Visible to Intel only — GUID: GUID-7CC9E271-9BC7-485D-ACAA-4A17FA4991A3
Abs
AbsBackward
Add
AvgPool
AvgPoolBackward
BatchNormForwardTraining
BatchNormInference
BatchNormTrainingBackward
BiasAdd
BiasAddBackward
Clamp
ClampBackward
Concat
Convolution
ConvolutionBackwardData
ConvolutionBackwardWeights
ConvTranspose
ConvTransposeBackwardData
ConvTransposeBackwardWeights
Dequantize
Divide
DynamicDequantize
DynamicQuantize
Elu
EluBackward
End
Exp
GELU
GELUBackward
HardSigmoid
HardSigmoidBackward
HardSwish
HardSwishBackward
Interpolate
InterpolateBackward
LayerNorm
LayerNormBackward
LeakyReLU
Log
LogSoftmax
LogSoftmaxBackward
MatMul
Maximum
MaxPool
MaxPoolBackward
Minimum
Mish
MishBackward
Multiply
Pow
PReLU
PReLUBackward
Quantize
Reciprocal
ReduceL1
ReduceL2
ReduceMax
ReduceMean
ReduceMin
ReduceProd
ReduceSum
ReLU
ReLUBackward
Reorder
Round
Select
Sigmoid
SigmoidBackward
SoftMax
SoftMaxBackward
SoftPlus
SoftPlusBackward
Sqrt
SqrtBackward
Square
SquaredDifference
StaticReshape
StaticTranspose
Subtract
Tanh
TanhBackward
TypeCast
Wildcard
enum dnnl_alg_kind_t
enum dnnl_normalization_flags_t
enum dnnl_primitive_kind_t
enum dnnl_prop_kind_t
enum dnnl_query_t
enum dnnl::normalization_flags
enum dnnl::query
struct dnnl_exec_arg_t
struct dnnl_primitive
struct dnnl_primitive_desc
struct dnnl::primitive
struct dnnl::primitive_desc
struct dnnl::primitive_desc_base
enum dnnl_rnn_direction_t
enum dnnl_rnn_flags_t
enum dnnl::rnn_direction
enum dnnl::rnn_flags
struct dnnl::augru_backward
struct dnnl::augru_forward
struct dnnl::gru_backward
struct dnnl::gru_forward
struct dnnl::lbr_augru_backward
struct dnnl::lbr_augru_forward
struct dnnl::lbr_gru_backward
struct dnnl::lbr_gru_forward
struct dnnl::lstm_backward
struct dnnl::lstm_forward
struct dnnl::rnn_primitive_desc_base
struct dnnl::vanilla_rnn_backward
struct dnnl::vanilla_rnn_forward
Visible to Intel only — GUID: GUID-7CC9E271-9BC7-485D-ACAA-4A17FA4991A3
MatMul Tutorial: Quantization
C++ API example demonstrating how one can perform reduced precision matrix-matrix multiplication using MatMul and the accuracy of the result compared to the floating point computations.
Concepts:
Static and dynamic quantization
Asymmetric quantization
Zero points: dnnl::primitive_attr::set_zero_points_mask()
The example is focused around the following computation:

First, we produce the reference result, having the original matrices  and be in dnnl::memory::data_type::f32 data type.
and be in dnnl::memory::data_type::f32 data type.
For reduced precision computations, the matrices and will use dnnl::memory::data_type::u8 data type and would have the appropriate zero points. For the matrix , we will use the dnnl::memory::data_type::s8 data type, assuming that the data is centered around zero (hence, the zero point would be simply 0).
The quantization formula is:
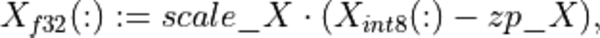
where:
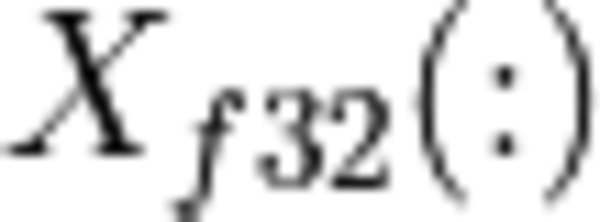 original matrix;
original matrix;- quantized matrix, where int8 is either u8 (uint8_t) for the matrices and , or s8 (int8_t) for the matrix ;
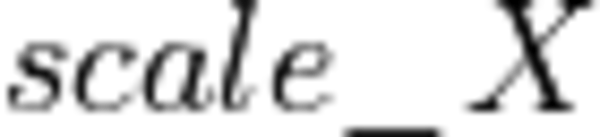 f32 scaling factor. For simplicity we will use a single scale factor for each matrix, though for better accuracy it might be a good idea to use per-N-dimension scaling factor for the matrix B.
f32 scaling factor. For simplicity we will use a single scale factor for each matrix, though for better accuracy it might be a good idea to use per-N-dimension scaling factor for the matrix B.- integer quantization parameter “zero point” (essentially, the representation of the real 0 in the quantized data type).
For a given matrix 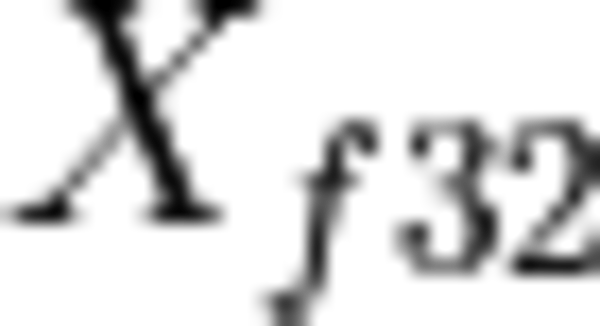 and int8 data type (u8 or s8), the process of finding the proper and is a research problem and can be different depending on the domain. For example purposes, we will use the simplest approach by mapping the maximum (minimum) elements to the maximum (minimum) number in the corresponding integer data type, using the following formulas:
and int8 data type (u8 or s8), the process of finding the proper and is a research problem and can be different depending on the domain. For example purposes, we will use the simplest approach by mapping the maximum (minimum) elements to the maximum (minimum) number in the corresponding integer data type, using the following formulas:
Since:
Hence:
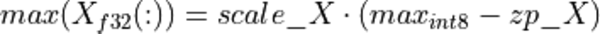
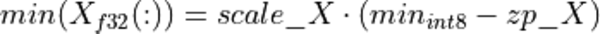
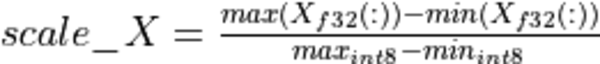
It is worth noting that quantization parameters are not always computed at actual run-time. For example, if we perform MatMul operation for similar matrices (in a sense that data distribution is similar between the runs) we can simply guess the proper quantization parameters by collecting some statistics during the early runs. This approach is called static quantization. It gives good performance (since no cycles are spent on computing those parameters) and is typically used in reduced precision CNN inference. However, the static quantization has an obvious disadvantage the guessed parameters might not work well for some particular matrices. For example, that would most likely be the case if we could not guarantee the similarity of the input matrices. In this case, the dynamic quantization would be used, i.e. the parameters (re-)computed at runtime. This gives slightly worse performance, but that might be inevitable due to accuracy considerations.
Only dynamic approaches is demonstrated in this example.
Other details:
For simplicity all matrices will be stored in Row-Major format.
The shapes of the matrices are assumed to be known at creation time. However, for dynamic quantization we would consider q10n parameters (
and ) to be known at run-time only. On the contrary, for the static quantization these parameters are known at creation time as well.
/*******************************************************************************
* Copyright 2019-2022 Intel Corporation
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*******************************************************************************/
#include <cassert>
#include <cctype>
#include <cmath>
#include <cstdio>
#include <iostream>
#include <random>
#include <stdexcept>
#include <vector>
#include <type_traits>
#include "oneapi/dnnl/dnnl.hpp"
#include "example_utils.hpp"
using namespace dnnl;
namespace {
void init_vector(std::vector<float> &v, float min_value, float max_value) {
std::mt19937 gen;
std::uniform_real_distribution<float> u(min_value, max_value);
for (auto &e : v)
e = u(gen);
}
template <typename T>
void find_min_max(const std::vector<T> &v, float &min_value, float &max_value) {
min_value = max_value = v[0];
for (auto &e : v) {
min_value = std::min<float>(min_value, e);
max_value = std::max<float>(max_value, e);
}
}
template <typename T>
void compute_q10n_params(const char *message, const std::vector<float> &v,
float &scale, int32_t &zp) {
// Find property of T integer type
// Simple trick to improve accuracy: shrink the range a little bit
float max_int = (float)std::numeric_limits<T>::max() - 1;
float min_int = (float)std::numeric_limits<T>::lowest() + 1;
#ifndef OMIT_WORKAROUND_FOR_SKX
// Read more in CPU / Section 1 here:
// https://oneapi-src.github.io/oneDNN/dev_guide_int8_computations.html
if (std::is_same<T, uint8_t>::value) max_int /= 2;
#endif
// Find min and max value in array
float min_val = v[0], max_val = v[0];
find_min_max(v, min_val, max_val);
// Compute appropriate scale
scale = (max_val - min_val) / (max_int - min_int);
// Compute appropriate offset
if (std::is_same<T, int8_t>::value)
zp = 0;
else
zp = (int32_t)(max_int - max_val / scale);
printf("\tComputing q10n params for %s\n"
"\t\tData type: %s\n"
"\t\tScale:%.3g (inverse scale:%.3g)\n"
"\t\tZero point:%d\n\n",
message, std::is_same<T, int8_t>::value ? "int8_t" : "uint8_t",
scale, 1 / scale, zp);
}
int compare_vectors(const std::vector<float> &v1,
const std::vector<uint8_t> &v2, float scale_v2, int32_t zp_v2,
float threshold) {
double v1_l2 = 0, diff_l2 = 0;
for (size_t n = 0; n < v1.size(); ++n) {
float v2_n = scale_v2 * (v2[n] - zp_v2); // deq10n v2
float diff = v1[n] - v2_n;
v1_l2 += v1[n] * v1[n];
diff_l2 += diff * diff;
}
v1_l2 = std::sqrt(v1_l2);
diff_l2 = std::sqrt(diff_l2);
bool ok = diff_l2 <= threshold * v1_l2;
printf("\tComparison (using l2-norms)\n"
"\t\tReference matrix:%g\n\t\tError:%g\n\t\tRelative error:%g\n"
"\nAccuracy check: %s\n\n",
v1_l2, diff_l2, diff_l2 / v1_l2, ok ? "OK" : "FAILED");
return ok ? 0 : 1;
}
} // namespace
engine eng(engine::kind::cpu, 0); // We create a global engine for simplicity
// Quantize float data into X_int_m oneDNN memory using the q10n parameters
//
// Inputs:
// - X_f32 -- source f32 matrix
// - scale_X, zp_X -- quantization parameters
// - q10n_scheme -- dynamic or static, to mimic real-world applications wrt to
// how the q10n parameters are passed to reorders
// Outputs:
// - X_int_m -- prepared oneDNN memory that would hold quantized values
void quantize(const std::vector<float> &X_f32, float scale_X, int32_t zp_X,
memory &X_int_m) {
using dt = memory::data_type;
stream s(eng);
memory::desc x_int_md = X_int_m.get_desc();
const auto &dims = x_int_md.get_dims();
memory::desc x_f32_md({dims[0], dims[1]}, dt::f32, {dims[1], 1});
memory X_f32_m(x_f32_md, eng, (void *)X_f32.data());
primitive_attr q10n_attr;
q10n_attr.set_scales_mask(DNNL_ARG_DST, /* mask */ 0);
q10n_attr.set_zero_points_mask(DNNL_ARG_DST, /* mask */ 0);
reorder::primitive_desc q10n_pd(eng, x_f32_md, eng, x_int_md, q10n_attr);
memory dst_scale_X_m({{1}, dt::f32, {1}}, eng, &scale_X);
memory zp_X_m({{1}, dt::s32, {1}}, eng, &zp_X);
reorder(q10n_pd).execute(s,
{{DNNL_ARG_SRC, X_f32_m}, {DNNL_ARG_DST, X_int_m},
{DNNL_ARG_ATTR_SCALES | DNNL_ARG_DST, dst_scale_X_m},
{DNNL_ARG_ATTR_ZERO_POINTS | DNNL_ARG_DST, zp_X_m}});
s.wait();
}
// Floating point MatMul
// Inputs:
// - Shape: M, N, K
// - Matrices A and B
// Outputs:
// - Matrix C
void f32_matmul_compute(int64_t M, int64_t N, int64_t K,
const std::vector<float> &A_f32, const std::vector<float> &B_f32,
std::vector<float> &C_f32) {
// Initialize memory descriptors that describes matrices in Row-Major format
memory::desc a_md({M, K}, memory::data_type::f32, {K, 1});
memory::desc b_md({K, N}, memory::data_type::f32, {N, 1});
memory::desc c_md({M, N}, memory::data_type::f32, {N, 1});
// Wrap raw pointers into oneDNN memory objects
memory A_f32_m(a_md, eng, (void *)A_f32.data());
memory B_f32_m(b_md, eng, (void *)B_f32.data());
memory C_f32_m(c_md, eng, (void *)C_f32.data());
// Create a MatMul primitive
matmul::primitive_desc matmul_pd(eng, a_md, b_md, c_md);
matmul matmul_p(matmul_pd);
stream s(eng);
matmul_p.execute(s,
{{DNNL_ARG_SRC, A_f32_m}, {DNNL_ARG_WEIGHTS, B_f32_m},
{DNNL_ARG_DST, C_f32_m}});
s.wait();
}
// Reduced precision MatMul with **dynamic** quantization
// Inputs:
// - Shape: M, N, K
// - Matrices A and B in float (would be quantized inside the function)
// Outputs:
// - Matrix C in uint8_t
// - Quantization parameters: scale_C and zp_C
void dynamic_q10n_matmul(int64_t M, int64_t N, int64_t K,
const std::vector<float> &A_f32, const std::vector<float> &B_f32,
std::vector<uint8_t> &C_u8, float &scale_C, int32_t &zp_C) {
stream s(eng);
float scale_A, scale_B;
int32_t zp_A, zp_B;
// We compute q10n parameters here, but in the real world applications for
// inputs these parameters are transferred from the previous layers
compute_q10n_params<uint8_t>("A", A_f32, scale_A, zp_A);
compute_q10n_params<int8_t>("B", B_f32, scale_B, zp_B);
assert(zp_B == 0 && "for int8 q10n we assume zero point = 0");
// Quantize matrix A_u8 using reorder primitive
std::vector<uint8_t> A_u8(M * K, 0);
memory::desc a_u8_md({M, K}, memory::data_type::u8, {K, 1});
memory A_u8_m(a_u8_md, eng, (void *)A_u8.data());
quantize(A_f32, scale_A, zp_A, A_u8_m);
// Quantize matrix B_s8 using reorder primitive
std::vector<uint8_t> B_s8(K * N, 0);
memory::desc b_s8_md({K, N}, memory::data_type::s8, {N, 1});
memory B_s8_m(b_s8_md, eng, (void *)B_s8.data());
quantize(B_f32, scale_B, 0, B_s8_m);
// Compute C_f32. We cannot directly compute C_u8 since we don't know the
// appropriate quantization parameters.
//
// Note: typically the computed data type in this case is int32_t and not
// float. But for brevity we are going to embed the scale_A and
// scale_B directly in this quantized MatMul, and hence will get the
// intermediate computation in floating point anyways, so there is
// no sense to convert the result to int32_t.
// In theory, we could postpone using the scale_A and scale_B, compute
// the exact C_s32 := (A_u8 - zp_A) * B_s8, and then find the
// appropriate quantization parameters for matrix C.
// Let it be an exercise :)
std::vector<float> C_f32(M * N, 0);
memory::desc c_f32_md({M, N}, memory::data_type::f32, {N, 1});
memory C_f32_m(c_f32_md, eng, (void *)C_f32.data());
// Create and compute a reduced precision MatMul primitive
{
primitive_attr matmul_attr;
matmul_attr.set_scales_mask(DNNL_ARG_SRC, /* mask */ 0);
matmul_attr.set_scales_mask(DNNL_ARG_WEIGHTS, /* mask */ 0);
matmul_attr.set_zero_points_mask(DNNL_ARG_SRC, /* mask */ 0);
matmul::primitive_desc matmul_pd(
eng, a_u8_md, b_s8_md, c_f32_md, matmul_attr);
matmul matmul_p(matmul_pd);
memory scales_A_m({{1}, memory::data_type::f32, {1}}, eng, &scale_A);
memory scales_B_m({{1}, memory::data_type::f32, {1}}, eng, &scale_B);
memory zp_A_m({{1}, memory::data_type::s32, {1}}, eng, &zp_A);
matmul_p.execute(s,
{{DNNL_ARG_SRC, A_u8_m}, {DNNL_ARG_WEIGHTS, B_s8_m},
{DNNL_ARG_DST, C_f32_m},
{DNNL_ARG_ATTR_SCALES | DNNL_ARG_SRC, scales_A_m},
{DNNL_ARG_ATTR_SCALES | DNNL_ARG_WEIGHTS, scales_B_m},
{DNNL_ARG_ATTR_ZERO_POINTS | DNNL_ARG_SRC, zp_A_m}});
}
// Find quantization parameters for matrix C
compute_q10n_params<uint8_t>("C", C_f32, scale_C, zp_C);
// Finally quantize the matrix C
memory::desc c_u8_md({M, N}, memory::data_type::u8, {N, 1});
memory C_u8_m(c_u8_md, eng, (void *)C_u8.data());
quantize(C_f32, scale_C, zp_C, C_u8_m);
}
void compare_f32_and_quantized_matmuls() {
// MatMul parameters
const int64_t M = 10, N = 20, K = 30;
// Data distribution for matrices A and B
const float param_A_min_val = -2.f;
const float param_A_max_val = 1.4f;
const float param_B_min_val = -1.f;
const float param_B_max_val = -param_B_min_val; // B is centered around 0
// Thresholds
//
const float threshold_dynamic_q10n = 3 * 1e-2f;
// Prepare matrices
std::vector<float> A_f32(M * K), B_f32(K * N), C_f32(M * N, 0);
init_vector(A_f32, param_A_min_val, param_A_max_val);
init_vector(B_f32, param_B_min_val, param_B_max_val);
// Compute _true_ f32 result
f32_matmul_compute(M, N, K, A_f32, B_f32, C_f32);
std::vector<uint8_t> C_u8_dynamic_q10n(M * N, 0);
float scale_C_dynamic_q10n; // Q10n parameters we don't know yet
int zp_C_dynamic_q10n;
dynamic_q10n_matmul(M, N, K, A_f32, B_f32, C_u8_dynamic_q10n,
scale_C_dynamic_q10n, zp_C_dynamic_q10n);
// Compare _true_ f32 result with dynamic q10n
int rc = compare_vectors(C_f32, C_u8_dynamic_q10n, scale_C_dynamic_q10n,
zp_C_dynamic_q10n, threshold_dynamic_q10n);
if (rc) throw std::logic_error("Dynamic quantization accuracy failed.");
}
int main(int argc, char **argv) {
return handle_example_errors(
{engine::kind::cpu}, compare_f32_and_quantized_matmuls);
}