
sycl::buffer a_buf(a);
sycl::buffer b_buf(b);
auto start = std::chrono::steady_clock::now();
for (int i = 0; i < iter; i++) {
q.submit([&](sycl::handler &h) {
// InpuGt accessors
sycl::accessor a_acc(a_buf, h, sycl::read_write);
sycl::accessor b_acc(a_buf, h, sycl::read_only);
h.parallel_for(num_items, [=](auto i) {
auto v = sycl::atomic_ref<int, sycl::memory_order::relaxed,
sycl::memory_scope::device,
sycl::access::address_space::global_space>(
a_acc[0]);
v += b_acc[i];
});
});
}
q.wait();
auto end = std::chrono::steady_clock::now();
std::cout << "Vector int completed on device - took " << (end - start).count()
<< " u-secs\n";
return ((end - start).count());
}
When using atomics, care must be taken to ensure that there is support in the hardware and that they can be executed efficiently. In Gen9 and Intel® Iris® Xe integrated graphics, there is no support for atomics on float or double data types and the performance of VectorDouble will be very poor.
//
int VectorDouble(sycl::queue &q, int iter) {
VectorAllocator<double> alloc;
AlignedVector<double> a(array_size, alloc);
AlignedVector<double> b(array_size, alloc);
InitializeArray<double>(a);
InitializeArray<double>(b);
sycl::range num_items{a.size()};
sycl::buffer a_buf(a);
sycl::buffer b_buf(b);
auto start = std::chrono::steady_clock::now();
for (int i = 0; i < iter; i++) {
q.submit([&](sycl::handler &h) {
// InpuGt accessors
sycl::accessor a_acc(a_buf, h, sycl::read_write);
sycl::accessor b_acc(a_buf, h, sycl::read_only);
h.parallel_for(num_items, [=](auto i) {
auto v = sycl::atomic_ref<double, sycl::memory_order::relaxed,
sycl::memory_scope::device,
sycl::access::address_space::global_space>(
a_acc[0]);
v += b_acc[i];
});
});
}
q.wait();
auto end = std::chrono::steady_clock::now();
std::cout << "Vector Double completed on device - took "
<< (end - start).count() << " u-secs\n";
return ((end - start).count());
}
By analyzing these kernels using VTune Profiler, we can measure the impact of native atomic support. You can see that the VectorInt kernel is much faster than VectorDouble and VectorFloat.
VTune Dynamic Instruction

VTuneTM Profiler dynamic instruction analysis allows us to see the instruction counts vary dramatically when there is no support for native atomics.
Here is the assembly code for our VectorInt kernel.
VTune Atomic Integer
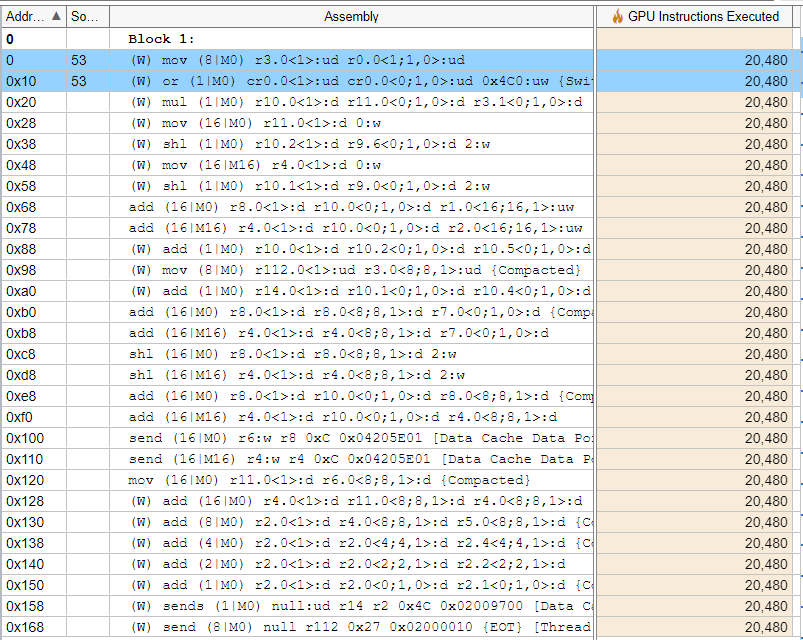
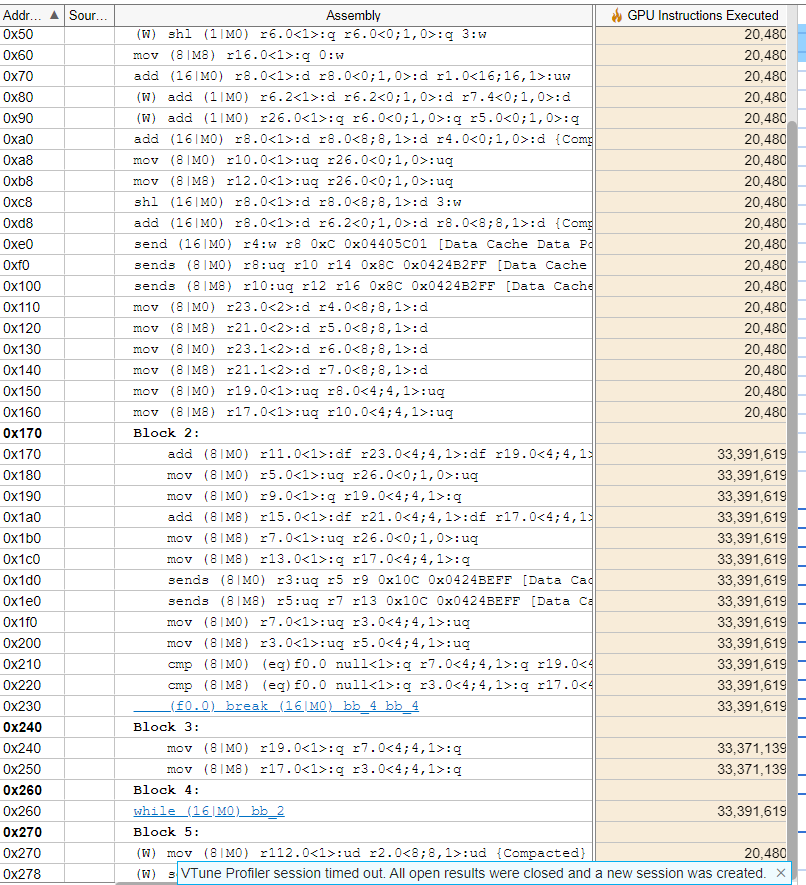
Compared to the assembly code for VectorDouble, there are 33 million more GPU instructions required when we execute our VectorDouble kernel.
VTune Atomic Double
The Intel® Advisor tool has a recommendation pane that provides insights on how to improve the performance of GPU kernels.
Advisor Recommendation Pane
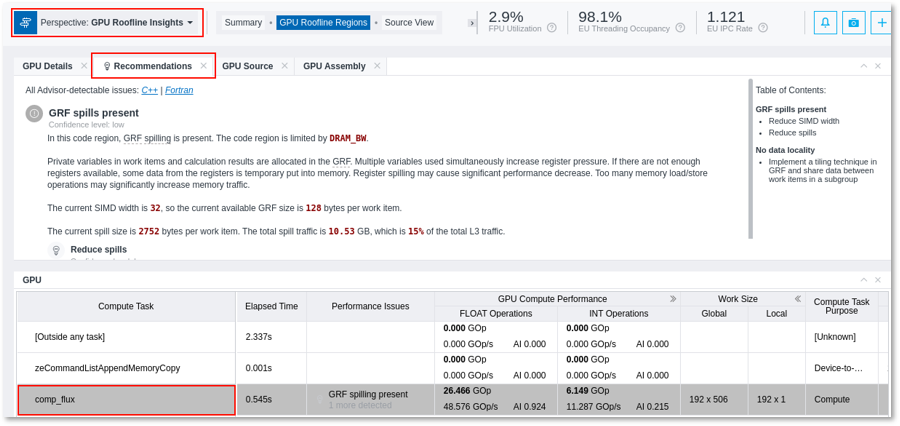
One of the recommendations that Intel® Advisor provides is “Inefficient atomics present”. When atomics are not natively supported in hardware, they are emulated. This can be detected and Intel® Advisor gives advice on possible solutions.
Advisor Inefficient Atomics

Atomic Operations in Global and Local Address Spaces
The standard C++ memory model assumes that applications execute on a single device with a single address space. Neither of these assumptions holds for SYCL applications: different parts of the application execute on different devices (i.e., a host device and one or more accelerator devices); each device has multiple address spaces (i.e., private, local, and global); and the global address space of each device may or may not be disjoint (depending on USM support).
When using atomics in the global address space, again, care must be taken because global updates are much slower than local.
#include <CL/sycl.hpp>
#include <iostream>
int main() {
constexpr int N = 256 * 256;
constexpr int M = 512;
int total = 0;
int *a = static_cast<int *>(malloc(sizeof(int) * N));
for (int i = 0; i < N; i++)
a[i] = 1;
sycl::queue q({sycl::property::queue::enable_profiling()});
sycl::buffer<int> buf(&total, 1);
sycl::buffer<int> bufa(a, N);
auto e = q.submit([&](sycl::handler &h) {
sycl::accessor acc(buf, h);
sycl::accessor acc_a(bufa, h, sycl::read_only);
h.parallel_for(sycl::nd_range<1>(N, M), [=](auto it) {
auto i = it.get_global_id();
sycl::atomic_ref<int, sycl::memory_order_relaxed,
sycl::memory_scope_device,
sycl::access::address_space::global_space>
atomic_op(acc[0]);
atomic_op += acc_a[i];
});
});
sycl::host_accessor h_a(buf);
std::cout << "Reduction Sum : " << h_a[0] << "\n";
std::cout
<< "Kernel Execution Time of Global Atomics Ref: "
<< e.get_profiling_info<sycl::info::event_profiling::command_end>() -
e.get_profiling_info<sycl::info::event_profiling::command_start>()
<< "\n";
return 0;
}
It is possible to refactor your code to use local memory space as the following example demonstrates.
#include <CL/sycl.hpp>
#include <iostream>
int main() {
constexpr int N = 256 * 256;
constexpr int M = 512;
constexpr int NUM_WG = N / M;
int total = 0;
int *a = static_cast<int *>(malloc(sizeof(int) * N));
for (int i = 0; i < N; i++)
a[i] = 1;
sycl::queue q({sycl::property::queue::enable_profiling()});
sycl::buffer<int> global(&total, 1);
sycl::buffer<int> bufa(a, N);
auto e1 = q.submit([&](sycl::handler &h) {
sycl::accessor b(global, h);
sycl::accessor acc_a(bufa, h, sycl::read_only);
auto acc = sycl::local_accessor<int, 1>(NUM_WG, h);
h.parallel_for(sycl::nd_range<1>(N, M), [=](auto it) {
auto i = it.get_global_id(0);
auto group_id = it.get_group(0);
sycl::atomic_ref<int, sycl::memory_order_relaxed,
sycl::memory_scope_device,
sycl::access::address_space::local_space>
atomic_op(acc[group_id]);
sycl::atomic_ref<int, sycl::memory_order_relaxed,
sycl::memory_scope_device,
sycl::access::address_space::global_space>
atomic_op_global(b[0]);
atomic_op += acc_a[i];
it.barrier(sycl::access::fence_space::local_space);
if (it.get_local_id() == 0)
atomic_op_global += acc[group_id];
});
});
sycl::host_accessor h_global(global);
std::cout << "Reduction Sum : " << h_global[0] << "\n";
int total_time =
(e1.get_profiling_info<sycl::info::event_profiling::command_end>() -
e1.get_profiling_info<sycl::info::event_profiling::command_start>());
std::cout << "Kernel Execution Time of Local Atomics : " << total_time
<< "\n";
return 0;
}
Atomic Operations on USM Data
On discrete GPU,
Atomic operations on host allocated USM (sycl::malloc_host) are not supported.
Concurrent accesses from host and device to shared USM location (sycl::malloc_shared) are not supported.
We recommend using device allocated USM (sycl::malloc_device) memory for atomics and device algorithms with atomic operations.
Memory Scope of Atomic Operations
Memory scope of atomic operations allows you to avoid data races.
To learn more about the sycl::memory_scope parameter see the Memory scope section of the SYCL specification.
To learn more about the memory model, see the Memory Model and Atomics chapter of the DPC++ book.