Visible to Intel only — GUID: GUID-6EE96985-CFF7-4C3A-AEBE-F1DA1D0EB54D
Abs
AbsBackward
Add
AvgPool
AvgPoolBackward
BatchNormForwardTraining
BatchNormInference
BatchNormTrainingBackward
BiasAdd
BiasAddBackward
Clamp
ClampBackward
Concat
Convolution
ConvolutionBackwardData
ConvolutionBackwardWeights
ConvTranspose
ConvTransposeBackwardData
ConvTransposeBackwardWeights
Dequantize
Divide
DynamicDequantize
DynamicQuantize
Elu
EluBackward
End
Exp
GELU
GELUBackward
HardSigmoid
HardSigmoidBackward
HardSwish
HardSwishBackward
Interpolate
InterpolateBackward
LayerNorm
LayerNormBackward
LeakyReLU
Log
LogSoftmax
LogSoftmaxBackward
MatMul
Maximum
MaxPool
MaxPoolBackward
Minimum
Mish
MishBackward
Multiply
Pow
PReLU
PReLUBackward
Quantize
Reciprocal
ReduceL1
ReduceL2
ReduceMax
ReduceMean
ReduceMin
ReduceProd
ReduceSum
ReLU
ReLUBackward
Reorder
Round
Select
Sigmoid
SigmoidBackward
SoftMax
SoftMaxBackward
SoftPlus
SoftPlusBackward
Sqrt
SqrtBackward
Square
SquaredDifference
StaticReshape
StaticTranspose
Subtract
Tanh
TanhBackward
TypeCast
Wildcard
enum dnnl_alg_kind_t
enum dnnl_normalization_flags_t
enum dnnl_primitive_kind_t
enum dnnl_prop_kind_t
enum dnnl_query_t
enum dnnl::normalization_flags
enum dnnl::query
struct dnnl_exec_arg_t
struct dnnl_primitive
struct dnnl_primitive_desc
struct dnnl::primitive
struct dnnl::primitive_desc
struct dnnl::primitive_desc_base
enum dnnl_rnn_direction_t
enum dnnl_rnn_flags_t
enum dnnl::rnn_direction
enum dnnl::rnn_flags
struct dnnl::augru_backward
struct dnnl::augru_forward
struct dnnl::gru_backward
struct dnnl::gru_forward
struct dnnl::lbr_augru_backward
struct dnnl::lbr_augru_forward
struct dnnl::lbr_gru_backward
struct dnnl::lbr_gru_forward
struct dnnl::lstm_backward
struct dnnl::lstm_forward
struct dnnl::rnn_primitive_desc_base
struct dnnl::vanilla_rnn_backward
struct dnnl::vanilla_rnn_forward
Visible to Intel only — GUID: GUID-6EE96985-CFF7-4C3A-AEBE-F1DA1D0EB54D
Naming Conventions
oneDNN documentation relies on a set of standard naming conventions for variables. This section describes these conventions.
Variable (Tensor) Names
Neural network models consist of operations of the following form:
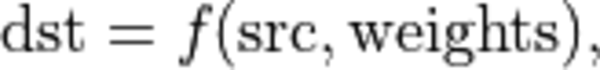
where 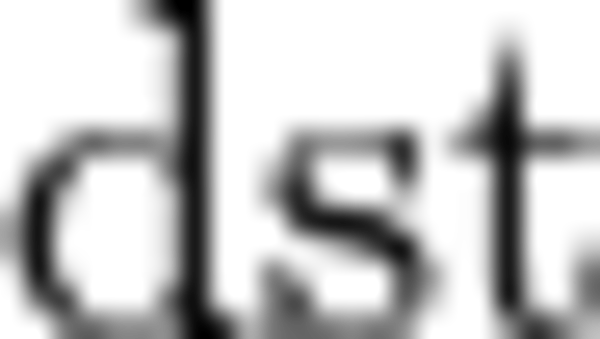 and
and 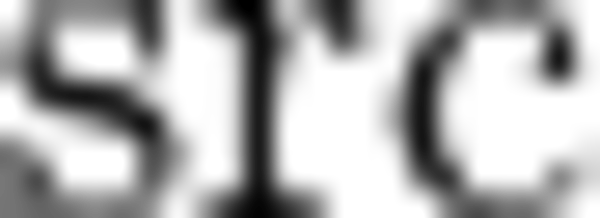 are activation tensors, and
are activation tensors, and  are learnable tensors.
are learnable tensors.
The backward propagation consists then in computing the gradients with respect to the and respectively:
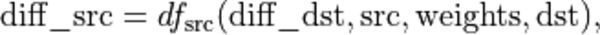
and
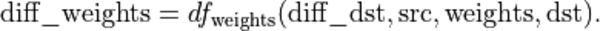
While oneDNN uses src, dst, and weights as generic names for the activations and learnable tensors, for a specific operation there might be commonly used and widely known specific names for these tensors. For instance, the convolution operation has a learnable tensor called bias. For usability reasons, oneDNN primitives use such names in initialization or other functions to simplify the coding.
To summarize, oneDNN uses the following commonly used notations for tensors:
Name |
Meaning |
|---|---|
src |
Source tensor |
dst |
Destination tensor |
weights |
Weights tensor |
bias |
Bias tensor (used in Convolution , Inner Product and other primitives) |
scale_shift |
Scale and shift tensors (used in Batch Normalization , Layer Normalization and Group Normalization ) |
workspace |
Workspace tensor that carries additional information from the forward propagation to the backward propagation |
scratchpad |
Temporary tensor that is required to store the intermediate results |
diff_src |
Gradient tensor with respect to the source |
diff_dst |
Gradient tensor with respect to the destination |
diff_weights |
Gradient tensor with respect to the weights |
diff_bias |
Gradient tensor with respect to the bias |
diff_scale_shift |
Gradient tensor with respect to the scale and shift |
*_layer |
RNN layer data or weights tensors |
*_iter |
RNN recurrent data or weights tensors |
Formulas and Verbose Output
oneDNN uses the following notations in the documentation formulas and verbose output. Here, lower-case letters are used to denote indices in a particular spatial dimension, the sizes of which are denoted by corresponding upper-case letters.
Name |
Semantics |
|---|---|
n (or mb ) |
batch |
g |
groups |
oc , od , oh , ow |
output channels, depth, height, and width |
ic , id , ih , iw |
input channels, depth, height, and width |
kd , kh , kw |
kernel (filter) depth, height, and width |
sd , sh , sw |
stride by depth, height, and width |
dd , dh , dw |
dilation by depth, height, and width |
pd , ph , pw |
padding by depth, height, and width |
RNN-Specific Notation
The following notations are used when describing RNN primitives.
Name |
Semantics |
|---|---|
|
matrix multiply operator |
|
element-wise multiplication operator |
W |
input weights |
U |
recurrent weights |
|
transposition |
B |
bias |
h |
hidden state |
a |
intermediate value |
x |
input |
|
timestamp |
|
layer index |
activation |
tanh, relu, logistic |
c |
cell state |
|
candidate state |
i |
input gate |
f |
forget gate |
o |
output gate |
u |
update gate |
r |
reset gate |

Memory Formats Tags
When describing tensor memory formats, which is the oneDNN term for the way that the data is laid out in memory, documentation uses letters of the English alphabet to describe an order of dimensions and their semantics.
The canonical sequence of letters is a, b, c, …, z. In this notation, the ab tag denotes a two-dimensional tensor with a denoting the outermost dimension and b denoting the innermost dimension, where the latter is dense in memory. Further, the ba tag denotes a two-dimensional tensor but with last two dimensions transposed: instead of the naturally dense b dimension, now a is the dense dimension. If we suppose that the two-dimensional tensor is a matrix and the a and b dimensions represent the number of columns and rows, then ab would denote the row-major (C) format and ba would denote the column-major (Fortran) format.
Todo Picture here
Upper-case letters are used to indicate that the data is laid out in blocks for a particular dimension. In such cases, the format name contains both upper- and lower-case letters for that dimension with a lower-case letter preceded by the block size. For example, the Ab16a tag denotes a format similar to row-major but with columns split into contiguous blocks of 16 elements each. Moreover, the implicit assumption is that if the number of columns is not divisible by 16, the last block in the in-memory representation will contain padding.
Todo Picture here
Since there are many widely used names for specific deep learning domains like convolutional neural networks (CNNs), oneDNN also supports memory format tags in which dimensions have specifically assigned meaning like ‘image width’, ‘image height’, etc. The following table summarizes notations used in such memory format tags.
Letter |
Dimension |
|---|---|
n |
batch |
g |
groups |
c |
channels |
o |
output channels |
i |
input channels |
h |
height |
w |
width |
d |
depth |
t |
timestamp |
l |
layer |
d |
direction |
g |
gate |
s |
state |
The canonical sequence of dimensions for four-dimensional data tensors in CNNs is (batch, channels, spatial dimensions). Spatial dimensions are ordered for tensors with three spatial dimensions as (depth, height, width), for tensors with two spatial dimensions as (height, width), and as just (width) for tensors with only one spatial dimension.
In this notation, nchw is a memory format tag for a four-dimensional tensor, with the first dimension corresponding to batch, the second to channel, and the remaining two to spatial dimensions. Due to the canonical order of dimensions for CNNs, this tag is the same as abcd. As another example, nhwc is the same as acdb.