Visible to Intel only — GUID: GUID-8FAC8E44-EFD8-4A49-95E5-D051DA1C3A05
Create a New Project
Use the Intel® oneAPI DPC++/C++ Compiler
Select the Compiler Version
Specify a Base Platform Toolset
Use Property Pages
Use Intel® Libraries with Microsoft Visual Studio*
Include MPI Support
Use Code Coverage in Microsoft Visual Studio*
Use Profile Guided Optimization in Microsoft Visual Studio*
Optimization Reports
Dialog Box Help
Use Intel® oneAPI DPC++/C++ Compiler dialog box
Hardware Profile-Guided Optimization dialog box
Options: Compilers dialog box
Options: Intel Libraries for oneAPI dialog box
Options: Converter dialog box
Options: Optimization Reports dialog box
Options: Profile Guided Optimization dialog box
Profile Guided Optimization dialog box
Options: Code Coverage dialog box
Code Coverage dialog box
Code Coverage Settings dialog box
Alphabetical Option List
General Rules for Compiler Options
What Appears in the Compiler Option Descriptions
Optimization Options
Advanced Optimization Options
Code Generation Options
Offload Compilation, OpenMP*, and Parallel Processing Options
Interprocedural Optimization Options
Profile Guided Optimization Options
Optimization Report Options
Floating-Point Options
Inlining Options
Output, Debug, and Precompiled Header Options
Preprocessor Options
Component Control Options
Language Options
Data Options
Compiler Diagnostic Options
Compatibility Options
Linking or Linker Options
Miscellaneous Options
Deprecated and Removed Compiler Options
Display Option Information
Alternate Compiler Options
Portability and GCC-Compatible Warning Options
ffreestanding, Qfreestanding
fjump-tables
fvec-peel-loops, Qvec-peel-loops
fvec-remainder-loops, Qvec-remainder-loops
fvec-with-mask, Qvec-with-mask
ipp-link, Qipp-link
mno-gather, Qgather-
mno-scatter, Qscatter-
qactypes, Qactypes
qdaal, Qdaal
qipp, Qipp
qmkl, Qmkl
qmkl-ilp64, Qmkl-ilp64
qmkl-sycl-impl, Qmkl-sycl-impl
qopt-assume-no-loop-carried-dep, Qopt-assume-no-loop-carried-dep
qopt-dynamic-align, Qopt-dynamic-align
qopt-for-throughput, Qopt-for-throughput
qopt-mem-layout-trans, Qopt-mem-layout-trans
qopt-multiple-gather-scatter-by-shuffles, Qopt-multiple-gather-scatter-by-shuffles
qopt-prefetch, Qopt-prefetch
qopt-prefetch-distance, Qopt-prefetch-distance
qopt-prefetch-loads-only, Qopt-prefetch-loads-only
qopt-streaming-stores, Qopt-streaming-stores
qopt-zmm-usage, Qopt-zmm-usage
qtbb, Qtbb
unroll, Qunroll
vec, Qvec
vec-threshold, Qvec-threshold
vecabi, Qvecabi
arch
ax, Qax
EH
fasynchronous-unwind-tables
fcf-protection, Qcf-protection
fdata-sections, Gw
fexceptions
ffunction-sections, Gy
fomit-frame-pointer
Gd
GR
guard
Gv
m, Qm
m64, Qm64
m80387
march
masm
mauto-arch, Qauto-arch
mbranches-within-32B-boundaries, Qbranches-within-32B-boundaries
mintrinsic-promote, Qintrinsic-promote
momit-leaf-frame-pointer
mtune, tune
regcall, Qregcall
x, Qx
xHost, QxHost
device-math-lib
fintelfpga
fiopenmp, Qiopenmp
flink-huge-device-code
fno-sycl-libspirv
foffload-static-lib
fopenmp
fopenmp-concurrent-host-device-compile, Qopenmp-concurrent-host-device-compile
fopenmp-declare-target-scalar-defaultmap, Qopenmp-declare-target-scalar-defaultmap
fopenmp-device-code-split, Qopenmp-device-code-split
fopenmp-device-lib
fopenmp-max-parallel-link-jobs, Qopenmp-max-parallel-link-jobs
fopenmp-target-buffers, Qopenmp-target-buffers
fopenmp-target-default-sub-group-size, Qopenmp-target-default-sub-group-size
fopenmp-target-loopopt, Qopenmp-target-loopopt
fopenmp-target-simd, Qopenmp-target-simd
fopenmp-targets, Qopenmp-targets
fsycl
fsycl-add-default-spec-consts-image
fsycl-add-targets
fsycl-dead-args-optimization
fsycl-device-code-split
fsycl-device-lib
fsycl-device-obj
fsycl-device-only
fsycl-early-optimizations
fsycl-enable-function-pointers
fsycl-esimd-force-stateless-mem
fsycl-explicit-simd
fsycl-force-target
fsycl-help
fsycl-host-compiler
fsycl-host-compiler-options
fsycl-id-queries-fit-in-int
fsycl-instrument-device-code
fsycl-link
fsycl-link-huge-device-code
fsycl-link-targets
fsycl-max-parallel-link-jobs
fsycl-optimize-non-user-code
fsycl-pstl-offload
fsycl-rdc
fsycl-remove-unused-external-funcs
fsycl-targets
fsycl-unnamed-lambda
fsycl-use-bitcode
ftarget-compile-fast
ftarget-export-symbols
ftarget-register-alloc-mode, Qtarget-register-alloc-mode
nolibsycl
qopenmp, Qopenmp
qopenmp-link
qopenmp-simd, Qopenmp-simd
qopenmp-stubs, Qopenmp-stubs
reuse-exe
Wno-sycl-strict
Xopenmp-target
Xs
Xsycl-target
ffp-accuracy, Qfp-accuracy
ffp-contract
fimf-absolute-error, Qimf-absolute-error
fimf-accuracy-bits, Qimf-accuracy-bits
fimf-arch-consistency, Qimf-arch-consistency
fimf-domain-exclusion, Qimf-domain-exclusion
fimf-max-error, Qimf-max-error
fimf-precision, Qimf-precision
fimf-use-svml, Qimf-use-svml
fma, Qfma
fp-model, fp
fp-speculation, Qfp-speculation
ftz, Qftz
pc, Qpc
w
W
Wabi
Wall
Wcheck-unicode-security
Wcomment
Wdeprecated
Werror, WX
Werror-all
Wextra-tokens
Wformat
Wformat-security
Wmain
Wmissing-declarations
Wmissing-prototypes
Wpointer-arith
Wreorder
Wreturn-type
Wshadow
Wsign-compare
Wstrict-aliasing
Wstrict-prototypes
Wtrigraphs
Wuninitialized
Wunknown-pragmas
Wunused-function
Wunused-variable
Wwrite-strings
Create Libraries
Use Intel Shared Libraries
Manage Libraries
Redistribute Libraries When Deploying Applications
Resolve References to Shared Libraries
Redistributable Library Considerations
Intel's Memory Allocator Library
SIMD Data Layout Templates
Intel® C++ Class Libraries
Hardware and Software Requirements
Details About the Libraries
SIMD Data Flow
Comparison Between Inlining, Intrinsics, and Class Libraries
Intel's C++ Asynchronous I/O Extensions for Windows
IEEE 754-2008 Binary Floating-Point Conformance Library
Intel's Numeric String Conversion Library
Hardware and Software Requirements
Details About the Libraries
SIMD Data Flow
Comparison Between Inlining, Intrinsics, and Class Libraries
C++ Classes and SIMD Operations
Capabilities of C++ SIMD Classes
Integer Vector Classes
Floating-Point Vector Classes
Classes Quick Reference
Programming Example
Intel's valarray Implementation
Terms and Syntax
Rules for Operators
Assignment Operator
Logical Operators
Addition and Subtraction Operators
Multiplication Operators
Shift Operators
Comparison Operators
Conditional Select Operators
Debug Operations
Unpack Operators
Pack Operators
Clear MMX™ State Operator
Integer Functions for Intel® Streaming SIMD Extensions
Conversions between Fvec and Ivec
Fvec Syntax and Notation
Data Alignment
Conversions
Constructors and Initialization
Arithmetic Operators
Minimum and Maximum Operators
Logical Operators
Compare Operators
Conditional Select Operators for Fvec Classes
Cacheability Support Operators
Debug Operations
Load and Store Operators
Unpack Operators
Move Mask Operators
aio_read
aio_write
Example for aio_read and aio_write Functions
aio_suspend
Example for aio_suspend Function
aio_error
aio_return
Example for aio_error and aio_return Functions
aio_fsync
aio_cancel
Example for aio_cancel Function
lio_listio
Example for lio_listio Function
Asynchronous I/O Function Errors
Intel® IEEE 754-2008 Binary Floating-Point Conformance Library and Usage
Function List
Homogeneous General-Computational Operations Functions
General-Computational Operation Functions
Quiet-Computational Operations Functions
Signaling-Computational Operations Functions
Non-Computational Operations Functions
Compilation Overview
Supported Environment Variables
Pass Options to the Linker
Specify Alternate Tools
Use Configuration Files
Use Response Files
Global Symbols and Visibility Attributes for Linux*
Save Compiler Information in Your Executable
Link Debug Information
Ahead of Time Compilation
Device Offload Compilation Considerations
Use a Third-Party Compiler as a Host Compiler for SYCL Code
Extensions
OpenMP* Support
Intel® oneAPI Level Zero
Vectorization
Instrumented Profile-Guided Optimization
Hardware Profile-Guided Optimization
High-Level Optimization
Interprocedural Optimization
Methods to Optimize Code Size
Compiler Math Library
IMF Device Library
Basic Arithmetic Operations and Simple Math Functions
IMF Device Library Usage Example
IMF Device Library Function List
IMF Device Library Trigonometric Functions
IMF Device Library Hyperbolic Functions
IMF Device Library Exponential Functions
IMF Device Library Logarithmic Functions
IMF Device Library Power Functions
IMF Device Library Special Functions
IMF Device Library Rounding Functions
IMF Device Library Miscellaneous Functions
Visible to Intel only — GUID: GUID-8FAC8E44-EFD8-4A49-95E5-D051DA1C3A05
Intel® C++ Class Libraries
The Intel® C++ Class Libraries enable Single-Instruction, Multiple-Data (SIMD) operations. The principle of SIMD operations is to exploit microprocessor architecture through parallel processing. The effect of parallel processing is increased data throughput using fewer clock cycles. The objective is to improve application performance of complex and computation-intensive audio, video, and graphical data bit streams.
Hardware and Software Requirements
The Intel® C++ Class Libraries are functions abstracted from the instruction extensions available on Intel® processors.
Details About the Libraries
The Intel® C++ Class Libraries for SIMD Operations provide a convenient interface to access the underlying instructions for processors as specified above. These processor-instruction extensions enable parallel processing using the single instruction-multiple data (SIMD) technique as illustrated in the following figure.
SIMD Data Flow
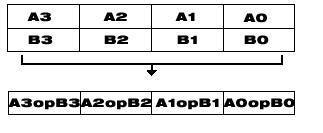
Performing four operations with a single instruction improves efficiency by a factor of four for that particular instruction.
These new processor instructions can be implemented using assembly inlining, intrinsics, or the C++ SIMD classes. Compare the coding required to add four 32-bit floating-point values, using each of the available interfaces:
Comparison Between Inlining, Intrinsics, and Class Libraries
The table below shows an addition of four single-precision floating-point values using assembly inlining, intrinsics, and the libraries. You can see how much easier it is to code with the Intel C++ SIMD Class Libraries. Besides using fewer keystrokes and fewer lines of code, the notation is like the standard notation in C++, making it much easier to implement over other methods.
Assembly Inlining |
Intrinsics |
SIMD Class Libraries |
|---|---|---|
... __m128 a,b,c; __asm{ movaps xmm0,b movaps xmm1,c addps xmm0,xmm1 movaps a, xmm0 } ... |
#include <xmmintrin.h> ... __m128 a,b,c; a = _mm_add_ps(b,c); ... |
#include <fvec.h> ... F32vec4 a,b,c; a = b +c; ... |
Parent topic: Libraries