Improve Your Application Performance by Changing Communications
Improve the performance of the MPI application by changing blocking to non-blocking communications.
In your code replace the serial MPI_Sendrcv with non-blocking communication: MPI_Isend and MPI_Irecv. For example:
Original code snippet:
Updated code snippet:
Once corrected, the single iteration of the revised application will look like the following example:
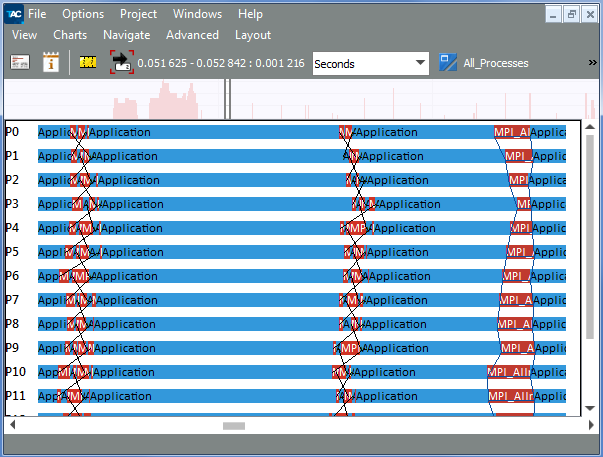
Use the Intel Trace Analyzer Comparison view to compare the serialized application with the revised one. Compare two traces with the help of the Comparison View, going to View > Compare. The Comparison View looks similar to:
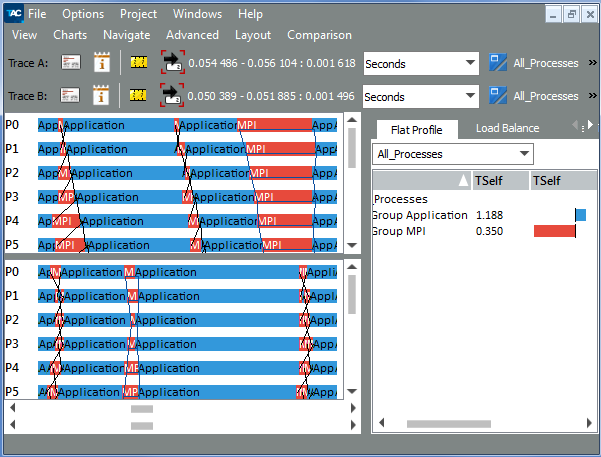
In the Comparison View, you can see that using non-blocking communication helps to remove serialization and decrease the time of communication of processes.
NOTE:
For more information about node-level performance of your application, see documentation for the respective tools: Intel® VTune™ Profiler MPI Code Analysis and Analyzing Intel® MPI applications using Intel® Advisor.
Parent topic: Get Started with Intel® Trace Analyzer and Collector