Reduction
Reduction is a common operation in parallel programming where an operator is applied to all elements of an array and a single result is produced. The reduction operator is associative and in some cases commutative. Some examples of reductions are summation, maximum, and minimum. A serial summation reduction is shown below:
for (int it = 0; it < iter; it++) {
sum = 0;
for (size_t i = 0; i < data_size; ++i) {
sum += data[i];
}
}
The time complexity of reduction is linear with the number of elements. There are several ways this can be parallelized, and care must be taken to ensure that the amount of communication/synchronization is minimized between different processing elements. A naive way to parallelize this reduction is to use a global variable and let the threads update this variable using an atomic operation:
q.submit([&](auto &h) {
sycl::accessor buf_acc(buf, h, sycl::read_only);
sycl::accessor sum_acc(sum_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(data_size, [=](auto index) {
size_t glob_id = index[0];
auto v = sycl::atomic_ref<int, sycl::memory_order::relaxed,
sycl::memory_scope::device,
sycl::access::address_space::global_space>(
sum_acc[0]);
v.fetch_add(buf_acc[glob_id]);
});
This kernel will perform poorly because the threads are atomically updating a single memory location and getting significant contention. A better approach is to split the array into small chunks, let each thread compute a local sum for each chunk, and then do a sequential/tree reduction of the local sums. The number of chunks will depend on the number of processing elements present in the platform. This can be queried using the get_info<info::device::max_compute_units>() function on the device object:
q.submit([&](auto &h) {
sycl::accessor buf_acc(buf, h, sycl::read_only);
sycl::accessor accum_acc(accum_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(num_processing_elements, [=](auto index) {
size_t glob_id = index[0];
size_t start = glob_id * BATCH;
size_t end = (glob_id + 1) * BATCH;
if (end > N)
end = N;
int sum = 0;
for (size_t i = start; i < end; ++i)
sum += buf_acc[i];
accum_acc[glob_id] = sum;
});
});
This kernel will perform better than the kernel that atomically updates a shared memory location. However, it is still inefficient because the compiler is not able to vectorize the loop. One way to get the compiler to produce vector code is to modify the loop as shown below:
q.submit([&](auto &h) {
sycl::accessor buf_acc(buf, h, sycl::read_only);
sycl::accessor accum_acc(accum_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(num_work_items, [=](auto index) {
size_t glob_id = index[0];
int sum = 0;
for (size_t i = glob_id; i < data_size; i += num_work_items)
sum += buf_acc[i];
accum_acc[glob_id] = sum;
});
});
The compiler can vectorize this code so the performance is better.
In the case of GPUs, a number of thread contexts are available per physical processor, referred to as Vector Engine (VE) or Execution Unit (EU) on the machine. So the above code where the number of threads is equal to the number of VEs does not utilize all the thread contexts. Even in the case of CPUs that have two hyperthreads per core, the code will not use all the thread contexts. In general, it is better to divide the work into enough work-groups to get full occupancy of all thread contexts. This allows the code to better tolerate long latency instructions. The following table shows the number of thread contexts available per processing element in different devices:
VEs |
Threads per VE | Total threads |
|
|---|---|---|
KBL |
24 |
7 | |
TGL |
96 |
7 | |
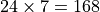
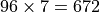
The code below shows a kernel with enough threads to fully utilize available resources. Notice that there is no good way to query the number of available thread contexts from the device. So, depending on the device, you can scale the number of work-items you create for splitting the work among them.
q.submit([&](auto &h) {
sycl::accessor buf_acc(buf, h, sycl::read_only);
sycl::accessor accum_acc(accum_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(num_work_items, [=](auto index) {
size_t glob_id = index[0];
int sum = 0;
for (size_t i = glob_id; i < data_size; i += num_work_items)
sum += buf_acc[i];
accum_acc[glob_id] = sum;
});
});
One popular way of doing a reduction operation on GPUs is to create a number of work-groups and do a tree reduction in each work-group. In the kernel shown below, each work-item in the work-group participates in a reduction network to eventually sum up all the elements in that work-group. All the intermediate results from the work-groups are then summed up by doing a serial reduction (if this intermediate set of results is large enough then we can do few more round(s) of tree reductions). This tree reduction algorithm takes advantage of the very fast synchronization operations among the work-items in a work-group. The performance of this kernel is highly dependent on the efficiency of the kernel launches, because a large number of kernels are launched. Also, the kernel as written below is not very efficient because the number of threads doing actual work reduces exponentially each time through the loop.
q.submit([&](auto &h) {
sycl::accessor buf_acc(buf, h, sycl::read_only);
sycl::accessor accum_acc(accum_buf, h, sycl::write_only, sycl::no_init);
sycl::local_accessor<int, 1> scratch(work_group_size, h);
h.parallel_for(sycl::nd_range<1>(num_work_items, work_group_size),
[=](sycl::nd_item<1> item) {
size_t global_id = item.get_global_id(0);
int local_id = item.get_local_id(0);
int group_id = item.get_group(0);
if (global_id < data_size)
scratch[local_id] = buf_acc[global_id];
else
scratch[local_id] = 0;
// Do a tree reduction on items in work-group
for (int i = work_group_size / 2; i > 0; i >>= 1) {
item.barrier(sycl::access::fence_space::local_space);
if (local_id < i)
scratch[local_id] += scratch[local_id + i];
}
if (local_id == 0)
accum_acc[group_id] = scratch[0];
});
});
The single stage reduction is not very efficient since it will leave a lot work for the host. Adding one more stage will reduce the work on the host and improve performance quite a bit. It can be seen that in the kernel below the intermediate result computed in stage1 is used as input into stage2. This can be generalized to form a multi-stage reduction until the result is small enough so that it can be performed on the host.
q.submit([&](auto &h) {
sycl::accessor buf_acc(buf, h, sycl::read_only);
sycl::accessor accum_acc(accum1_buf, h, sycl::write_only, sycl::no_init);
sycl::local_accessor<int, 1> scratch(work_group_size, h);
h.parallel_for(sycl::nd_range<1>(num_work_items1, work_group_size),
[=](sycl::nd_item<1> item) {
size_t global_id = item.get_global_id(0);
int local_id = item.get_local_id(0);
int group_id = item.get_group(0);
if (global_id < data_size)
scratch[local_id] = buf_acc[global_id];
else
scratch[local_id] = 0;
// Do a tree reduction on items in work-group
for (int i = work_group_size / 2; i > 0; i >>= 1) {
item.barrier(sycl::access::fence_space::local_space);
if (local_id < i)
scratch[local_id] += scratch[local_id + i];
}
if (local_id == 0)
accum_acc[group_id] = scratch[0];
});
});
q.submit([&](auto &h) {
sycl::accessor buf_acc(accum1_buf, h, sycl::read_only);
sycl::accessor accum_acc(accum2_buf, h, sycl::write_only, sycl::no_init);
sycl::local_accessor<int, 1> scratch(work_group_size, h);
h.parallel_for(sycl::nd_range<1>(num_work_items2, work_group_size),
[=](sycl::nd_item<1> item) {
size_t global_id = item.get_global_id(0);
int local_id = item.get_local_id(0);
int group_id = item.get_group(0);
if (global_id < static_cast<size_t>(num_work_items2))
scratch[local_id] = buf_acc[global_id];
else
scratch[local_id] = 0;
// Do a tree reduction on items in work-group
for (int i = work_group_size / 2; i > 0; i >>= 1) {
item.barrier(sycl::access::fence_space::local_space);
if (local_id < i)
scratch[local_id] += scratch[local_id + i];
}
if (local_id == 0)
accum_acc[group_id] = scratch[0];
});
});
SYCL also supports built-in reduction operations, and you should use it where it is suitable because its implementation is fine tuned to the underlying architecture. The following kernel shows how to use the built-in reduction operator in the compiler.
q.submit([&](auto &h) {
sycl::accessor buf_acc(buf, h, sycl::read_only);
auto sumr = sycl::reduction(sum_buf, h, sycl::plus<>());
h.parallel_for(sycl::nd_range<1>{data_size, 256}, sumr,
[=](sycl::nd_item<1> item, auto &sumr_arg) {
int glob_id = item.get_global_id(0);
sumr_arg += buf_acc[glob_id];
});
});
A further optimization is to block the accesses to the input vector and use the shared local memory to store the intermediate results. This kernel is shown below. In this kernel every work-item operates on a certain number of vector elements, and then one thread in the work-group reduces all these elements to one result by linearly going through the shared memory containing the intermediate results.
q.submit([&](auto &h) {
sycl::accessor buf_acc(buf, h, sycl::read_only);
sycl::accessor accum_acc(accum_buf, h, sycl::write_only, sycl::no_init);
sycl::local_accessor<int, 1> scratch(work_group_size, h);
h.parallel_for(sycl::nd_range<1>{num_work_items, work_group_size},
[=](sycl::nd_item<1> item) {
size_t glob_id = item.get_global_id(0);
size_t group_id = item.get_group(0);
size_t loc_id = item.get_local_id(0);
int offset = ((glob_id >> log2workitems_per_block)
<< log2elements_per_block) +
(glob_id & mask);
int sum = 0;
for (int i = 0; i < elements_per_work_item; ++i)
sum +=
buf_acc[(i << log2workitems_per_block) + offset];
scratch[loc_id] = sum;
// Serial Reduction
item.barrier(sycl::access::fence_space::local_space);
if (loc_id == 0) {
int sum = 0;
for (int i = 0; i < work_group_size; ++i)
sum += scratch[i];
accum_acc[group_id] = sum;
}
});
});
The kernel below is similar to the one above except that tree reduction is used to reduce the intermediate results from all the work-items in a work-group. In most cases this does not seem to make a big difference in performance.
q.submit([&](auto &h) {
sycl::accessor buf_acc(buf, h, sycl::read_only);
sycl::accessor accum_acc(accum_buf, h, sycl::write_only, sycl::no_init);
sycl::local_accessor<int, 1> scratch(work_group_size, h);
h.parallel_for(sycl::nd_range<1>{num_work_items, work_group_size},
[=](sycl::nd_item<1> item) {
size_t glob_id = item.get_global_id(0);
size_t group_id = item.get_group(0);
size_t loc_id = item.get_local_id(0);
int offset = ((glob_id >> log2workitems_per_block)
<< log2elements_per_block) +
(glob_id & mask);
int sum = 0;
for (int i = 0; i < elements_per_work_item; ++i)
sum +=
buf_acc[(i << log2workitems_per_block) + offset];
scratch[loc_id] = sum;
// tree reduction
item.barrier(sycl::access::fence_space::local_space);
for (int i = work_group_size / 2; i > 0; i >>= 1) {
item.barrier(sycl::access::fence_space::local_space);
if (loc_id < static_cast<size_t>(i))
scratch[loc_id] += scratch[loc_id + i];
}
if (loc_id == 0)
accum_acc[group_id] = scratch[0];
});
});
The kernel below uses the blocking technique and then the compiler reduction operator to do final reduction. This gives good performance on most of the platforms on which it was tested.
q.submit([&](auto &h) {
sycl::accessor buf_acc(buf, h, sycl::read_only);
auto sumr = sycl::reduction(sum_buf, h, sycl::plus<>());
h.parallel_for(sycl::nd_range<1>{num_work_items, work_group_size}, sumr,
[=](sycl::nd_item<1> item, auto &sumr_arg) {
size_t glob_id = item.get_global_id(0);
int offset = ((glob_id >> log2workitems_per_block)
<< log2elements_per_block) +
(glob_id & mask);
int sum = 0;
for (int i = 0; i < elements_per_work_item; ++i)
sum +=
buf_acc[(i << log2workitems_per_block) + offset];
sumr_arg += sum;
});
});
This next kernel uses a completely different technique for accessing the memory. It uses sub-group loads to generate the intermediate result in a vector form. This intermediate result is then brought back to the host and the final reduction is performed there. In some cases it may be better to create another kernel to reduce this result in a single work-group, which lets you perform tree reduction through efficient barriers.
q.submit([&](auto &h) {
const sycl::accessor buf_acc(buf, h);
sycl::accessor accum_acc(accum_buf, h, sycl::write_only, sycl::no_init);
sycl::local_accessor<sycl::vec<int, 8>, 1l> scratch(work_group_size, h);
h.parallel_for(
sycl::nd_range<1>{num_work_items, work_group_size},
[=](sycl::nd_item<1> item) [[intel::reqd_sub_group_size(16)]] {
size_t group_id = item.get_group(0);
size_t loc_id = item.get_local_id(0);
sycl::sub_group sg = item.get_sub_group();
sycl::vec<int, 8> sum{0, 0, 0, 0, 0, 0, 0, 0};
using global_ptr =
sycl::multi_ptr<int, sycl::access::address_space::global_space>;
int base = (group_id * work_group_size +
sg.get_group_id()[0] * sg.get_local_range()[0]) *
elements_per_work_item;
for (int i = 0; i < elements_per_work_item / 8; ++i)
sum += sg.load<8>(global_ptr(&buf_acc[base + i * 128]));
scratch[loc_id] = sum;
for (int i = work_group_size / 2; i > 0; i >>= 1) {
item.barrier(sycl::access::fence_space::local_space);
if (loc_id < static_cast<size_t>(i))
scratch[loc_id] += scratch[loc_id + i];
}
if (loc_id == 0)
accum_acc[group_id] = scratch[0];
});
});
Different implementations of reduction operation are provided and discussed here, which may have different performance characteristics depending on the architecture of the accelerator. Another important thing to note is that the time it takes to bring the result of reduction to the host over the PCIe interface (for a discrete GPU) is almost same as actually doing the entire reduction on the device. This shows that one should avoid data transfers between host and device as much as possible or overlap the kernel execution with data transfers.