A newer version of this document is available. Customers should click here to go to the newest version.
Visible to Intel only — GUID: GUID-2CA812D0-E1A1-4CA3-A90E-67BECCF811B6
Visible to Intel only — GUID: GUID-2CA812D0-E1A1-4CA3-A90E-67BECCF811B6
Multi-Stack GPU Architecture
Intel® Data Center GPU Max Series use a multi-stack GPU architecture with 1 or 2 stacks.
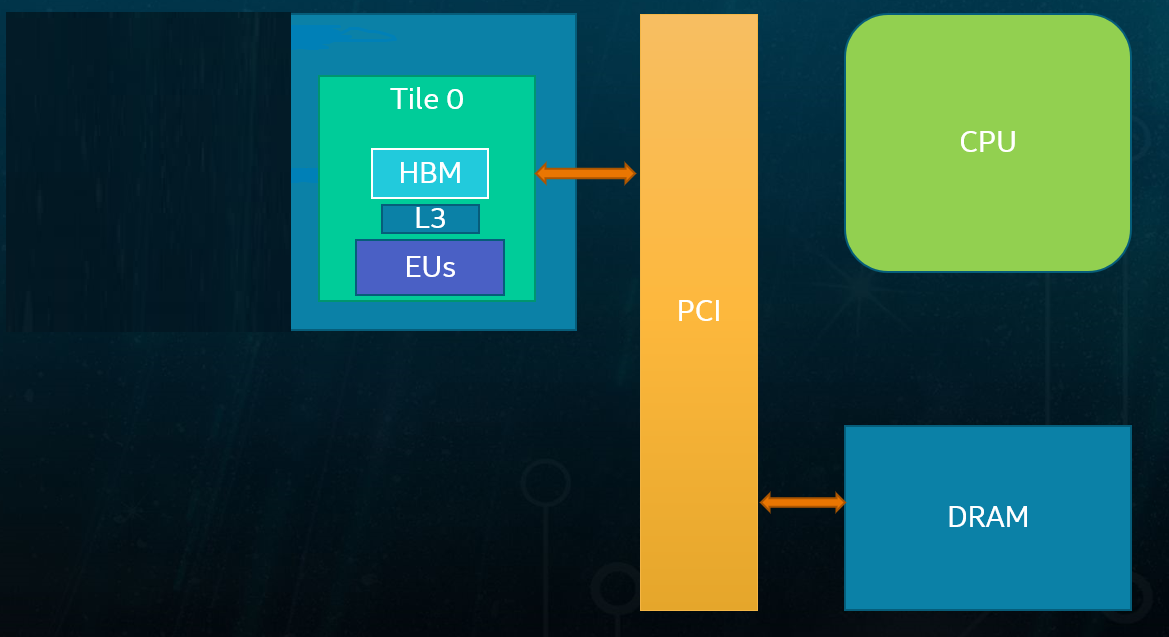
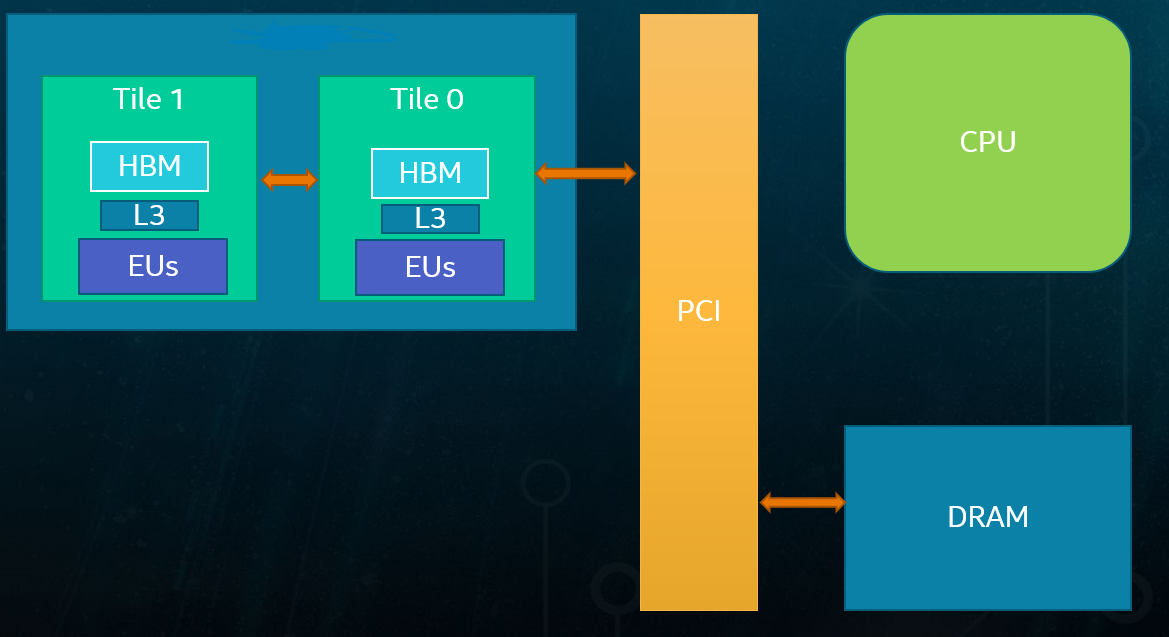
The figure illustrates a 1-stack and 2-stack Intel® Data Center GPU Max Series products, each with its own dedicated resources:
- Vector Engines (VEs)
-
Computation units belong to the stack
- High Bandwidth Memory (HBM)
-
HBM directly connected to the stack
- Level 2 Cache (L2)
-
Level 2 cache belongs to the stack
For general applications, the multi-stack GPU is represented as a single GPU device. Applications do not care that internally the GPU is constructed out of smaller stacks, which simplifies the programming model and allows existing applications to run without any code changes. Intel GPU driver, SYCL and OpenMP parallel language runtimes work together to automatically dispatch the workloads across the stacks.
Stacks are connected with fast interconnect that allows efficient communication between stacks using HBM. The following operations are possible:
- Any stack is capable of reading and writing to any HBM memory
-
For example, stack 0 may read the local HBM memory of stack 1. In this case, the interconnect between stack 0 and stack 1 is used for communication.
- Stack 0 is connected to the PCI, but any stack can read and write system memory
-
The same inter-stack interconnects are used to transfer the data. Hence, stack 0 has the shortest path to system memory among all the stacks.
Reading and writing to system memory do not require CPU involvement, GPU can perform DMA (Direct Memory Access) over PCI to system memory.
- Each stack is an independent entity
-
The stack can execute workloads on its own.
Because access to a stack’s local HBM does not involve inter-stack interconnect, it is more efficient than cross-stack HBM access, with lower latency and lower inter-stack bandwidth consumption. Advanced developers can take advantage of memory locality to achieve higher performance.
To properly utilize multi-stack GPU, we introduced two application programming modes:
- Implicit scaling mode
-
Driver and language runtimes are responsible for work distribution and multi-stack memory placement. Application sees the GPU as one monolithic device and does not care about multi-stack architecture.
- Explicit scaling mode
-
User is responsible for work distribution and multi-stack memory placement. Driver and language runtimes provide tools that expose each stack as a separate subdevice that can be programmed independently of all the others.
Both modes utilize a device to steer the driver execution. There are two types of devices.
- Root Device
-
Represents a multi-stack part, containing subdevices (stacks)
- Subdevice
-
Represents each stack
Driver and language runtimes utilize device abstraction for command dispatching and memory resource allocation. Since both root and subdevices are in fact devices, the same code may be used to target different modes by simply switching what device means in each mode.