
The increasing popularity of artificial intelligence (AI) in today’s world demands the introduction of low precision datatypes and hardware support for these datatypes to boost performance. Low precision models are faster in computation and have lower memory footprints. For these reasons, low precision datatypes are preferred for both AI training and inferencing over 32-bit datatypes. To optimize and support these low precision datatypes, hardware needs special features and instructions. Intel provides these in the form of Intel® Advanced Matrix Extensions (Intel® AMX) and Intel® Xᵉ Matrix Extensions (Intel® XMX) on Intel® CPUs and GPUs, respectively. Some of the most used 16- and 8-bit formats are 16-bit IEEE floating point (fp16), bfloat16, 16-bit integer (int16), 8-bit integer (int8), and 8-bit Microsoft floating point (ms-fp8). The differences between some of these formats are shown in Figure 1.
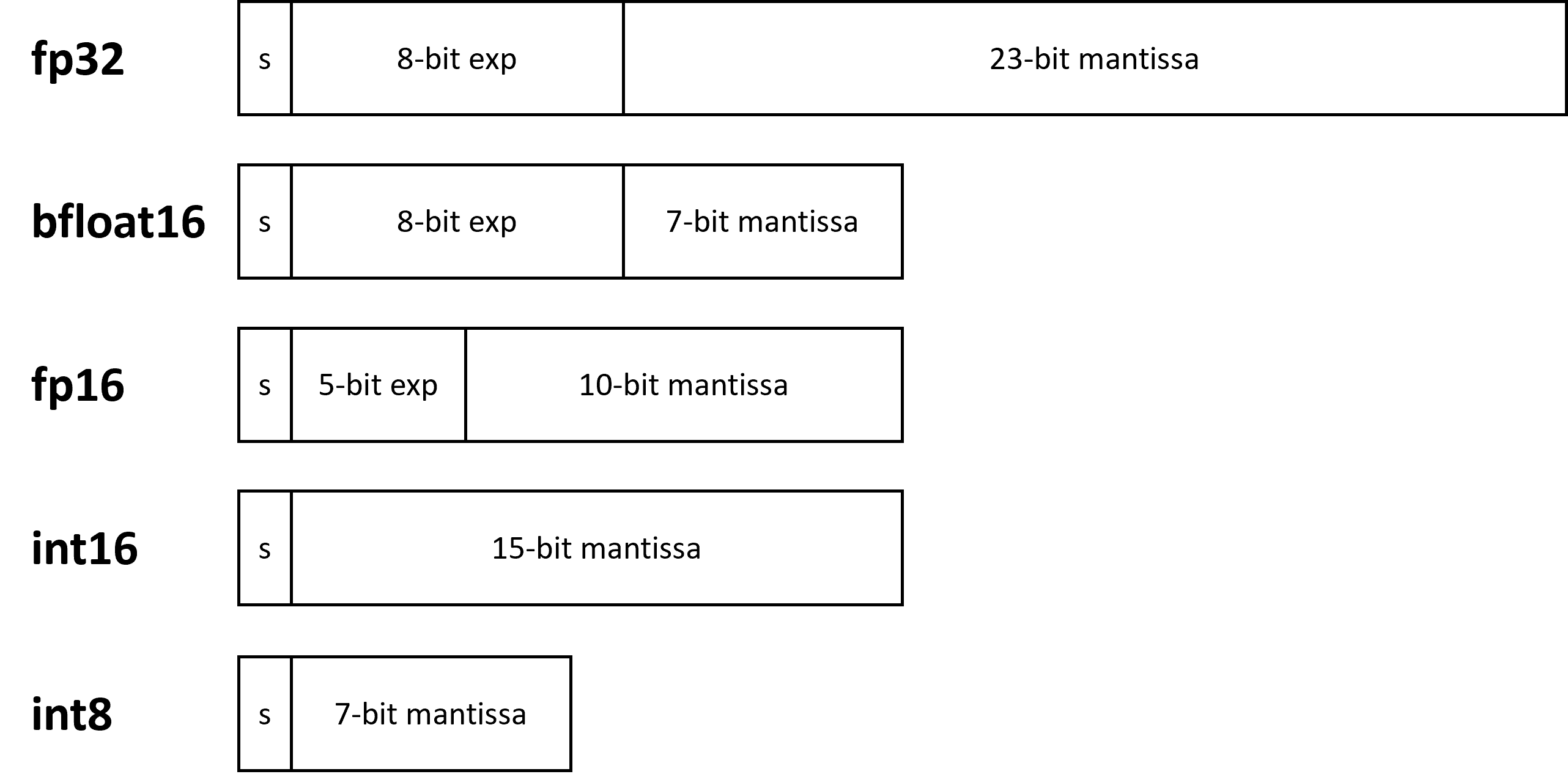
Figure 1. Various numerical representations of IEEE standard datatypes. The s stands for the signed bit (0 for positive numbers and 1 for negative numbers) and exp stands for the exponent.
There are different programming paradigms to invoke Intel AMX and Intel XMX on their respective hardware. This paper will provide an understanding of the different ways to program them, and then demonstrate the performance benefits of these instruction sets.
Intel® AMX and Intel® XMX
Intel AMX
Intel AMX are extensions to the x86 instruction set architecture (ISA) for microprocessors. It uses 2D registers, called tiles, upon which accelerators can perform operations. There are typically eight tiles in one unit of Intel AMX. The tiles can perform load, store, clear, or dot product operations. Intel AMX supports int8 and bfloat16 datatypes. Intel AMX is supported in 4th Generation Intel® Xeon® Scalable processors (Figure 2).
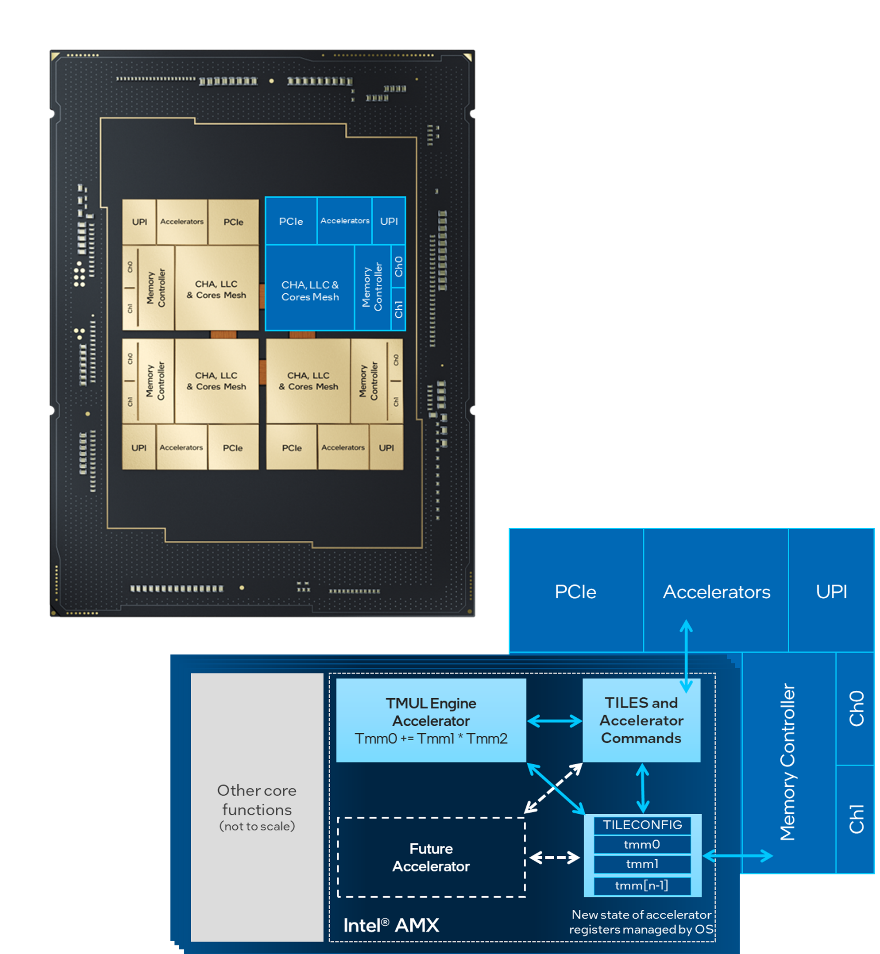
Figure 2. Intel® AMX in 4th Gen Intel® Xeon® Scalable processors
Intel XMX
Intel XMX, also known as Dot Product Accumulate Systolic (DPAS), specializes in executing dot product and accumulate instructions on 2D systolic arrays. A systolic array in parallel computer architecture is a homogeneous network of tightly coupled data processing units. Each unit computes a partial result as a function of data received from its upstream neighbors, stores the result within itself, and passes it downstream. Intel XMX supports numerous datatypes, like int8, fp16, bfloat16, and tf32, depending on the hardware generation. It is a part of the Intel® Data Center GPU Max or Intel Data Center GPU Flex Series. The Intel® Xᵉ HPC 2 Stack in Intel Data Center GPU Max is abbreviated as Xᵉ in Figure 3. Stack is the term alternately used for tiles. Each Intel Data Center GPU Max consists of eight Intel Xᵉ slices. Each slice contains 16 Intel Xᵉ cores. Each core contains eight vector and eight matrix engines.

Figure 3. Intel® XMX in Intel® Data Center GPU Max (formerly code-named Ponte Vecchio)
Programming with Intel AMX and Intel XMX
Users can interact with Intel XMX at many different levels: deep learning frameworks, dedicated libraries, custom SYCL kernels, all the way down to low-level intrinsics. Figure 4 shows how Intel AMX and Intel XMX can be invoked through different coding abstractions, which will be discussed below. The Intel® oneAPI Base Toolkit 2024.0 is required to take advantage of these extensions.
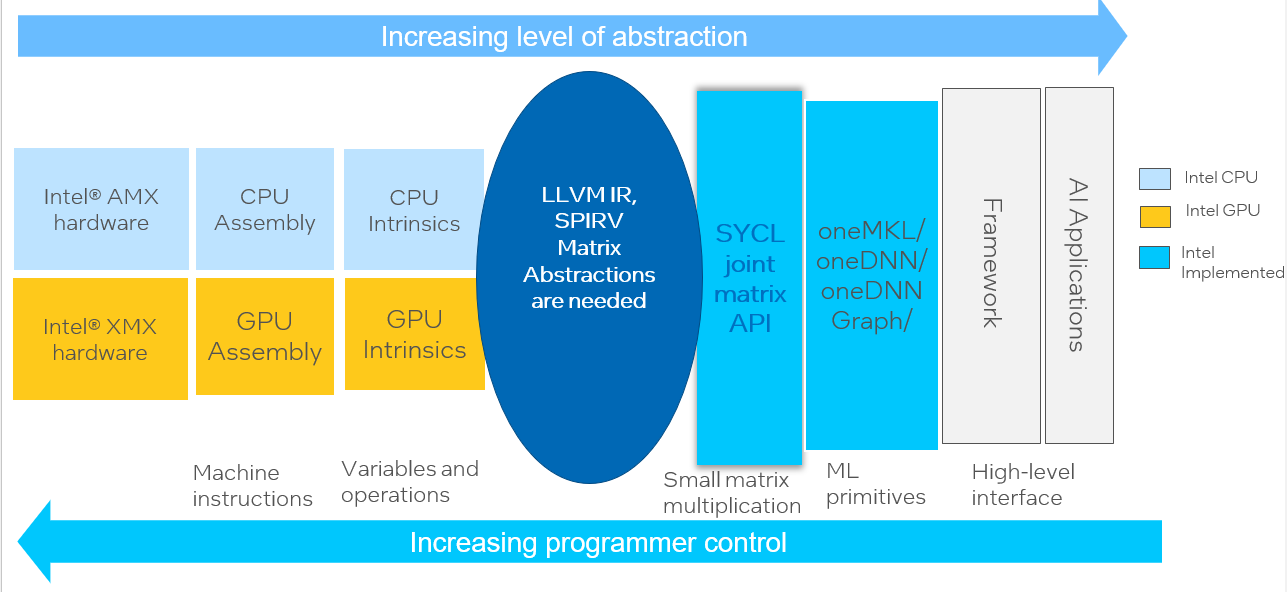
Figure 4. Programming abstractions for matrix computing
SYCL* Joint Matrix Extension
Joint matrix is a new SYCL* extension that unifies targets like Intel AMX for CPUs, Intel XMX for GPUs, and NVIDIA* Tensor Cores for Tensor Hardware programming. These SYCL joint matrix examples show how to use this extension. Users who want to build their own neural networks applications can use joint matrix, which has a lower level of abstraction than frameworks like TensorFlow* and libraries like Intel® oneAPI Deep Neural Network Library (oneDNN) and Intel® oneAPI Math Kernel Library (oneMKL). It provides a unified interface that is not only portable but also benefits from the maximum performance that different hardware can offer. Joint matrix provides performance, productivity, and fusion capabilities along with portability to different tensor hardware, thus eliminating the need to maintain different codebases for each hardware platform.
The term “joint matrix” emphasizes that the matrix is shared among a group of work items and is not private to each work item (Figure 5). Though the group scope is added as an additional template parameter in the SYCL joint matrix syntax, only subgroup scope is supported in the current implementation. Some of the functions needed to perform common operations on matrices, namely load, store, and the “multiply and add” operation, are represented by joint_matrix_load, joint_matrix_store, and joint_matrix_mad respectively. They in turn call the lower-level Intel AMX or Intel XMX intrinsics depending on the hardware on which the program is running. The joint_matrix_load function loads data from memory to the 2D tiles/registers, joint_matrix_store stores the data in the accumulator matrix from the 2D tiles back to memory, and joint_matrix_mad performs the multiply operation on the two matrices, accumulates the result with third matrix and returns the result.
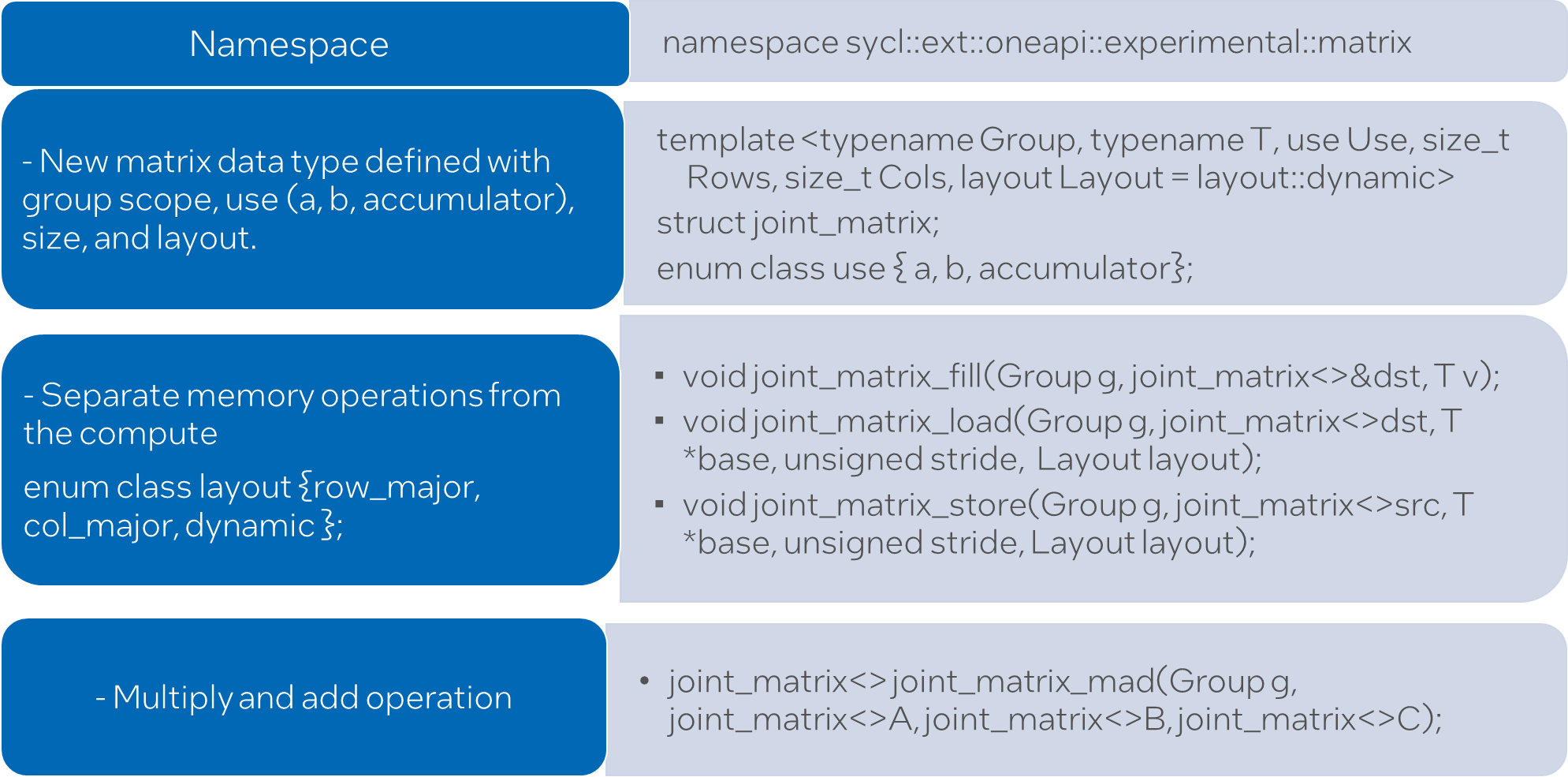
Figure 5. Common SYCL* joint matrix APIs
Intel® oneAPI Deep Neural Network Library (oneDNN) and Intel® oneAPI Math Kernel Library (oneMKL)
Intel® oneAPI Deep Neural Network Library (oneDNN) and Intel® oneAPI Math Kernel Library (oneMKL) use Intel AMX and Intel XMX by default on Intel CPUs (4th Gen Intel Xeon Scalable processors onwards) and Intel Data Center GPU Max, respectively. The oneDNN user needs to make sure the code uses datatypes supported by Intel XMX, and the oneDNN library must be built with GPU support enabled. The matmul_perf example bundled with oneDNN will invoke Intel AMX and Intel XMX when compiled appropriately. Additional oneDNN examples are available here. A simple oneMKL example is available here.
Performance Analysis for Intel AMX
Let’s compare matrix multiplication performed on standard fp32 vs. bfloat16. The benchmark that we use is essentially a simple wrapper to repeated calls to GEMM. Based on our compilation, we can pass the following options:
- The Intel® Math Kernel Library (Intel® MKL) version of the GEMM kernel
- Single- or double-precision GEMM (SGEMM/DGEMM)
- The number of threads (NUM_THREADS) to use
- The size (SIZE_N) of the matrices being multiplied.
The benchmark code takes the problem size, allocates space for the C = A x B matrices, initializes the A and B matrices with random data, calls GEMM one time for initialization, makes consecutive calls to GEMM for a preset number of times, and measures the execution time of the latter. We can see that bfloat16 outperforms fp32 (Figure 6).
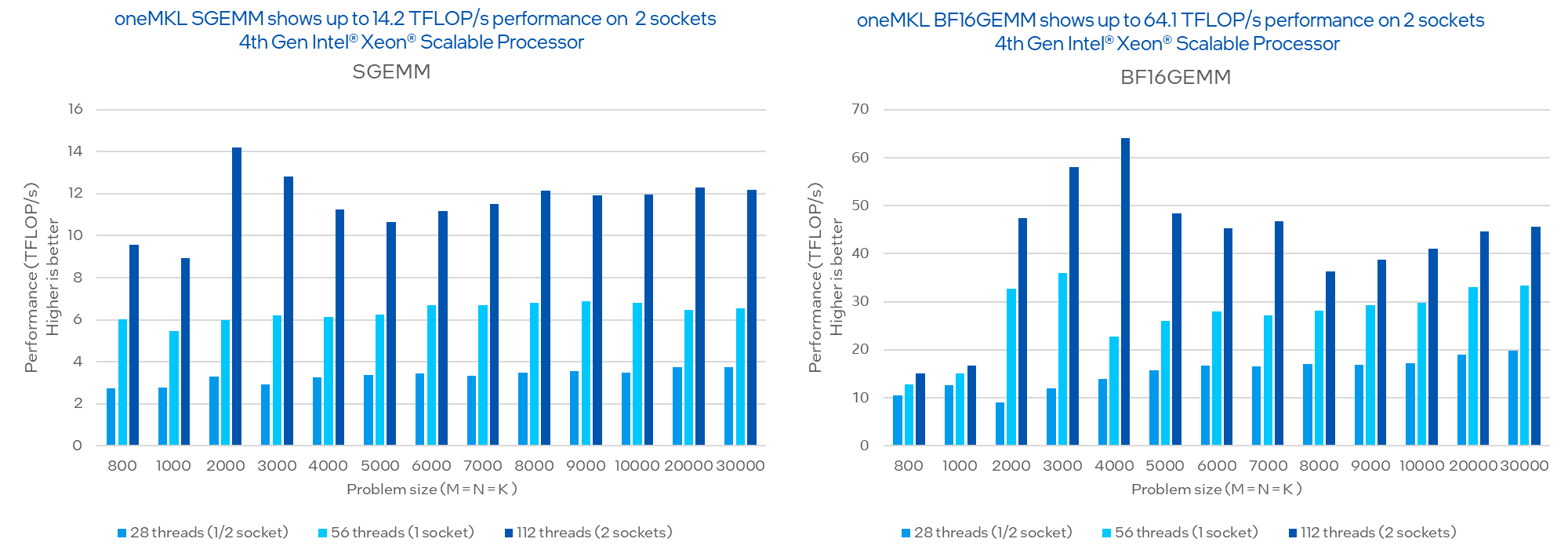
Testing: Performance results are validated with 2024.0 and no performance regression compared to 2023.x release is observed
Configuration Details and Workload Setup: 1-node, 2x Intel® Xeon® Platinum 8480+ processor on Denali Pass platform with 1024 GB (16 slots/ 64GB/ 4800) total DDR5 memory, ucode 0x2b000161, HT off, Turbo on, Ubuntu 22.04.1 LTS, 5.17.0-051700-generic, 1x Intel SSD 3.5TB OS Drive; Intel® oneAPI Math Kernel Library 2023.0 (oneMKL). SGEMM and BFLOAT16GEMM performance for square matrix dimensions between 800 and 30,000. Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See configuration disclosure for details. No product or component can be absolutely secure. Performance varies by use, configuration, and other factors. Learn more at www.Intel.com/PerformanceIndex. Your costs and results may vary.
Notices and Disclaimers: Performance varies by use, configuration, and other factors. Learn more on the Performance Index site. Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be secure. Your costs and results may vary. Intel technologies may require enabled hardware, software, or service activation.© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
Configuration Details: one Intel® Data Center GPU Max 1550 hosted on a two-socket Intel Xeon 8480+ processor, 512 GB DDR5-4800, Ubuntu 22.04, Kernel 5.15, IFWI 2023WW28, oneMKL 2023.1, ICX 2023.1.
Figure 6. Matrix multiplication performance comparison using the fp32 and bfloat16 datatypes
Performance Analysis for Intel XMX
We will now investigate the performance benefits of Intel XMX on Intel GPUs using this oneMKL GEMM benchmark. oneMKL supports several algorithms for accelerating single-precision GEMM via Intel XMX. Bfloat16x2 and bfloat16x3 are two such algorithms for using bfloat16 systolic hardware to approximate single-precision GEMMs. Internally, single-precision input data is converted into bfloat16 and multiplied with the systolic array. The three variants — bfloat16, bfloat16x2, and bfloat16x3 — allow you to choose a tradeoff between accuracy and performance, with bfloat16 being the fastest and bfloat16x3 the most accurate (similar to standard GEMM). However, all three outperform standard float (Figure 7).
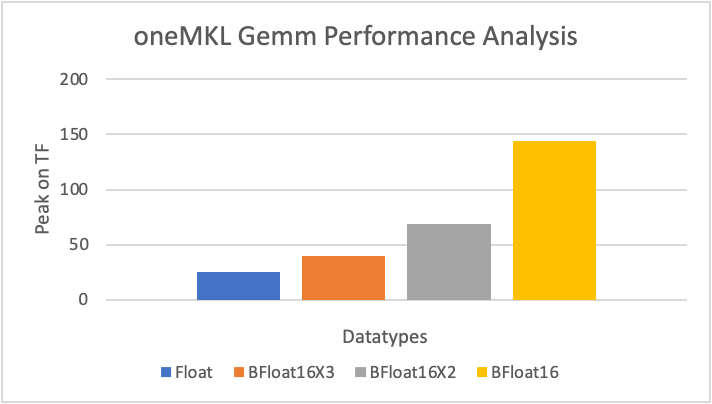
Configuration Details: one Intel® Data Center GPU Max 1550 hosted on a two-socket Intel® Xeon® 8480+ processor, 512 GB DDR5-4800, Ubuntu 22.04, Kernel 5.15, IFWI 2023WW28, Intel® oneAPI Math Kernel Library 2023.1 (oneMKL), ICX 2024.0. Code used from https://github.com/oneapi-src/oneAPI-samples/tree/master/Libraries/oneMKL/matrix_mul_mkl
Notices and Disclaimers: Performance varies by use, configuration, and other factors. Learn more on the Performance Index site. Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be secure. Your costs and results may vary. Intel technologies may require enabled hardware, software, or service activation.© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
Figure 7. Benchmarking oneMKL GEMM performance for different datatypes and algorithms
Conclusion
This article gave an overview of the Intel AMX and Intel XMX instruction sets introduced in the latest Intel CPUs and GPUs. Intel AMX and Intel XMX instruction sets can be invoked through different levels of programming, starting from compiler intrinsics to the SYCL Joint Matrix abstraction, to oneMKL and oneDNN. The further abstracted the coding paradigm is, the easier it is to invoke these instruction sets and the lesser the programmer’s control on the invocation. Intel AMX and Intel XMX are performance boosters. The example of the GEMM benchmark on the 4th Gen Intel Xeon Scalable processor gives a clear understanding of how the performance is boosted by merely making use of the appropriate low precision datatypes and invoking Intel AMX. Also, the example of the GEMM benchmark on the Intel Data Center GPU Max 1550 gives a clear understanding of how the performance is boosted by merely making use of the appropriate low precision datatypes and invoking Intel XMX. Due to its performance benefit, ease of use and the ability to be programmed through low level programming, as well as through libraries and frameworks, users are recommended to test and use these extensions in their AI workloads.