Scheduling Overhead in Intel® Threading Building Blocks (Intel® TBB) Apps
This recipe shows how to detect and fix scheduling overhead for an Intel TBB application.
Scheduling overhead is a typical problem of code threading when fine-grain chunks of work between threads are distributed dynamically. In the case of scheduling overhead, a significant amount of time spent by the scheduler to assign the work for working threads and the time worker threads spend waiting for a new portion of work make parallelism inefficient and, in ultimate cases, a threaded version of a program can be even slower than the sequential one. The majority of Intel TBB constructs use a default auto-partitioner that tailors the number of chunks larger than the default grain size to avoid overhead. If you use a simple partitioner either intentionally or with constructs like parallel_deterministic_reduce, you need to take care of a grain size since a simple partitioner divides the work into chunk sizes up to the default grain size of one iteration. Intel® VTune™ Amplifier helps detect scheduling overhead for Intel TBB applications and provides some advice on increasing the grain size to avoid a slowdown connected with it.
Ingredients
This section lists the hardware and software tools used for the performance analysis scenario.
Application: a sample application that calculates the sum of vector elements using Intel TBB parallel_deterministic_reduce template function.
Compiler : Intel® Compiler or GNU* compiler with compiler/linker options, for example:
-I <tbb_install_dir>/include -g -O2 -std=c++11 -o vector-reduce vector-reduce.cpp -L <tbb_install_dir>/lib/intel64/gcc4.7 -ltbb
Performance analysis tools: Intel® VTune™ Amplifier 2019: Threading analysis
NOTE:Starting with the 2020 release, Intel® VTune™ Amplifier has been renamed to Intel® VTune™ Profiler.
Most recipes in the Intel® VTune™ Profiler Performance Analysis Cookbook are flexible. You can apply them to different versions of Intel® VTune™ Profiler. In some cases, minor adjustments may be required.
Get the latest version of Intel® VTune™ Profiler:
From the Intel® VTune™ Profiler product page.
Download the latest standalone package from the Intel® oneAPI standalone components page.
Operating system: Ubuntu* 16.04 LTS
CPU: Intel Xeon® CPU E5-2699 v4 @ 2.20GHz
Create a Baseline
The initial version of the sample code uses parallel_deterministic_reduce with the default grain size (line 17-23):
#include <stdlib.h>
#include "tbb/tbb.h"
static const size_t SIZE = 50*1000*1000;
double v[SIZE];
using namespace tbb;
void VectorInit( double *v, size_t n )
{
parallel_for( size_t( 0 ), n, size_t( 1 ), [=](size_t i){ v[i] = i * 2; } );
}
double VectorReduction( double *v, size_t n )
{
return parallel_deterministic_reduce(
blocked_range<double*>( v, v + n ),
0.f,
[](const blocked_range<double*>& r, double value)->double {
return std::accumulate(r.begin(), r.end(), value);
},
std::plus<double>()
);
}
int main(int argc, char *argv[])
{
task_scheduler_init( task_scheduler_init::automatic );
VectorInit( v, SIZE );
double sum;
for (int i=0; i<100; i++)
sum = VectorReduction( v, SIZE );
return 0;
}The vector sum calculation is repeated in the loop in line 35 to make compute work more significant and measurable for statistical analysis.
Running the compiled application takes about 9 seconds. This is a performance baseline that could be used for further optimizations.
Run Threading Analysis
To estimate threading parallelism of your application and time spent on scheduling overhead, run the Concurrency analysis:
Click the
 New Project button on the toolbar and specify a name for the new project, for example: vector-reduce.
New Project button on the toolbar and specify a name for the new project, for example: vector-reduce. Click Create Project.
The Configure Analysis window opens.
On the WHERE pane, select the Local Host target system type.
On the WHAT pane, select the Launch Application target type and specify an application for analysis.
On the HOW pane, click the browse button and select Parallelism > Threading analysis.
Click the
 Start button.
Start button.
VTune Amplifier launches the application, collects data, finalizes the data collection result resolving symbol information, which is required for successful source analysis.
Since the analysis is based on instrumentation and uses a stack stitching technology, the elapsed time of the instrumented application can be slower than the original application run because of the collection overhead.
Identify Scheduling Overhead
Start your analysis with the Summary view that displays application-level statistics.
The Effective CPU Utilization Histogram shows that, on average, the application utilized only ~3 physical cores out of available 88:
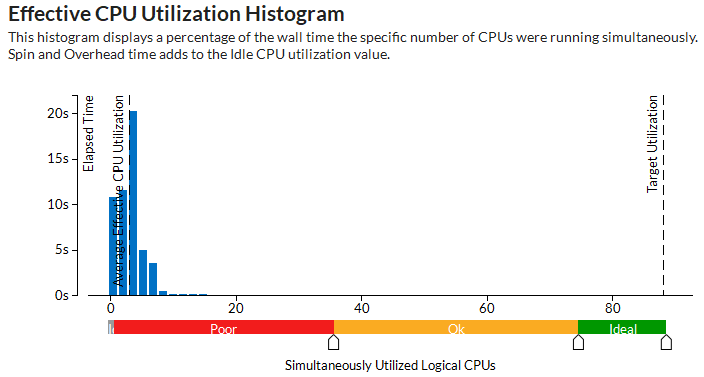
Flagged Overhead Time metric and the Scheduling sub-metric signal a threading inefficiency problem that should be explored:

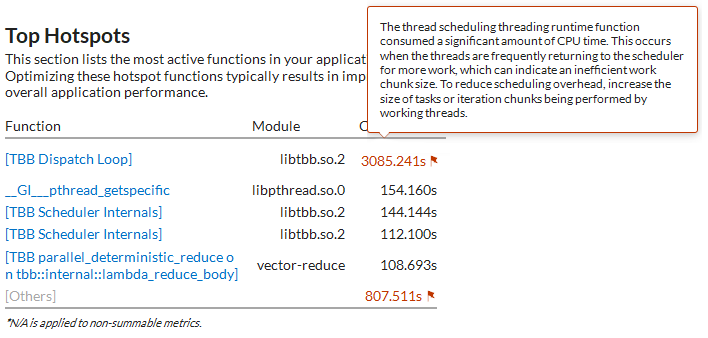
The Top Hotspots section shows [TBB Dispatch Loop] as the main time-consuming function. The hint on the flag associated with the function informs about scheduling overhead that should be addressed with increasing a grain size of parallel work:
The sample application contains two Intel TBB constructs - parallel_for initialization and parallel_deterministic_reduce - to calculate the sum of vector elements. Discover which Intel TBB construct brings overhead with the help of the Caller/Callee data view. Expanding the CPU Time: Total > Overhead Time columns sorts the grid by the Scheduling column. Find the first row with the Intel TBB parallel construct in the Function list:

This row points to the parallel_deterministic_reduce construct in the VectorReduction function that has the highest scheduling overhead. Try to make work chunks more coarse-grain to eliminate the overhead in parallelization with this construct.
To better visualize the imbalance during the application run, explore the Timeline view. Useful work shows up in green while the black color marks the time waste.
Increase Grain Size of Parallel Work
As mentioned earlier, the fine-grain chunks of work assigned to worker threads, cannot compensate the time spent by the scheduler on the work assignment. The default chunk size for parallel_deterministic_reduce that uses a simple partitioner is 1. This means that worker threads will take just one loop iteration to execute before turning back to the scheduler for a new portion of work. Consider increasing the minimal chunk size to 10000 (line 5 in the snippet below):
double VectorReduction( double *v, size_t n )
{
return parallel_deterministic_reduce(
blocked_range<double*>( v, v + n, 10000 ),
0.f,
[](const blocked_range<double*>& r, double value)->double {
return std::accumulate(r.begin(), r.end(), value);
},
std::plus<double>()
);
}And re-run the Threading analysis:
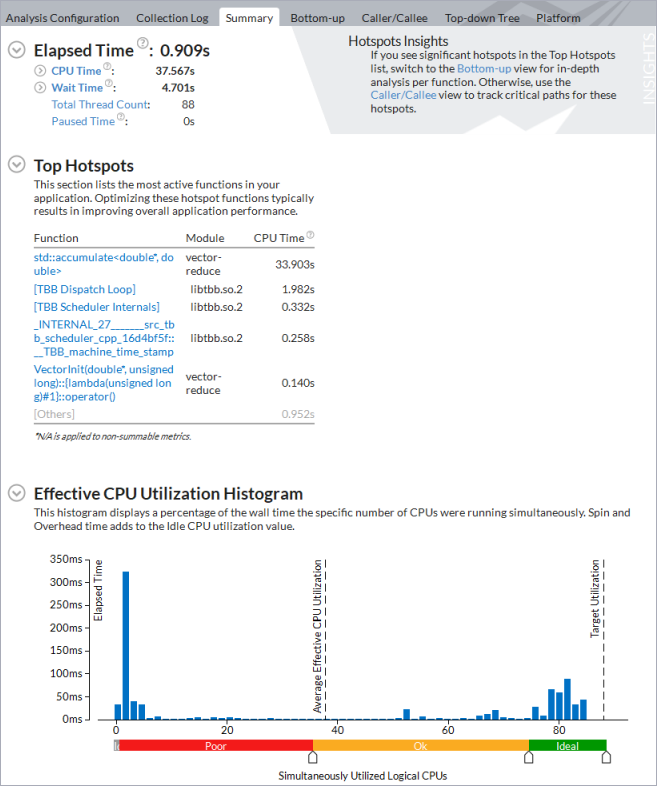
You see that the elapsed time of the application has significantly reduced, average effective CPU utilization is ~38 logical cores (because the metric counts a warmup phase, compute phase CPU Utilization is closer to 80 cores), and CPU time spent on Intel TBB scheduling or other parallel work arrangement is negligible. An overall speedup of this small code modification is more than 10X in comparison with the original version of the application run without collection time.
To discuss this recipe, visit the developer forum.