Visible to Intel only — GUID: GUID-010B1CB5-8497-492E-87D5-D1D80D37F667
Legal Information
Getting Help and Support
Introduction
Coding for the Intel® Processor Graphics
Platform-Level Considerations
Application-Level Optimizations
Optimizing OpenCL™ Usage with Intel® Processor Graphics
Check-list for OpenCL™ Optimizations
Performance Debugging
Using Multiple OpenCL™ Devices
Coding for the Intel® CPU OpenCL™ Device
OpenCL™ Kernel Development for Intel® CPU OpenCL™ device
Mapping Memory Objects
Using Buffers and Images Appropriately
Using Floating Point for Calculations
Using Compiler Options for Optimizations
Using Built-In Functions
Loading and Storing Data in Greatest Chunks
Applying Shared Local Memory
Using Specialization in Branching
Considering native_ and half_ Versions of Math Built-Ins
Using the Restrict Qualifier for Kernel Arguments
Avoiding Handling Edge Conditions in Kernels
Using Shared Context for Multiple OpenCL™ Devices
Sharing Resources Efficiently
Synchronization Caveats
Writing to a Shared Resource
Partitioning the Work
Keeping Kernel Sources the Same
Basic Frequency Considerations
Eliminating Device Starvation
Limitations of Shared Context with Respect to Extensions
Why Optimizing Kernel Code Is Important?
Avoid Spurious Operations in Kernel Code
Perform Initialization in a Separate Task
Use Preprocessor for Constants
Use Signed Integer Data Types
Use Row-Wise Data Accesses
Tips for Auto-Vectorization
Local Memory Usage
Avoid Extracting Vector Components
Task-Parallel Programming Model Hints
Visible to Intel only — GUID: GUID-010B1CB5-8497-492E-87D5-D1D80D37F667
__global Memory and __constant Memory
To optimize performance when accessing __global memory and __constant memory, a kernel must minimize the number of cache lines that are accessed.
However, if many work-items access the same global memory or constant memory array element, memory performance may be reduced.
For this reason, move frequently accessed global or constant data, such as look-up tables or filter coefficients, to local or private memory to improve performance.
If a kernel indexes memory, where index is a function of a work-item global id(s), the following factors have big impact on performance:
- The work-group dimensions
- The function of the work-item global id(s).
To see how the work-group dimensions can affect memory bandwidth, consider the following code segment:
__global int* myArray = ...; uint myIndex = get_global_id(0) + get_global_id(1) * width; int i = myArray [ myIndex ];
This is a typical memory access pattern for a two-dimensional array.
Consider three possible work-group dimensions, each describing a work-group of sixteen work-items:
- A “row” work-group: <16, 1, 1>
- A “square” work-group: <4, 4, 1>
- A “column” work-group: <1, 16, 1>
With the “row” work-group, get_global_id(1) is constant for all work-items in the work-group. myIndex increases monotonically across the entire work-group, which means that the read from myArray comes from a single L3 cache line (16 x sizeof(int) = 64 bytes).

With the “square” work-group, get_global_id(1) is different for every four work-items in the work-group. Within each group of four work-items, myIndex is monotonically increasing; the read from myArray comes from a different L3 cache line for each group of four work-items. Since four cache lines are accessed with the “square” work-group, this work-group sees 1/4th of the memory performance of the “row” work-group.

With the “column” work-group, get_global_id(1) is different for every work-item in the work-group; every read from myArray comes from a different cache line for every work-item in the work-group. If this is the case, 16 cache lines are accessed, and the column work-group sees 1/16th of the memory performance of the “row” work-group.
To see how the function of the work-item global ids can affect memory bandwidth, consider the following examples (assume a “row” work-group, < 16, 1, 1 >):
__global int* myArray = ...; int x; x = myArray[ get_global_id(0) ]; // case 1 x = myArray[ get_global_id(0) + 1 ]; // case 2 x = myArray[ get_global_size(0) – 1 – get_global_id(0) ]; // case 3 x = myArray[ get_global_id(0) * 4 ]; // case 4 x = myArray[ get_global_id(0) * 16 ]; // case 5 x = myArray[ get_global_id(0) * 32 ]; // case 6
In Case 1, the read is cache-aligned, and the entire read comes from one cache line. This case should achieve full memory bandwidth.
In Case 2, the read is not cache-aligned, so this read requires two cache lines, and achieves half of the memory performance of Case 1.

In Case 3, the addresses are decreasing instead of increasing, and they all come from the same cache line. This case achieves same memory performance as Case 1.
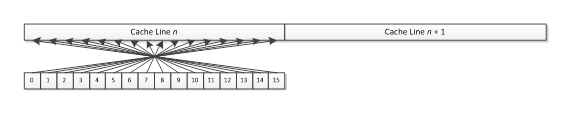
In Case 4, the addresses are stridden, so every fourth work-item accesses a new cache line. This case should achieve 1/4th of the memory performance of Case 1.
In both Case 5 and Case 6, each work-item is accessing a new cache line. Both of these cases provide similar performance, and achieve 1/16th of the memory performance of Case 1.
