This article was also published on Numenta.
Problem Statement
Businesses across industries have witnessed the transformative potential of large language models (LLM). Despite the growing potential of LLMs, businesses still struggle to integrate LLMs into operations, mainly due to their cost, complexity, high power consumption, and concerns over data protection. GPUs have traditionally been the go-to hardware for LLMs, but they incur significant IT complications and escalating expenses that cannot sustain growing operations. Furthermore, due to worldwide demand and shortages, businesses now must wait over a year to secure GPUs for their AI projects.
A New Approach
Numenta and Intel are setting a new precedent for LLM deployment, freeing businesses from their dependency on GPUs. The Numenta Platform for Intelligent Computing (NuPIC*) maps neuroscience-based concepts to the Intel® Advanced Matrix Extensions (Intel® AMX) instruction set. With NuPIC, it is finally possible to deploy LLMs at scale on Intel® CPUs and deliver dramatic price/performance improvements. For examples, see benchmarks P6 and P11 in the Performance Index for 4th Generation Intel® Xeon® Scalable Processors.
Technologies
Intel® AMX
Intel AMX accelerates matrix operations by providing dedicated hardware support (figure 1). It is particularly beneficial for applications that rely heavily on matrix computations, such as deep learning inference. Intel AMX was first introduced in 4th generation Intel® Xeon® processors and is now even better on the new 5th generation Intel Xeon processors.

Figure 1. The Intel AMX instruction set includes two key components: tiles and TMUL. Tiles are 2D units that allow parallel processing of large matrices. TMUL can perform 16 x 16 x 32 matrix multiplications in only 16 clock cycles.
NuPIC*
Built on a foundation of decades of neuroscience research, NuPIC allows you to build powerful language-based applications quickly and easily (figure 2). At the heart of NuPIC is a highly optimized inference server that takes advantage of Intel AMX to enable you to run LLMs efficiently on Intel CPUs. With a library of production-ready pretrained models that can be customized to a variety of natural language processing use cases, you can directly run the models in the NuPIC Inference Server. You can also fine-tune the models on your data with the NuPIC Training Module, and then deploy your custom fine-tuned model to the NuPIC Model Library and run it in the inference server.
Built on standard inference protocols, NuPIC can be seamlessly integrated into any standard MLOps pipeline. Deployed as Docker* containers, the solution stays within your infrastructure in a scalable, secure, highly available, high-performance environment. You retain full control of your custom models. Your data remains fully private and never needs to leave your system.
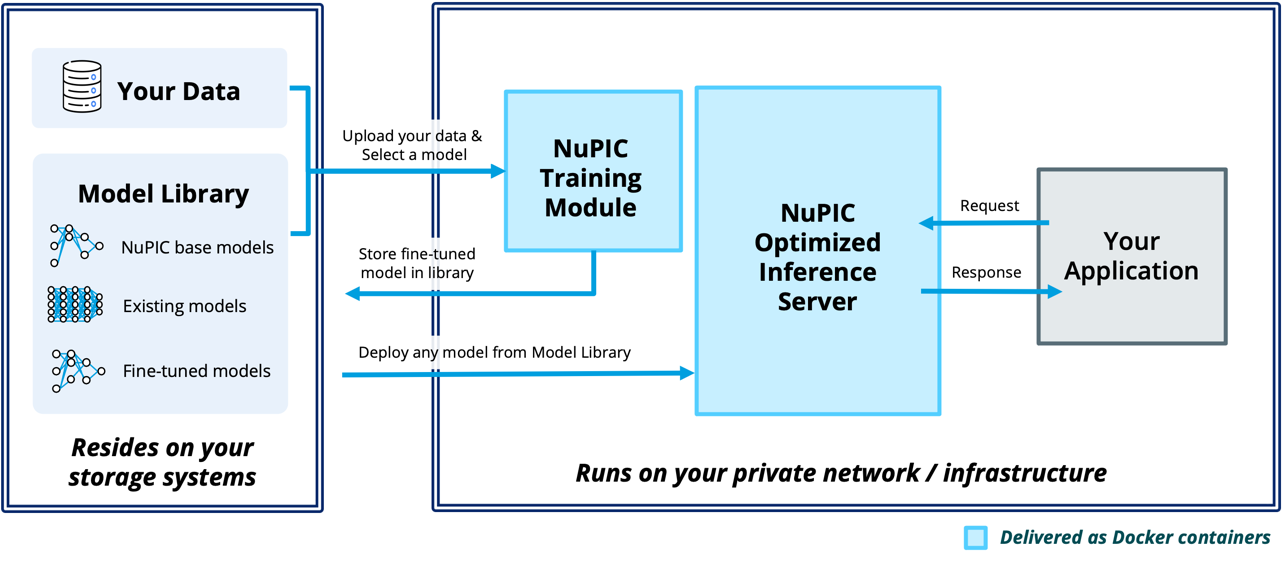
Figure 2. NuPIC architecture
Why NuPIC on Intel® Xeon® Processors Makes CPUs Ideal for AI Inference
Numenta and Intel are opening a new chapter in this narrative, making it possible to deploy LLMs at scale on CPUs in a cost-effective manner. Here are a few reasons why.
Performance: 17x Faster Than NVIDIA* A100 Tensor Core GPUs
With minimal changes to the Transformers structure, NuPIC achieves over two orders of magnitude improvement in inference throughput on CPUs enabled for Intel AMX compared to previous-generation CPUs and significant speedups compared to GPUs (table 1). For BERT-Large, our platform on a 5th gen Intel Xeon processor outperformed the NVIDIA A100 GPU by up to 17x. GPUs require higher batch sizes for best parallel performance. However, batching leads to a more complex inference implementation and introduces undesirable latency in real-time applications. In contrast, NuPIC does not require batching for high performance, making applications flexible, scalable, and simple to manage. Despite the disadvantages of batching, we list the performance of the NVIDIA A100 at a batch size of 8. NuPIC at a batch size of 1 still outperforms the batched NVIDIA GPU implementation by more than 2x.
Table 1. Inference Results for NuPIC on 5th Generation Intel Xeon Processors versus an NVIDIA A100 Processor1
1
|
Sequence Length |
Batch Size |
Inferences Per Second on BERT-Large |
Speedup |
|
|---|---|---|---|---|
|
NuPIC on 5th Gen Intel Xeon Processor |
NVIDIA A100 Processor |
|||
|
64 |
1 |
2891 |
1661 |
17.4x |
|
128 |
1 |
901 |
128 |
7.0x |
|
128 |
8 | - |
495 |
2.2x |
Scalability: Managing Multiple Clients
Most LLM applications need to support many clients, and each requires inference results. NuPIC on a single server with a 5th gen Intel Xeon processor enables applications to handle a large number of client requests while maintaining high throughput (figure 3). None of the clients need to batch their inputs, and each client can be completely asynchronous.
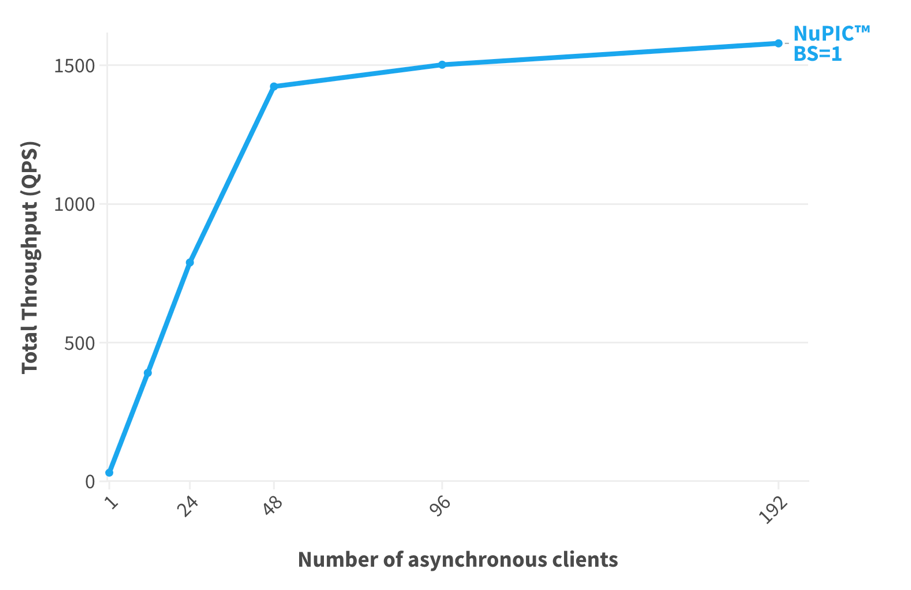
Figure 3. Total throughput on 128 independent NuPIC-optimized BERT-Large models with an increasing number of asynchronous clients.2
2
Flexibility: Running Multiple Models on the Same Server
Many business applications are powered by multiple LLMs that each solve a different task. In addition to managing asynchronous clients, NuPIC enables you to run separate models concurrently and asynchronously on the same server, something that is hard to manage efficiently on GPUs. As shown in figure 3, we ran 128 independent models on a single server. Different models can have different sets of weights and can vary in their computation requirements, but this is all handled by NuPIC on Intel CPUs. Moreover, as your data and computational needs grow, it is much simpler and less restrictive to add CPUs to your system than to try to integrate additional GPUs. This is especially true in cloud-based environments, where adding more computational power is often just a click away. From an IT standpoint, CPUs are easier to deploy and manage than GPUs.
Cost and Energy Efficient
CPUs are also generally more affordable and accessible than GPUs, making them the preferred choice for many businesses. However, their effectiveness in running AI inference has traditionally been limited by slower processing speeds. NuPIC accelerates AI inference on Intel CPUs, leading to advantages in inferences per dollar and inferences per watt. Overall, with NuPIC and Intel AMX, AI applications are substantially lower in cost, consume significantly less energy, and are more sustainable and scalable.
Implementation Example
To show how you can take advantage of NuPIC’s capabilities and features, example code is provided for different use cases, ranging from those ready for immediate deployment to those that need fine-tuning. This example shows how you can use NuPIC to perform sentiment analysis in a financial context, where the NuPIC-optimized BERT model processes text data like news articles and market reports and categorizes them into different sentiments (positive, negative, and neutral). This can help financial analysts quickly understand the overall market sentiment, allowing them to make informed decisions about investment strategies or forecasting market movements.
Install and Launch NuPIC
Numenta provides a download script, which includes example code and all the necessary components for fine-tuning and deployment. After you install NuPIC, run the following commands to start the training module and inference server:
./nupic_training.sh --start
./nupic_inference.sh —start
This downloads the Docker images and starts the Docker containers. By default, the Docker container for the training module and inference server runs on the API server on ports 8321 and 8000, respectively. You can stop the server and Docker container at any time with the --stop command.
Prepare Your Dataset
In this example, use the financial sentiment dataset for fine-tuning. First, split the data into train and test sets:
dataset_file = f"{script_dir}/../../datasets/financial_sentiment.csv"
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, stratify=y, random_state=42
)
train = pd.concat([y_train, X_train], axis=1)
test = pd.concat([y_test, X_test], axis=1)
train.to_csv("financial_sentiment_train_dataset.csv", index=False)
test.to_csv("financial_sentiment_test_dataset.csv", index=False)
Fine-Tune Your Data with the NuPIC Training Module
After splitting the dataset, you can now fine-tune the model via NuPIC’s training module. This process involves adjusting parameters like learning rate and batch size to optimize performance. In this case, fine-tune a NuPIC-optimized BERT model with the financial sentiment dataset:
python -m nupic.client.nupic_train --train_path ../../datasets/financial_sentiment_train_dataset.csv
--test_path ../../datasets/financial_sentiment_test_dataset.csv --url http\://localhost:8321
NuPIC's training module then uses the test portion of the financial sentiment dataset and prints an accuracy score. You can adjust hyperparameters if necessary and retrain until you're happy with the results. Once fine-tuning is complete, a new model is generated. The previous script retrieves the model from the training module and stores it in your local directory as a .tar.gz file, where you can then deploy it to NuPIC's inference server.
Import Your Fine-Tuned Model into the NuPIC Inference Server
To deploy your fine-tuned model, first make it available on the inference server. This means that the output from the last phase (model_xxx.tar.gz) should be uncompressed and moved to the models directory, which is mapped into the inference server container. Use the following commands, replacing xxx with the details of your fine-tuned model:
cp model_xxx.tar.gz../nupic/inference/models
cd ../../nupic/inference/models
tar -xzvf model_xxx.tar.gz
Deployment: Real-Time Inference on Intel Xeon CPUs
Now it's time to deploy your model. The Python* client for NuPIC simplifies deployment. The client manages communication between your end-user application and model. A simple API enables you to generate embeddings automatically and make requests to the inference server in real time. Set up the NuPIC client and perform inference as follows:
# Model name, you can use a model from NuPIC model libary, or your fine-tuned model MODEL = "numenta-sbert-2-v1-wtokenizer"
# The URL to your inference server instance
URL = "localhost:8000"
# The supported protocol includes http and grpc
PROTOCOL = "http"
# Optional connection configuration, such as SSL protocol certificates.
CONNECTION_CONFIG = {}
#Connect to NuPIC client
numenta_client = ClientFactory.get_client(MODEL, URL, PROTOCOL, CONNECTION_CONFIG)
#Run inference
result = numenta_client.infer(["Semiconductor industry is doing great!"])
You can send a request with text data to your API endpoint and retrieve the resulting sentiment predictions. For real-time analysis, you can continuously feed market reports and news articles to your API and receive sentiment predictions in return.
Conclusion
With NuPIC and Intel AMX, you get the versatility and security required by enterprise IT, combined with unparalleled scaling of LLMs on Intel CPUs. With this synergistic combination of software and hardware technologies, running LLMs on CPUs becomes more than a possibility—it becomes a strategic advantage. To see how your organization can benefit from NuPIC, request a demo from Numenta.