A newer version of this document is available. Customers should click here to go to the newest version.
GPU Offload Flow
Offloading a program to a GPU defaults to the level zero runtime. There is also an option to switch to the OpenCL™ runtime. In SYCL* and OpenMP* offload, each work item is mapped to a SIMD lane. A subgroup maps to SIMD width formed from work items that execute in parallel and subgroups are mapped to GPU EU thread. Work-groups, which include work-items that can synchronize and share local data, are assigned for execution on compute units (that is, streaming multiprocessors or Xe core, also known as sub-slices). Finally, the entire global NDRange of work-items maps to the entire GPU.
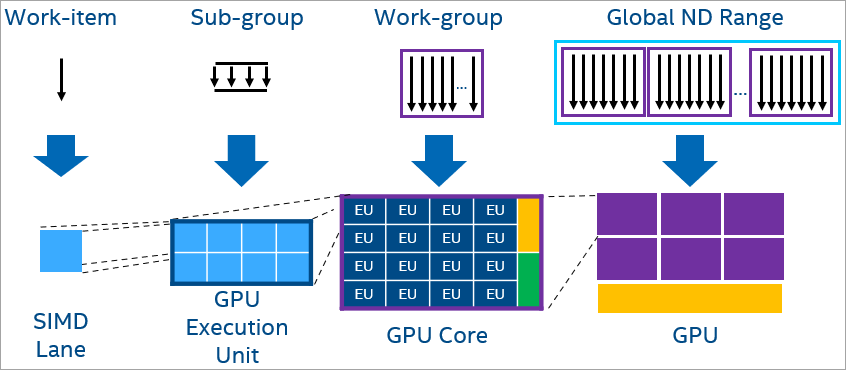
To learn more about GPU execution, see Compare Benefits of CPUs, GPUs, and FPGAs for Different oneAPI Compute Workloads.
Set Up for GPU Offload
Make sure you have followed all steps in the oneAPI Development Environment Setup section, including running the setvars script.
Configure your GPU system by installing drivers and add the user to the video group. See the Get Started Guide for instructions:
Check if you have a supported GPU and the necessary drivers installed using the sycl-ls command. In the following example, if you had the OpenCL and Level Zero driver installed you would see two entries for each runtime associated with the GPU:
CPU : OpenCL 2.1 (Build 0)[ 2020.11.12.0.14_160000 ] GPU : OpenCL 3.0 NEO [ 21.33.20678 ] GPU : 1.1[ 1.2.20939 ]
Use one of the following code samples to verify that your code is running on the GPU. The code sample adds scalar to large vectors of integers and verifies the results.
SYCL
To run on a GPU, SYCL provides built-in device selectors using device_selector as a base class. gpu_selector selects a GPU device. You can also create your own custom selector. For more information, see the Choosing Devices section in Data Parallel C++: Mastering DPC++ for Programming of Heterogeneous Systems using C++ and SYCL (book).
SYCL code sample:
#include <CL/sycl.hpp>
#include <array>
#include <iostream>
using namespace sycl;
using namespace std;
constexpr size_t array_size = 10000;
int main(){
constexpr int value = 100000;
try{
//
// The default device selector will select the most performant device.
default_selector d_selector;
queue q(d_selector);
//Allocating shared memory using USM.
int *sequential = malloc_shared<int>(array_size, q);
int *parallel = malloc_shared<int>(array_size, q);
//Sequential iota
for (size_t i = 0; i < array_size; i++) sequential[i] = value + i;
//Parallel iota in SYCL
auto e = q.parallel_for(range{array_size}, [=](auto i) { parallel[i] = value + i; });
e.wait();
// Verify two results are equal.
for (size_t i = 0; i < array_size; i++) {
if (parallel[i] != sequential[i]) {
cout << "Failed on device.\n";
return -1;
}
}
free(sequential, q);
free(parallel, q);
}catch (std::exception const &e) {
cout << "An exception is caught while computing on device.\n";
terminate();
}
cout << "Successfully completed on device.\n";
return 0;
}
To compile the code sample, use:
icpx -fsycl simple-iota-dp.cpp -o simple-iota
Results after compilation:
./simple-iota Running on device: Intel® UHD Graphics 630 [0x3e92] Successfully completed on device.
OpenMP*
OpenMP code sample:
#include <stdlib.h>
#include <omp.h>
#include <iostream>
constexpr size_t array_size = 10000;
#pragma omp requires unified_shared_memory
int main(){
constexpr int value = 100000;
// Returns the default target device.
int deviceId = (omp_get_num_devices() > 0) ? omp_get_default_device() : omp_get_initial_device();
int *sequential = (int *)omp_target_alloc_host(array_size, deviceId);
int *parallel = (int *)omp_target_alloc(array_size, deviceId);
for (size_t i = 0; i < array_size; i++)
sequential[i] = value + i;
#pragma omp target parallel for
for (size_t i = 0; i < array_size; i++)
parallel[i] = value + i;
for (size_t i = 0; i < array_size; i++) {
if (parallel[i] != sequential[i]) {
std::cout << "Failed on device.\n";
return -1;
}
}
omp_target_free(sequential, deviceId);
omp_target_free(parallel, deviceId);
std::cout << "Successfully completed on device.\n";
return 0;
}
To compile the code sample, use:
icpx -fsyclsimple-iota-omp.cpp -fiopenmp -fopenmp-targets=spir64 -o simple-iota
Results after compilation:
./simple-iota Successfully completed on device.
Offload Code to GPU
To decide which GPU hardware and what parts of the code to offload, refer to the GPU optimization workflow guide.
To find opportunities to offload your code to GPU, use the Intel Advisor for Offload Modeling.
Debug GPU Code
The following list has some basic debugging tips for offloaded code.
Check CPU or host/target or switch runtime to OpenCL to verify the correctness of code.
You could use printf to debug your application. Both SYCL and OpenMP offload support printf in kernel code.
Use environment variables to control verbose log information.
For SYCL, the following debug environment variables are recommended. A full list is available from GitHub.
Name |
Value |
Description |
|---|---|---|
SYCL_DEVICE_FILTER |
backend:device_type:device_num |
|
SYCL_PI_TRACE |
1|2|-1 |
1: print out the basic trace log of the DPC++ runtime plugin 2: print out all API traces of DPC++ runtime plugin -1: all of “2” including more debug messages |
ZE_DEBUG |
Variable defined with any value - enabled |
This environment variable enables debug output from the Level Zero backend when used with the DPC++ runtime. It reports: * Level Zero APIs called * Level Zero event information |
For OpenMP, the following debug environment variables are recommended. A full list is available from the LLVM/OpenMP documentation.
Name |
Value |
Description |
|---|---|---|
LIBOMPTARGET_DEVICETYPE |
cpu | gpu |
Select |
LIBOMPTARGET_DEBUG |
1 |
Print out verbose debug information |
LIBOMPTARGET_INFO |
Allows the user to request different types of runtime information from libomptarget |
Use Ahead of Time (AOT) to move Just-in-Time (JIT) compilations to AOT compilation issues.
CL_OUT_OF_RESOURCES Error
The CL_OUT_OF_RESOURCES error can occur when a kernel uses more __private or __local memory than the emulator supports by default.
When this occurs, you will see an error message similar to this:
$ ./myapp : Problem size: c(150,600) = a(150,300) * b(300,600) terminate called after throwing an instance of 'cl::sycl::runtime_error' what(): Native API failed. Native API returns: -5 (CL_OUT_OF_RESOURCES) -5 (CL_OUT_OF_RESOURCES) Aborted (core dumped) $
Or if using onetrace:
$ onetrace -c ./myapp : >>>> [6254070891] zeKernelSuggestGroupSize: hKernel = 0x263b7a0 globalSizeX = 163850 globalSizeY = 1 globalSizeZ = 1 groupSizeX = 0x7fff94e239f0 groupSizeY = 0x7fff94e239f4 groupSizeZ = 0x7fff94e239f8 <<<< [6254082074] zeKernelSuggestGroupSize [922 ns] -> ZE_RESULT_ERROR_OUT_OF_DEVICE_MEMORY(0x1879048195) terminate called after throwing an instance of 'cl::sycl::runtime_error' what(): Native API failed. Native API returns: -5 (CL_OUT_OF_RESOURCES) -5 (CL_OUT_OF_RESOURCES) Aborted (core dumped) $
To see how much memory was being copied to shared local memory and the actual hardware limit, set debug keys:
export PrintDebugMessages=1 export NEOReadDebugKeys=1
This will change the output to:
$ ./myapp : Size of SLM (656384) larger than available (131072) terminate called after throwing an instance of 'cl::sycl::runtime_error' what(): Native API failed. Native API returns: -5 (CL_OUT_OF_RESOURCES) -5 (CL_OUT_OF_RESOURCES) Aborted (core dumped) $
Or, if using onetrace:
$ onetrace -c ./myapp : >>>> [317651739] zeKernelSuggestGroupSize: hKernel = 0x2175ae0 globalSizeX = 163850 globalSizeY = 1 globalSizeZ = 1 groupSizeX = 0x7ffd9caf0950 groupSizeY = 0x7ffd9caf0954 groupSizeZ = 0x7ffd9caf0958 Size of SLM (656384) larger than available (131072) <<<< [317672417] zeKernelSuggestGroupSize [10325 ns] -> ZE_RESULT_ERROR_OUT_OF_DEVICE_MEMORY(0x1879048195) terminate called after throwing an instance of 'cl::sycl::runtime_error' what(): Native API failed. Native API returns: -5 (CL_OUT_OF_RESOURCES) -5 (CL_OUT_OF_RESOURCES) Aborted (core dumped) $
See Debugging the DPC++ and OpenMP Offload Process for more information on debug techniques and debugging tools available with oneAPI.
Optimize GPU Code
There are multiple ways to optimize offloaded code. The following list provides some starting points. Review the oneAPI GPU Optimization Guide for additional information.
Reduce overhead of memory transfers between host and device.
Have enough work to keep the cores busy and reduce the data transfer overhead cost.
Use GPU memory hierarchy like GPU caches, shared local memory for faster memory accesses.
Use AOT compilation (offline compilation) instead of JIT compilation. With offline compilation, you could target your code to specific GPU architecture. Refer to Offline Compilation for GPU for details.
The Intel® GPU Occupancy Calculator allows you to compute the occupancy of an Intel® GPU for a given kernel and work group parameters.
Additional recommendations are available from Optimize Offload Performance.