Intel® oneAPI Deep Neural Network Developer Guide and Reference
A newer version of this document is available. Customers should click here to go to the newest version.
Visible to Intel only — GUID: GUID-8EA045CB-C110-4F15-BA1D-CC28A93412D4
Visible to Intel only — GUID: GUID-8EA045CB-C110-4F15-BA1D-CC28A93412D4
MatMul Tutorial: INT8 Inference
C++ API example demonstrating how one can use MatMul fused with ReLU in INT8 inference.
Concepts:
Asymmetric quantization
Zero points: dnnl::primitive_attr::set_zero_points_mask()
Create primitive once, use multiple times
Run-time tensor shapes: DNNL_RUNTIME_DIM_VAL
Weights pre-packing: use dnnl::memory::format_tag::any
Assumptions:
The shape of the weights (matrix
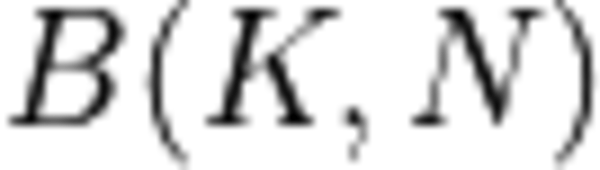 ) is known in advance, the data type is int8_t and centered around 0 (i.e. the zero point is 0).
) is known in advance, the data type is int8_t and centered around 0 (i.e. the zero point is 0).The shapes of the source matrix
 and destination matrix
and destination matrix  are partially unknown. Both matrices use uint8_t data type and might have arbitrary zero points (specified at execution time only).
are partially unknown. Both matrices use uint8_t data type and might have arbitrary zero points (specified at execution time only).Scaling (re-quantization) factor specified at run-time only.
Since the shape of weights is known in advance, the MatMul weights can be created with format tag dnnl::memory::format_tag::any to enable the library to choose the most appropriate layout for best performance.
/******************************************************************************* * Copyright 2019-2022 Intel Corporation * * Licensed under the Apache License, Version 2.0 (the "License"); * you may not use this file except in compliance with the License. * You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. *******************************************************************************/ #include <cassert> #include <cctype> #include <cmath> #include <cstdio> #include <iostream> #include <random> #include <stdexcept> #include <vector> #include "oneapi/dnnl/dnnl.hpp" #include "example_utils.hpp" using namespace dnnl; namespace { void init_vector(std::vector<float> &v) { std::mt19937 gen; std::uniform_real_distribution<float> u(0, 1); for (auto &e : v) e = u(gen); } void init_vector(std::vector<uint8_t> &v) { std::mt19937 gen; std::uniform_int_distribution<unsigned int> u(0, 255); for (auto &e : v) e = static_cast<uint8_t>(u(gen)); } } // namespace int number_of_runs = 1; // Create a MatMul primitive descriptor for the following op: // C_u8 = ReLU(sc_A * sc_B[:] * (A_u8 - zp_A) * B_s8) / sc_C + zp_C // // Here: // - Matrices A and C are known to be non-transposed but their M dimension is // not known. They can be activation matrices in an MLP topology and the M // dimension can be the mini-batch dimension. // - zp_A and zp_C are zero points for matrices A and C which are stored as // uint8_t. These are run-time parameters that are not known at the primitive // creation time. // - The B matrix is stored as int8_t, its zero point is 0, and all its // dimensions are known. This matrix can be a matrix of weights in an MLP // topology. // - The scaling values are not known at the primitive creation time. matmul::primitive_desc matmul_pd_create( int64_t K, int64_t N, const engine &eng) { const int64_t M = DNNL_RUNTIME_DIM_VAL; memory::desc a_md({M, K}, memory::data_type::u8, {K, 1}); // M x K layout memory::desc b_md({K, N}, memory::data_type::s8, memory::format_tag::any); memory::desc c_md({M, N}, memory::data_type::u8, {N, 1}); // M x N layout // Create attributes and indicate that the alpha and zero points are // runtime parameters primitive_attr attr; attr.set_scales_mask(DNNL_ARG_SRC, /* mask */ 0); attr.set_scales_mask(DNNL_ARG_WEIGHTS, /* mask */ 1 << 1); attr.set_scales_mask(DNNL_ARG_DST, /* mask */ 0); attr.set_zero_points_mask(DNNL_ARG_SRC, /* mask */ 0); attr.set_zero_points_mask(DNNL_ARG_DST, /* mask */ 0); post_ops po; po.append_eltwise(algorithm::eltwise_relu, 0.f, 0.f); attr.set_post_ops(po); // Create a MatMul primitive descriptor return matmul::primitive_desc(eng, a_md, b_md, c_md, attr); } void prepare_input(memory &A_u8_mem, memory &sc_A_mem, memory &sc_B_mem, memory &sc_C_mem, memory &zp_A_mem, memory &zp_C_mem) { int64_t M = A_u8_mem.get_desc().get_dims()[0]; int64_t N = sc_B_mem.get_desc().get_dims()[0]; int64_t K = A_u8_mem.get_desc().get_dims()[1]; std::vector<uint8_t> A_u8(M * K); init_vector(A_u8); std::vector<float> sc_B(N); init_vector(sc_B); float sc_A = 0.5f; float sc_C = 0.25f; int32_t zp_A = 128, zp_C = 40; write_to_dnnl_memory(A_u8.data(), A_u8_mem); write_to_dnnl_memory(&zp_A, zp_A_mem); write_to_dnnl_memory(&zp_C, zp_C_mem); write_to_dnnl_memory(&sc_A, sc_A_mem); write_to_dnnl_memory(sc_B.data(), sc_B_mem); write_to_dnnl_memory(&sc_C, sc_C_mem); } void sanity_check(memory &C_u8_mem, memory &zp_C_mem) { int64_t M = C_u8_mem.get_desc().get_dims()[0]; int64_t N = C_u8_mem.get_desc().get_dims()[1]; int32_t zp_C = 0; std::vector<uint8_t> C_u8(M * N); read_from_dnnl_memory(C_u8.data(), C_u8_mem); read_from_dnnl_memory(&zp_C, zp_C_mem); // simple check: C_u8 >= zp_C for (int64_t i = 0; i < M * N; ++i) if (C_u8[i] < zp_C) throw std::logic_error( "Smoke check failed." "\n\tQuantized value is smaller than the zero point," "\n\twhich should not happen since ReLU was applied."); } void infer(const matmul &matmul_p, int64_t M, int64_t N, int64_t K, const memory &B_s8_mem, const engine &eng) { // inputs of the current layer / operation memory A_u8_mem({{M, K}, memory::data_type::u8, {K, 1}}, eng); memory zp_A_mem({{1}, memory::data_type::s32, {1}}, eng); memory zp_C_mem({{1}, memory::data_type::s32, {1}}, eng); memory sc_A_mem({{1}, memory::data_type::f32, {1}}, eng); memory sc_B_mem({{N}, memory::data_type::f32, {1}}, eng); memory sc_C_mem({{1}, memory::data_type::f32, {1}}, eng); // the function below fills dnnl::memory with some values // these memories, typically, come from the previous layers / operations // with meaningful data inside prepare_input(A_u8_mem, sc_A_mem, sc_B_mem, sc_C_mem, zp_A_mem, zp_C_mem); // output - no initialization required memory C_u8_mem({{M, N}, memory::data_type::u8, {N, 1}}, eng); stream s(eng); for (int run = 0; run < number_of_runs; ++run) matmul_p.execute(s, {{DNNL_ARG_SRC, A_u8_mem}, {DNNL_ARG_WEIGHTS, B_s8_mem}, {DNNL_ARG_DST, C_u8_mem}, {DNNL_ARG_ATTR_SCALES | DNNL_ARG_SRC, sc_A_mem}, {DNNL_ARG_ATTR_SCALES | DNNL_ARG_WEIGHTS, sc_B_mem}, {DNNL_ARG_ATTR_SCALES | DNNL_ARG_DST, sc_C_mem}, {DNNL_ARG_ATTR_ZERO_POINTS | DNNL_ARG_SRC, zp_A_mem}, {DNNL_ARG_ATTR_ZERO_POINTS | DNNL_ARG_DST, zp_C_mem}}); s.wait(); // a sanity check for the correctness of the output sanity_check(C_u8_mem, zp_C_mem); } void inference_int8_matmul(engine::kind engine_kind) { engine eng(engine_kind, 0); const int64_t K = 96; const int64_t N = 1000; auto matmul_pd = matmul_pd_create(K, N, eng); // Original weights stored as float in a known format std::vector<float> B_f32(K * N); init_vector(B_f32); // Pre-packed weights stored as int8_t memory B_s8_mem(matmul_pd.weights_desc(), eng); { stream s(eng); memory B_f32_mem( {{K, N}, memory::data_type::f32, memory::format_tag::ab}, eng); write_to_dnnl_memory(B_f32.data(), B_f32_mem); reorder(B_f32_mem, B_s8_mem).execute(s, B_f32_mem, B_s8_mem); s.wait(); } matmul matmul_p(matmul_pd); for (int64_t M : {1, 100}) infer(matmul_p, M, N, K, B_s8_mem, eng); } int main(int argc, char **argv) { engine::kind engine_kind = parse_engine_kind(argc, argv); return handle_example_errors(inference_int8_matmul, engine_kind); }