
Manual anomaly detection is time- and labor-intensive, which limits its applicability to the large data volumes of typical industrial settings. Artificial intelligence (AI) is transforming Industrial Internet of Things (IIoT) by enabling higher productivity, better insights, less downtime, and superior product quality. The goal of this anomaly detection reference kit is to provide AI-powered visual quality inspection of high-resolution images to identify rare, abnormal events, like defective parts coming off a production line. Conceptually, it finds outliers that are statistically different from the regular data points, so it can be applied to similar use-cases like fraud detection in financial transactions, quality monitoring in manufacturing, filtering spam emails, intrusion detection in a network, etc. You can use this reference kit “as is” or modify it to fit your application requirements.
Anomaly detection has several challenges. Feature engineering is required to extract representations from the raw data. Traditional machine learning techniques rely on manual feature engineering that may not always generalize to other settings. They also require labeled training data, which increases data collection and annotation overhead. Balanced training data isn’t possible because anomalies are typically rare occurrences. This makes standard classification techniques inappropriate. Finally, the nature of anomalies can be arbitrary, and defects can occur for a variety of unpredictable reasons, so it may be impossible to predict the type of anomaly.
To overcome these challenges while still achieving good performance, we present an unsupervised, mixed-method end-to-end fine-tuning and inference reference kit for anomaly detection where a model of normality is learned from defect-free data in an unsupervised manner, and deviations from the models are flagged as anomalies. This reference kit is accelerated by Intel-optimized software and is built on easy-to-use Intel® Transfer Learning Tool APIs.
MVTec AD – A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection
MVTec AD is a widely used benchmarking dataset for anomaly detection in industrial inspection applications. It consists of more than 5,000 high-resolution color images of 15 distinct object categories, including bottles, tiles, and woods, with a total of 60 anomaly types across all categories (Table 1). In each category, the dataset provides a training set of normal images and a test set of images with six different types of anomalies. The anomalies are manually introduced by applying various alterations (e.g., cuts, scratches, and contaminations) to the objects. The dataset is particularly useful for evaluating the performance of anomaly detection methods because it provides a challenging and realistic set of images that mimic real-world anomalies.

Table 1. Overview of the MVTec AD dataset. For each category, the number of training and test images is given plus information about the defects present in the test images (taken from source).
Visual Quality Inspection Pipeline
This reference uses deep-feature modeling, an out-of-distribution detection approach. In other words, when a model sees input that differs from its training data, it marks it as an anomaly. The visual quality inspection pipeline includes data preprocessing, feature extraction, training on good images, inference on good and defective test images, and computation of evaluation metrics.
Data Preprocessing and Feature Extraction
MVTec AD is already divided into training and testing datasets, so we begin by normalizing and resizing the images to make them compatible with the feature extractor model. We resize every image to [224, 224, 3] and normalize it using the ImageNet dataset’s mean and standard deviation. Feature extraction involves extracting the high-level features from the input images using convolutional neural networks or other deep learning architectures.
Training for Anomaly Detection
This step involves training the model to identify anomalies by learning to distinguish between normal and anomalous patterns in the extracted features (Figure 1). There are three options for modeling the vision subtask:
- A pretrained backbone uses ResNet-51 v1.5 trained on large visual datasets like ImageNet.
- A contrastive learning method based on Siamese networks learns meaningful representations of the dataset without using labels. SimSiam self-supervised learning requires a data loader that can produce two different augmented images from one underlying image. The goal is to train the network to produce the same features for both images. It takes a ResNet model as the backbone and fine-tunes it on the augmented dataset to get closer feature embeddings.
- A contrastive learning method similar to SimSiam, called CutPaste, differs in the augmentations used during training. It takes a ResNet model as the backbone and fine-tunes it after applying a data augmentation strategy that cuts an image patch and pastes at a random location of a large image. This allows us to construct a high-performance model for defect detection without requiring anomalous data.
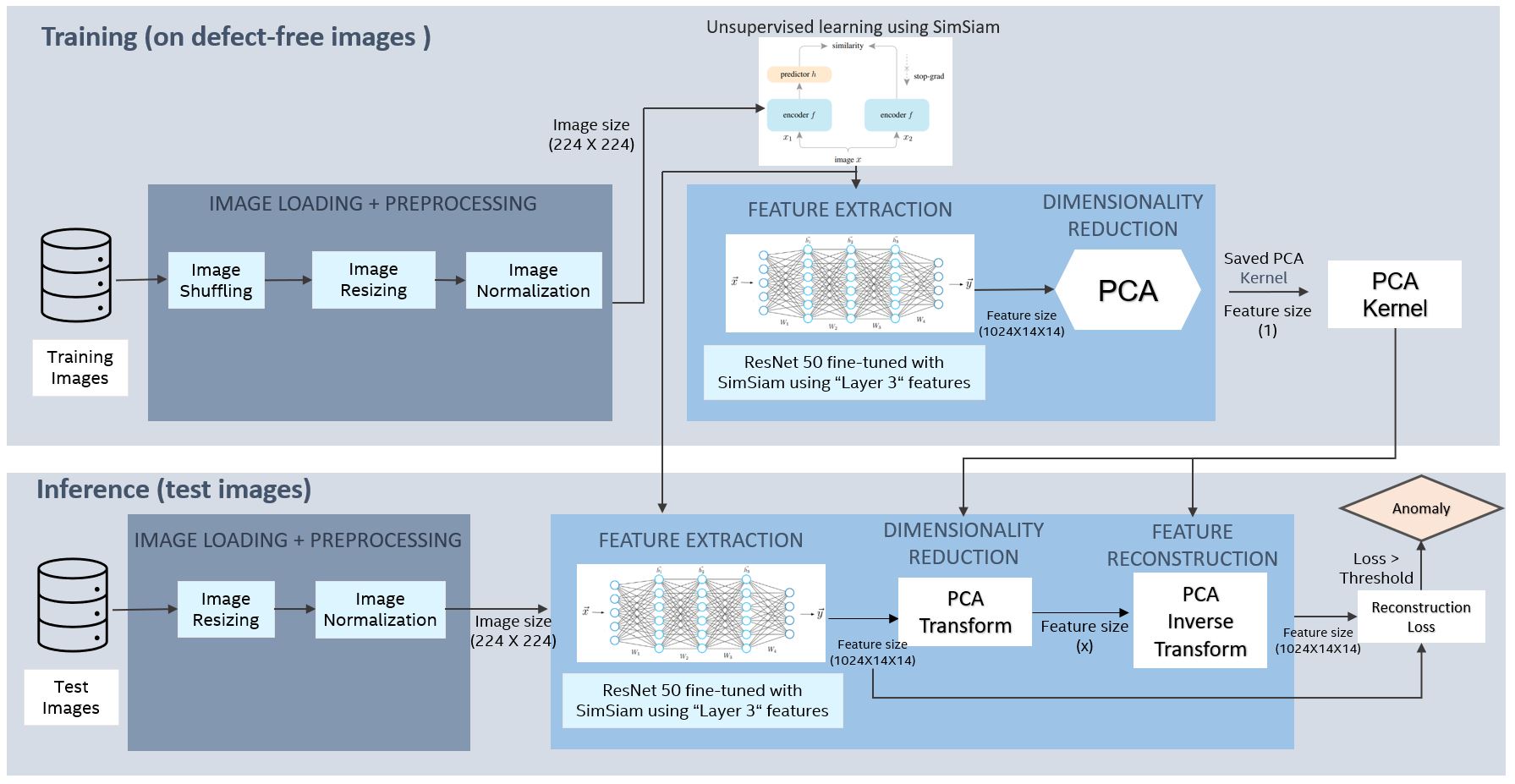
Figure 1. Visual quality inspection pipeline. This diagram is an example of SimSiam self-supervised training.
Note that the training stage only uses defect-free data. Images are loaded then shuffled, resized, and normalized. Then, one of the three transfer learning techniques is used to fine-tune a model and extract discriminative features from an intermediate layer. Principal component analysis (PCA) is used to reduce dimensionality while retaining 99% variance. This preprocessing of the intermediate features of a DNN is needed to prevent matrix singularities and rank deficiencies from arising.
Inferencing and Evaluation Metrics
During inference, the features from a test image are generated through the same network as before. We then run PCA using the previously trained PCA kernel and apply the inverse transform to recreate original features and generate a feature-reconstruction error score, which is the norm of the difference between the original feature vector and the pre-image of its corresponding reduced embedding. Any image with an anomaly will have a high error in reconstructing original features due to features being out-of-distribution from the defect-free training set. The effectiveness of these scores in distinguishing the good images from the anomalous images is assessed by plotting the receiver operating characteristic (ROC) curve, which is a plot of the true positive rate of the classifier against the false positive rate as the classification score-threshold is varied. The area under ROC (AUROC) metric summarizes this curve between 0 to 1, with 1 indicating perfect classification.
Results
Sample output from running this visual quality inspection reference code is shown in Table 2.

Above results are on single-node, dual-socket 4th Generation Intel® Xeon® Scalable 8480+ processor with 56 cores per socket, Intel® Turbo Boost Technology enabled, Intel® Hyper-Threading Technology enabled, 1024 GB memory (16 x 64GB), Configured memory speed=4800 MT/s, INTEL SSDSC2BA012T4, CentOS Linux 8, BIOS=EGSDCRB.86B.WD.64.2022.29.7.13.1329, CPU Governor=performance, intel-extension-for-pytorch v2.0.0, torch 2.0.0, scikit-learn-intelex v2023.1.1, pandas 2.0.1. Configuration: precision=bfloat16, batch size=32, features extracted from pretrained resnet50v1.50 model.
Table 2. Accuracy of our anomaly detection reference case
Concluding Remarks
We demonstrated an anomaly detection reference kit that uses deep feature extraction and out-of-distribution detection. It uses a tunable, modular workflow for fine-tuning the model and extracting its features, both of which use the Intel Transfer Learning Tool underneath. For optimal performance on Intel architectures, the scripts are also enabled with Intel® Extension for PyTorch*, Intel® Extension for Scikit-learn*, and the option to run bfloat16 on 4th Gen Intel® Xeon® Scalable processors using Intel® Advanced Matrix Extensions (Intel® AMX).
The architecture consists of a reference use case that runs mixed-method, multimodel prediction on out-of-distribution industrial anomalous samples (Figure 2). The fine-tuning module is made available as a separate composable and modular workflow that uses the Intel Transfer Learning Toolkit. The modular architecture improves productivity and reduces time-to-solution. Transfer learning methods are made available through an independent workflow that seamlessly uses Intel Transfer Learning Tool APIs underneath. A config file allows the user to change parameters and settings without having to do significant code modifications. There is flexibility in selecting pretrained models and intermediate layers for feature extraction. The reference kit is enabled with Intel-optimized foundational tools that provide performance out-of-box.

Figure 2. The reference kit architecture
To customize this reference kit, tunable configurations and parameters are exposed using YAML config files allowing users to change model training hyperparameters, datatypes, paths, and dataset settings without having to modify or search through the code. The reference kit can easily be adopted to your dataset by simply arranging the images for training and testing in the folder structure:

Note that this approach only uses good images for training. For example, to run it for the Marble Surface Anomaly Detection dataset in Kaggle, download the dataset and update the train folder to only include the Good folder. Move the sub-folders with anomalous images in train folder to either the corresponding test folders or delete them.
You can also plug-in your own pretrained customized model. Refer to the readme for more information.