Visible to Intel only — GUID: GUID-39107A82-CADB-4A16-A254-ABC7807A37B9
Legal Information
Getting Help and Support
Introduction
Coding for the Intel® Processor Graphics
Platform-Level Considerations
Application-Level Optimizations
Optimizing OpenCL™ Usage with Intel® Processor Graphics
Check-list for OpenCL™ Optimizations
Performance Debugging
Using Multiple OpenCL™ Devices
Coding for the Intel® CPU OpenCL™ Device
OpenCL™ Kernel Development for Intel® CPU OpenCL™ device
Mapping Memory Objects
Using Buffers and Images Appropriately
Using Floating Point for Calculations
Using Compiler Options for Optimizations
Using Built-In Functions
Loading and Storing Data in Greatest Chunks
Applying Shared Local Memory
Using Specialization in Branching
Considering native_ and half_ Versions of Math Built-Ins
Using the Restrict Qualifier for Kernel Arguments
Avoiding Handling Edge Conditions in Kernels
Using Shared Context for Multiple OpenCL™ Devices
Sharing Resources Efficiently
Synchronization Caveats
Writing to a Shared Resource
Partitioning the Work
Keeping Kernel Sources the Same
Basic Frequency Considerations
Eliminating Device Starvation
Limitations of Shared Context with Respect to Extensions
Why Optimizing Kernel Code Is Important?
Avoid Spurious Operations in Kernel Code
Perform Initialization in a Separate Task
Use Preprocessor for Constants
Use Signed Integer Data Types
Use Row-Wise Data Accesses
Tips for Auto-Vectorization
Local Memory Usage
Avoid Extracting Vector Components
Task-Parallel Programming Model Hints
Visible to Intel only — GUID: GUID-39107A82-CADB-4A16-A254-ABC7807A37B9
__local Memory
Local memory can be used to avoid multiple redundant reads from and writes to global memory. But it is important to note that the SLM (which is used to implement local memory), occupies the same place in the architecture as the L3 cache. So the performance of local memory accesses is often similar to that of a cache hit. Using local memory is typically only advantageous when the access pattern favors the banked nature of the SLM array.
When local memory is used to store temporary inputs and/or outputs, there are a few things to consider:
- When reading multiple items repeatedly from global memory:
-
- You can benefit from prefetching global memory blocks into local memory once, incurring a local memory fence, and reading repeatedly from local memory instead.
- Do not use single work-item (like the one with local id of 0) to load many global data items into the local memory by using a loop. Looped memory accesses are slow, and some items might be prefetched more than once.
- Instead, designate work-items to prefetch a single global memory item each, and then incur a local memory fence, so that the local memory is full.
- When using local memory to reduce memory writes:
-
- Enable a single work-item to write to an independent area of local memory space, and do not enable overlapping write operations.
- If, for example, each work-item is writing to a row of pixels, the local memory size equals the number of local memory items times the size of a row, and each work-item indexes into its respective local memory buffer.
As we discussed earlier to optimize performance when accessing __local memory, a kernel must minimize the number of bank conflicts. As long as each work-item accesses __local memory with an address in a unique bank, the access occurs at full bandwidth. Work-items can read from the same address within a bank with no penalty, but writing to different addresses within the same bank produces a bank conflict and impacts performance.
To see how bank conflicts can occur, consider the following examples (assume a “row” work-group, <16, 1, 1>):
__local int* myArray = ...; int x; x = myArray[ get_global_id(0) ]; // case 1 x = myArray[ get_global_id(0) + 1 ]; // case 2 x = myArray[ get_global_size(0) – 1 – get_global_id(0) ]; // case 3 x = myArray[ get_global_id(0) & ~1 ]; // case 4 x = myArray[ get_global_id(0) * 2 ]; // case 5 x = myArray[ get_global_id(0) * 16 ]; // case 6 x = myArray[ get_global_id(0) * 17 ]; // case 7
Cases 1, 2, and 3 access sixteen unique banks and therefore achieve full memory bandwidth. If you use global memory array instead of a local memory array, case 2 does not achieve full bandwidth due to accesses to two cache lines. The diagram below shows case 2.
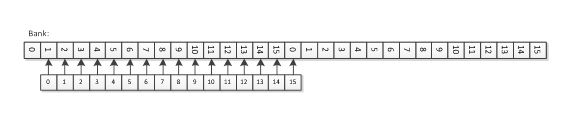
Case 4 reads from 8 unique banks, but with the same address for each bank, so it should also achieve full bandwidth.
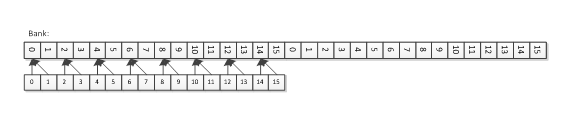
Case 5 reads from eight unique banks with a different address for each work-item, and therefore should achieve half of the bandwidth of Case 1.
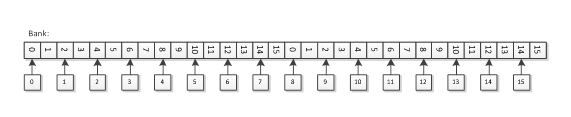
Case 6 represents a worst-case for local memory: it reads from a single bank with a different address for each work-item. It should operate at 1/16th the memory performance of Case 1.
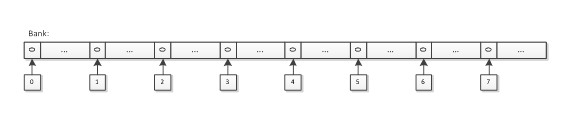
Case 7 is a stridden case similar to Case 6, but since it reads from 16 unique banks, this case also achieves full bandwidth.
The difference between Case 6 and Case 7 is important because this pattern is frequently used to access “columns” of data from a two-dimensional local memory array. Choose an array stride that avoids bank conflicts when accessing two-dimensional data from a local memory array, even if it results in a “wasted” column of data. For example, Case 7 has stride of 17 elements in compare to 16 elements in Case 6.