
Deployment is a critical stage in the AI lifecycle that brings the model to real-world application. TorchServe is an open-source tool for efficient and flexible deployment of PyTorch* models. In production environments, the confidentiality and integrity of the model and user data are important considerations. In this article, we introduce a trusted PyTorch model serving solution built on top of Intel® Trusted Domain Extensions (Intel® TDX), confidential containers (CoCo), and BigDL Privacy Preserving Machine Learning (PPML). These technologies protect the confidentiality and integrity in TorchServe with minimal performance overhead. We also introduce Jeddak Sandbox as the best practice of this solution.
Trusted TorchServe Solution
Confidential computing is a security and privacy-enhancing technique focused on protecting data in use. A trusted execution environment (TEE) is a fundamental building block for confidential computing that creates an isolated environment within a computing system through hardware-based security features. The latest 4th Generation Intel® Xeon® Scalable processors provide a specialized TEE, called Intel TDX, that protects data inside isolated virtual machines (VM), called trust domains, from unauthorized software.
CoCo is a Cloud Native Computing Foundation (CNCF) sandbox project that provides confidentiality, integrity, and trust to containerized workloads by taking advantage of hardware TEE, remote attestation, and related software technologies. The Intel TDX confidential container solution is based on CoCo and is easy to use. Application developers can run unmodified container images in Intel TDX confidential containers. Cluster operators/administrators can use common tools to install the complete solution and manage Kubernetes* clusters. CoCo also assures strong security by providing end-to-end protection for sensitive and high-value applications, data, and models, not just at runtime but also in storage and on the network (Figure 1).
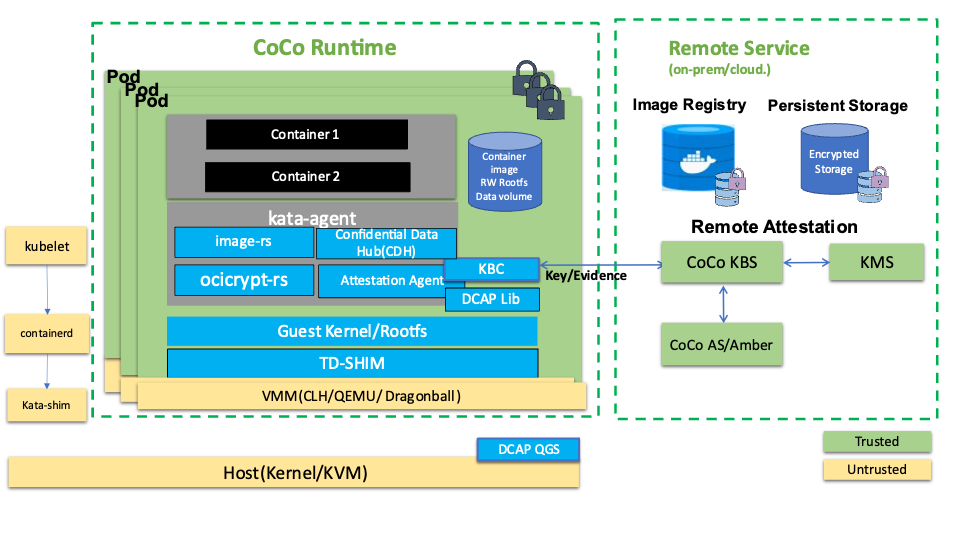
Figure 1. Intel® TDX confidential containers architecture
PPML is a new BigDL feature that addresses privacy and security in end-to-end AI and analytics applications. By combining several security technologies, like Intel® Software Guard Extensions (Intel® SGX), Intel TDX, CoCo, etc., BigDL PPML allows users to run their existing applications at scale without modification, but with hardware protection and end-to-end security (Figure 2).
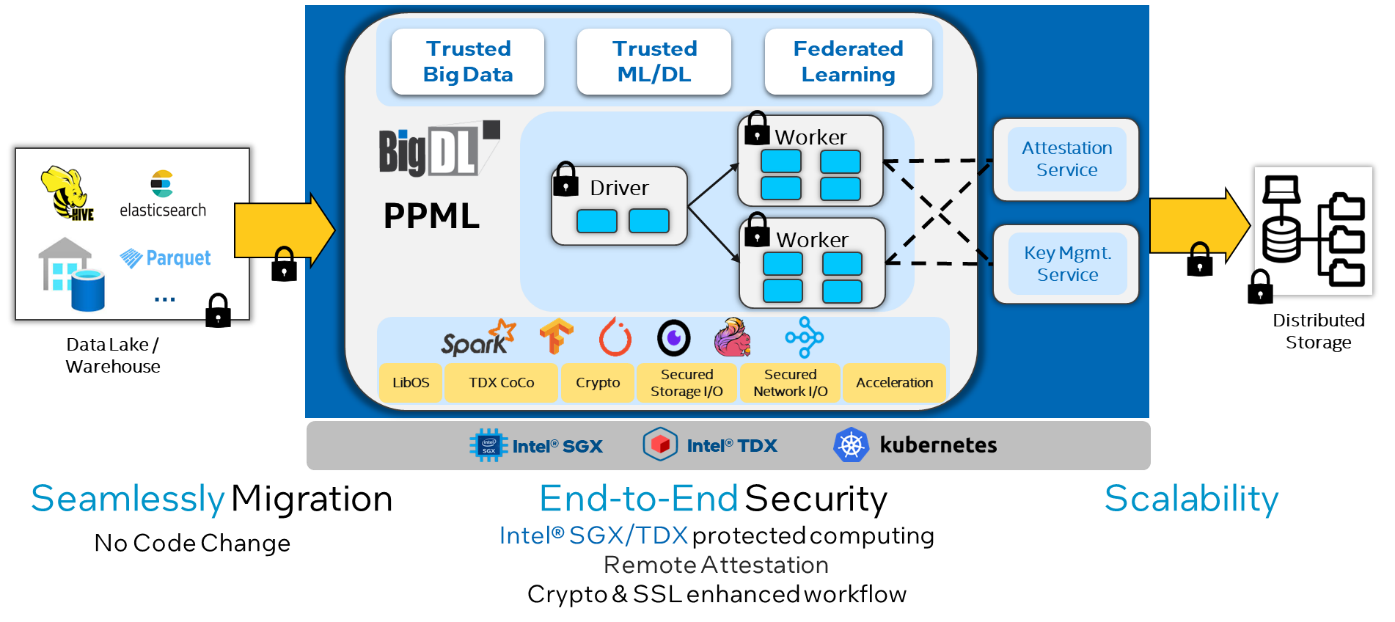
Figure 2. BigDL PPML architecture
Based on Intel TDX CoCo, BigDL PPML has built a trusted TorchServe solution that can be easily deployed on a Kubernetes cluster. As illustrated in Figure 3, it comprises three main components:
- A model store where loadable models reside
- A frontend that manages models and handles requests and responses
- Backends that process input data, run model inference, and generate responses
To protect input/output data and model, both frontend and backends run with BigDL PPML on top of Intel TDX CoCo.
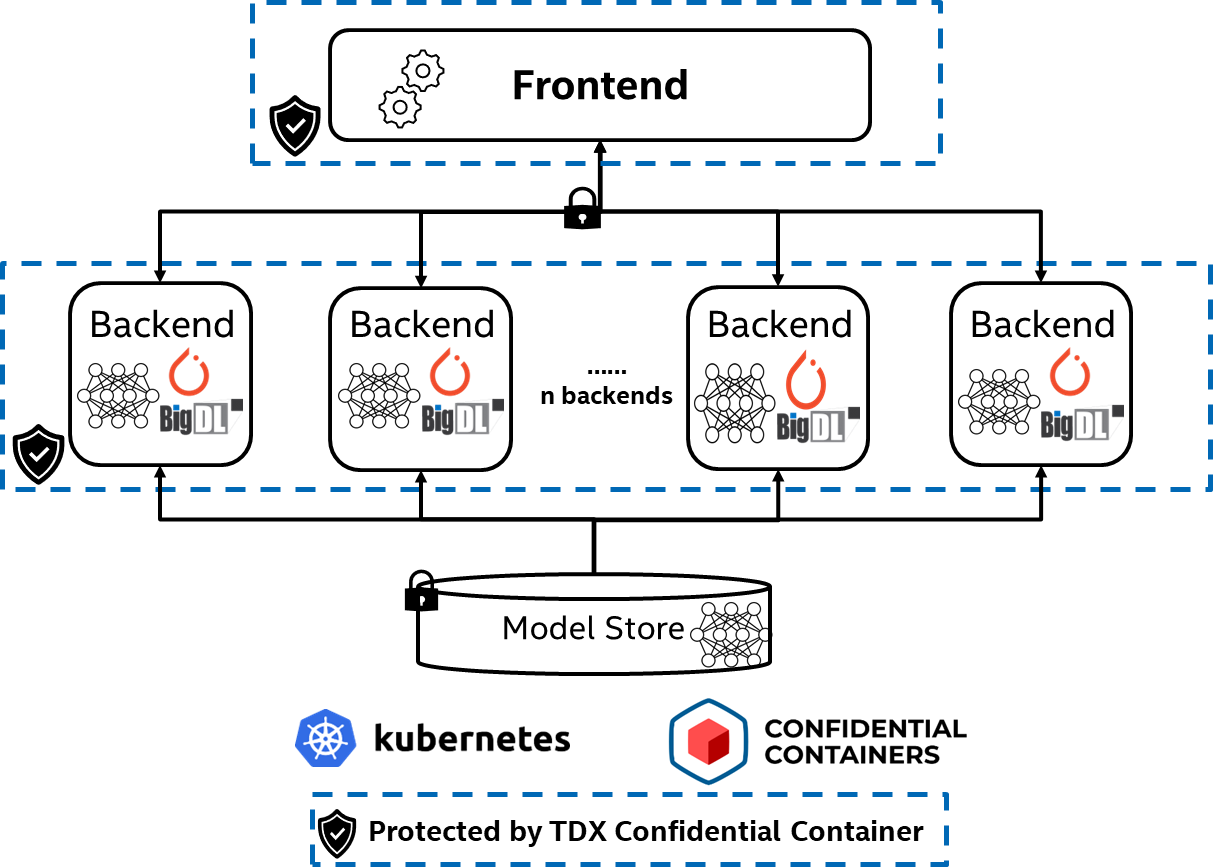
Figure 3. Trusted TorchServe on Intel® TDX confidential containers with BigDL PPML
The workflow of the trusted TorchServe solution is as follows:
- The model owner prepares the model and places it in the model store.
- The model owner launches the pod with CoCo runtime, which creates a guest VM protected by Intel TDX and starts confidential containers inside the VM.
- The model owner starts the TorchServe frontend/backend in CoCo.
- The end user sends serving requests to trusted TorchServe and receives inference responses.
In this workflow, both frontend and backends are protected by Intel TDX CoCo, which ensures the confidentiality and integrity of the user model and input data.
Setup Guide and Performance Best Practices
Prepare Model
To deploy a model with TorchServe, a model file with a specific mar format is required (a zip archive containing all model artifacts). Generally, users need to prepare trained model checkpoint and custom model handler code, and then feed them to the torch-model-archiver tool of TorchServe to generate the model file. Furthermore, to obtain maximum performance on Intel® platforms, we recommend optimizing the model with BigDL Nano. This tool helps users leverage various software optimizations, including Intel® Extension for PyTorch (IPEX), JIT, and low-precision datatypes (e.g., BF16 and INT8).
Set Up and Configure the Environment
Before setting up the trusted TorchServe environment, make sure CoCo operator is installed on a Kubernetes cluster. Then, we need to configure and start CoCo within k8s pods for trusted TorchServe to run. To isolate front-end and back-end resources for better performance, we separate the two components into different pods, and pin different sets of CPU cores to each pod.
Set up Kubernetes static CPU manager policy to enable CPU cores pinning of containers by kubelet configuration:
kubeReserved: cpu: "200m" memory: "1Gi" systemReserved: cpu: "200m" memory: "1Gi" cpuManagerPolicy: static topologyManagerPolicy: best-effort
Configure the container runtime class to run the pod with Intel TDX CoCo and allocate resources for frontend and backend pods. Note that CPU resources need to be integer and equal values for requests and limits to enable CPU pinning for containers. For example:
… spec: runtimeClassName: kata-qemu-tdx containers: - name: torchserve-backend image: intelanalytics/bigdl-ppml-trusted-dl-serving-gramine-ref:multipods-8G imagePullPolicy: Always … resources: limits: cpu: "48" memory: "64Gi" requests: cpu: "48" memory: "64Gi"
Configure resources for frontend and backend guest VMs. Note that the VCPU and memory resource should align with the configuration for pods in the previous step. For example:
default_vcpus = 48 default_memory = 65536
Launch pods for TorchServe frontend and backend.
Start TorchServe
After the frontend/backend pods are launched and confidential containers are automatically created inside the pods, we can start frontend and backend components inside the corresponding containers. To achieve optimal performance on a multicore or multisocket server, we recommend starting multiple backend workers and binding CPU cores and memory of the same NUMA node to each backend worker. We can specify the backend worker number in the TorchServe configuration file, and then use the numactl utility to start the backend worker processes.
Performance Benchmark
We measured the performance of trusted TorchServe on Intel TDX CoCo with BigDL PPML for the BERT-Large model on a two-socket 4th Gen Intel Xeon Scalable processor server. For the benchmark, we allocated two cores and 5 GB memory for the frontend pod, 48 cores and 64 GB memory for the backend pod, initiated 12 backend workers and four cores pinned to each worker. We used BigDL Nano to optimize model serving performance with low precision inference that utilizes Intel® Advanced Matrix Extensions (Intel® AMX) acceleration. We evaluated the end-to-end throughput of model serving at FP32, BF16, and INT8 precision. The performance of the trusted TorchServe solution protected by Intel TDX CoCo is comparable to the unprotected case (Figure 4). The overhead is typically less than 6%.
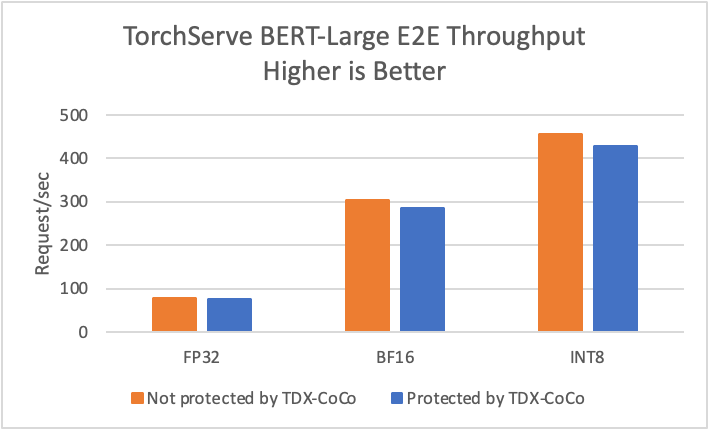
Figure 4. TorchServe BERT-Large performance
Best Practice in ByteDance
ByteDance has announced Jeddak Sandbox, which provides secure and efficient machine learning services for both internal and external enterprise users. This solution assists users in addressing various privacy compliance challenges in AI scenarios, empowering users to leverage the full value of their data. Jeddak Sandbox collaborates closely with BigDL in product design, integrating its security features and performance optimizations to enhance user experience (Figure 5). This includes:
- Leveraging optimization strategies provided by BigDL Nano for convenient optimization of deployed models, accelerating model inference processes, and reducing response latency for user prediction requests.
- Employing Intel TDX CoCo as the deployment method for online prediction services. This approach provides hardware-based protection for the entire serving process and combines the robust container orchestration capabilities of K8S for seamless scaling to address complex and dynamic request workloads.
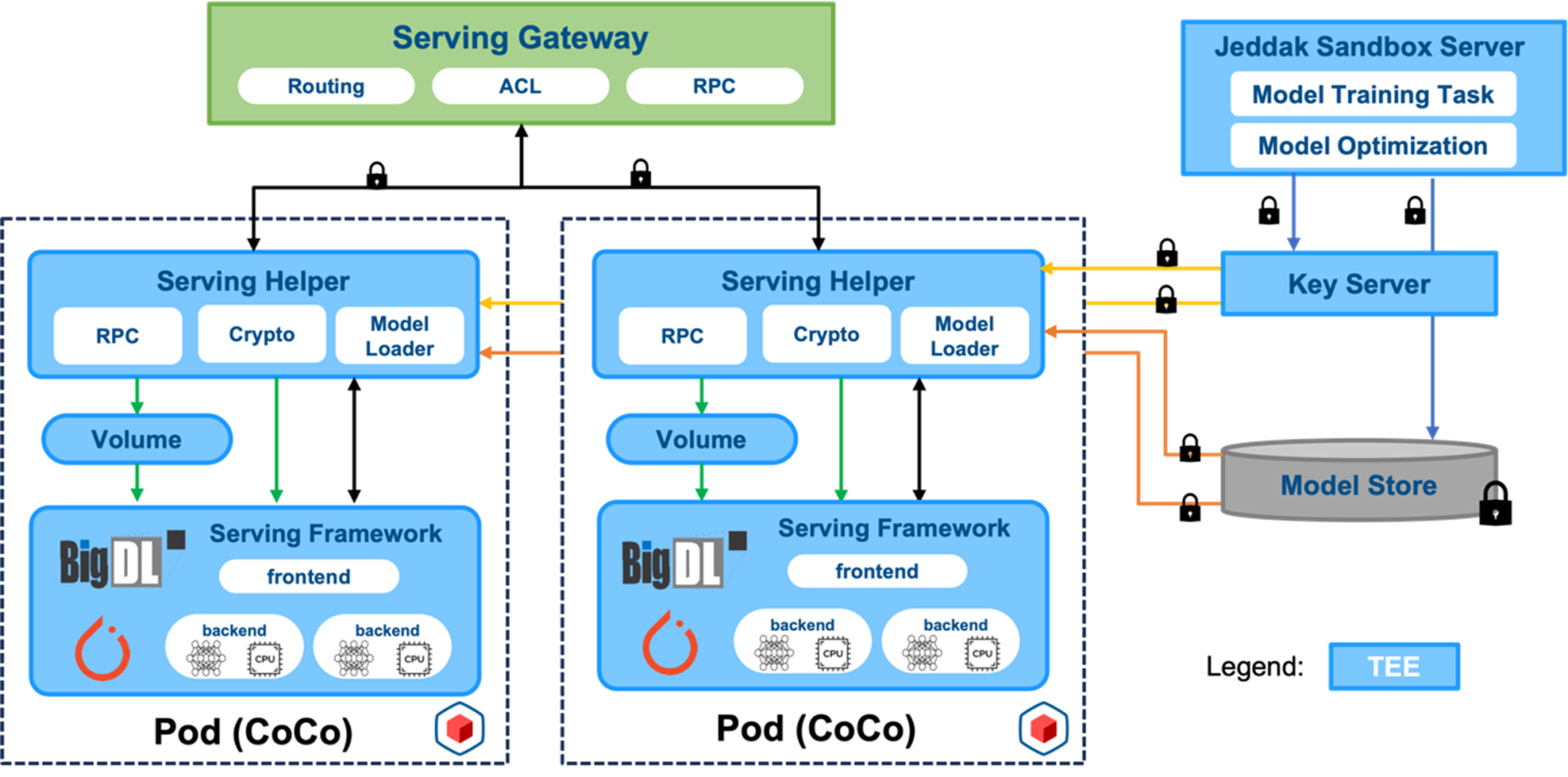
Figure 5. ByteDance Jeddak Sandbox architecture
Jeddak Sandbox provides further security enhancements during the model prediction process. This includes end-to-end encryption of user inference requests to ensure that user private data is only decrypted within a hardware-protected environment. Additionally, the solution incorporates an authentication and authorization mechanism for model requests, ensuring comprehensive protection for user model access and preventing intellectual property leaks.
Conclusion
We introduced a trusted TorchServe solution powered by CoCo and BigDL PPML on Intel TDX, where the serving components are isolated in trusted domains protected from unauthorized software. By combining the strength of Intel TDX, CoCo, and Intel AMX acceleration, the solution enables users to deploy PyTorch models in a secure, flexible, and performant manner. We also highlighted the ByteDance Jeddak Sandbox that integrates the trusted TorchServe solution. We are continuously incorporating new features, such as model store encryption/decryption and distributed backend worker deployment to further enhance the end-to-end security and flexibility in the model-serving pipeline.
Hardware and Software Configuration
Benchmarking was conducted by Intel on the following platform:
|
Platform |
4th Gen Intel Xeon Scalable processors |
|---|---|
|
Server |
Intel Xeon Platinum 8475B Processor Hyperthreading OFF 512GB DRAM |
|
Host System Software |
Ubuntu 22.04.2 LTS Kernel 5.19.0-mvp15v2+4-generic |
|
Guest System Software |
Ubuntu 20.04 Kernel vmlinuz-5.15-plus-TDX-102cc-tdx Qemu v7.1.0 Libvirt 8.6.0-2022.11.17.mvp2.el8 (tdxlibvirt-2022.11.17) TDVF mvp6-stable202211 TDX SEAM 1.0.01.01-mvp29.el8 |
|
Cloud Native Software |
Kubernetes v1.24.0 CoCo v0.5.0 |
|
DL Framework |
TorchServe 0.7.1 PyTorch 1.13.1 IPEX 1.13.100 Transformers 4.29.1 BigDL 2.4.0 snapshot |
|
Test Date |
06/19/2023 |