A newer version of this document is available. Customers should click here to go to the newest version.
Visible to Intel only — GUID: GUID-79B9054D-9873-4D84-93E8-BD8339DD19B0
Visible to Intel only — GUID: GUID-79B9054D-9873-4D84-93E8-BD8339DD19B0
Intel® VTuneTM Profiler
Intel® VTuneTM Profiler is a performance analysis tool for serial and multi-threaded applications. It helps you analyze algorithm choices and identify where and how your application can benefit from available hardware resources. Use it to locate or determine:
Sections of code that don’t effectively utilize available processor resources
The best sections of code to optimize for both sequential and threaded performance
Synchronization objects that affect the application performance
Whether, where, and why your application spends time on input/output operations
Whether your application is CPU-bound or GPU-bound and how effectively it offloads code to the GPU
The performance impact of different synchronization methods, different numbers of threads, or different algorithms
Thread activity and transitions
Hardware-related issues in your code such as data sharing, cache misses, branch misprediction, and others
Profiling a SYCL application running on a GPU
The tool also has new features to support GPU analysis:
GPU Offload Analysis (technical preview)
GPU Compute/Media Hotspots Analysis (technical preview)
GPU Offload Analysis (Preview)
Use this analysis type to analyze code execution on the CPU and GPU cores of your platform, correlate CPU and GPU activity, and identify whether your application is GPU-bound or CPU-bound. The tool infrastructure automatically aligns clocks across all cores in the system so you can analyze some CPU-based workloads together with GPU-based workloads within a unified time domain. This analysis lets you:
Identify how effectively your application uses SYCL or OpenCLTM kernels.
Analyze execution of Intel Media SDK tasks over time (for Linux targets only).
Explore GPU usage and analyze a software queue for GPU engines at each moment in time.
GPU Compute/Media Hotspots Analysis (Preview)
Use this tool to analyze the most time-consuming GPU kernels, characterize GPU usage based on GPU hardware metrics, identify performance issues caused by memory latency or inefficient kernel algorithms, and analyze GPU instruction frequency for certain instruction types. The GPU Compute/Media Hotspots analysis lets you:
Explore GPU kernels with high GPU utilization, estimate the efficiency of this utilization, and identify possible reasons for stalls or low occupancy.
Explore the performance of your application per selected GPU metrics over time.
Analyze the hottest SYCL or OpenCL kernels for inefficient kernel code algorithms or incorrect work item configuration.
Run GPU Offload Analysis on a SYCL Application.
Using VTune Profiler to Analyze GPU Applications
Launch VTune Profiler and from the Welcome page, click New Project. The Create a Project dialog box opens.
Specify a project name and a location for your project and click Create Project. The Configure Analysis window opens.
Make sure the Local Host is selected in the WHERE pane.
In the WHAT pane, make sure the Launch Application target is selected and specify the matrix_multiply binary as an Application to profile.
In the HOW pane, select the GPU Offload analysis type from the Accelerators group.
Click Start to launch the analysis.
This is the least intrusive analysis for applications running on platforms with Intel Graphics as well as third-party GPUs supported by VTune Profiler.
Run Analysis from the Command Line
To run the analysis from the command line:
On Linux* OS:
Set VTune Profiler environment variables by sourcing the script:
source <*install_dir*>/env/vars.sh
Run the analysis command:
vtune -collect gpu-offload -- ./matrix.dpcpp
On Windows* OS:
Set VTune Profiler environment variables by running the batch file:
export <*install_dir*>\env\vars.bat
Run the analysis command:
vtune.exe -collect gpu-offload -- matrix_multiply.exe
Analyzing Collected Data
Start your analysis with the GPU Offload viewpoint. In the Summary window, you can see see statistics on CPU and GPU resource usage to determine if your application is GPU-bound, CPU-bound, or not effectively utilizing the compute capabilities of the system. In this example, the application should use the GPU for intensive computation. However, the result summary indicates that GPU usage is actually low.
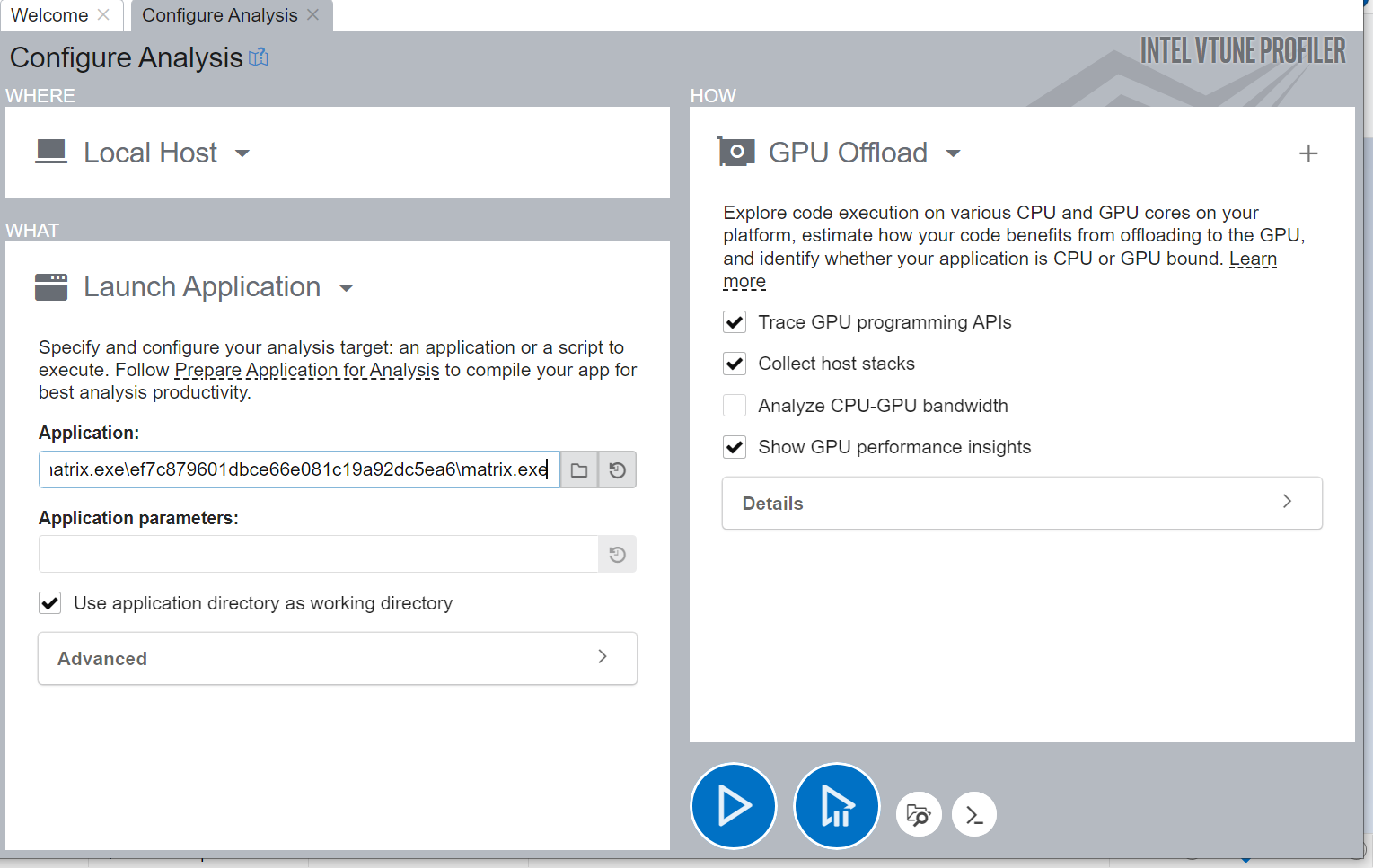
Switch to the Platform window. Here, you can see basic CPU and GPU metrics that help analyze GPU usage on a software queue. This data is correlated with CPU usage on the timeline. The information in the Platform window can help you make some inferences.

Most applications may not present obvious situations as described above. A detailed analysis is important to understand all dependencies. For example, GPU engines that are responsible for video processing and rendering are loaded in turns. In this case, they are used in a serial manner. When the application code runs on the CPU, this can cause ineffective scheduling on the GPU, which can lead you to mistakenly interpret the application as GPU bound.
Identify the GPU execution phase based on the computing task reference and GPU Utilization metrics. Then, you can define the overhead for creating the task and placing it in a queue.
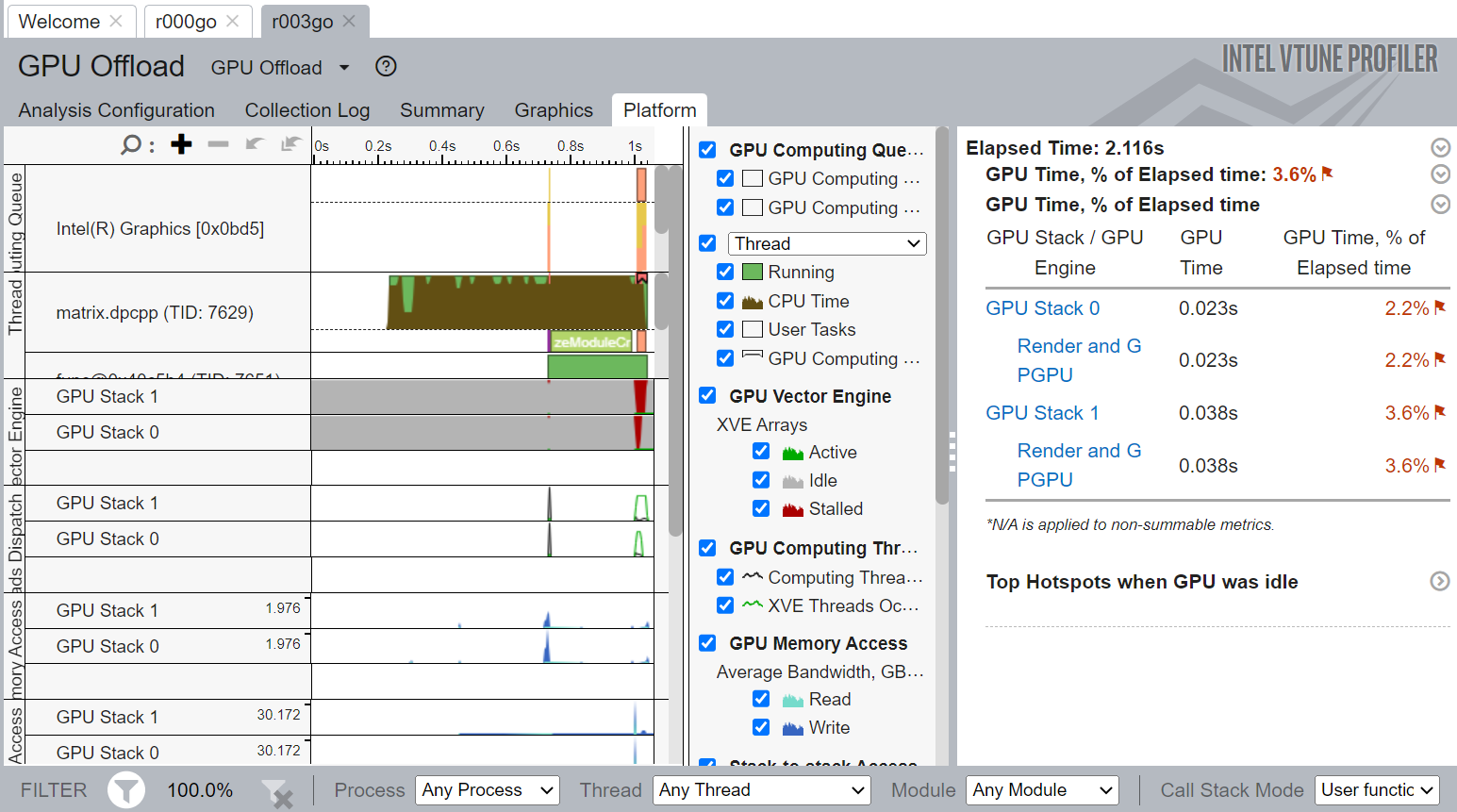
To investigate a computing task, switch to the Graphics window to examine the type of work (rendering or computation) running on the GPU per thread. Select the Computing Task grouping and use the table to study the performance characterization of your task. To further analyze your computing task, run the GPU Compute/Media Hotspots analysis type.
Run GPU Compute/Media Hotspots Analysis
To run the analysis:
In the Accelerators group, select the GPU Compute/Media Hotspots analysis type.
Configure analysis options as described in the previous section.
Click Start to run the analysis.
Run Analysis from the Command line
On Linux OS:
vtune -collect gpu-hotspots -- ./matrix.dpcpp
On Windows OS:
vtune.exe -collect gpu-hotspots -- matrix_multiply.exe
Analyze Your Compute Tasks
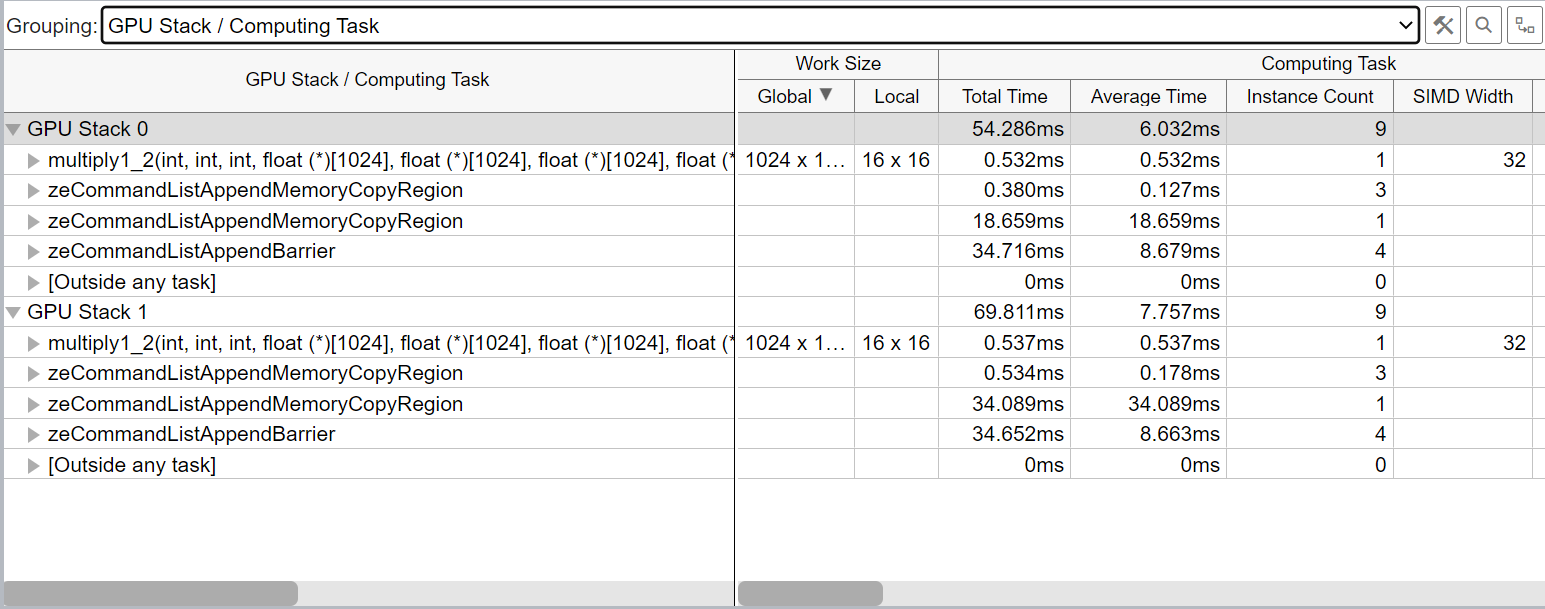
The default analysis configuration invokes the Characterization profile with the Overview metric set. In addition to individual compute task characterization available through the GPU Offload analysis, VTune Profiler provides memory bandwidth metrics that are categorized by different levels of GPU memory hierarchy.
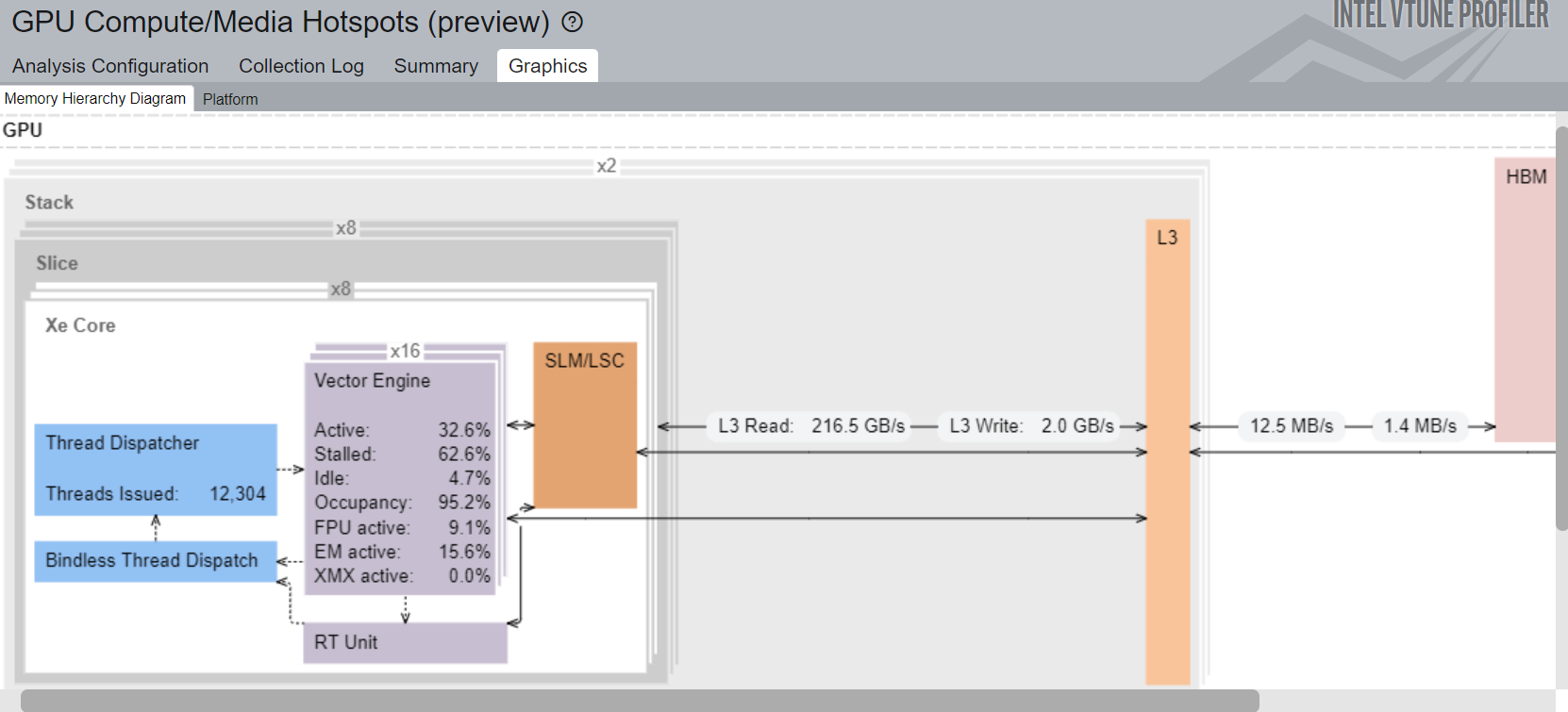
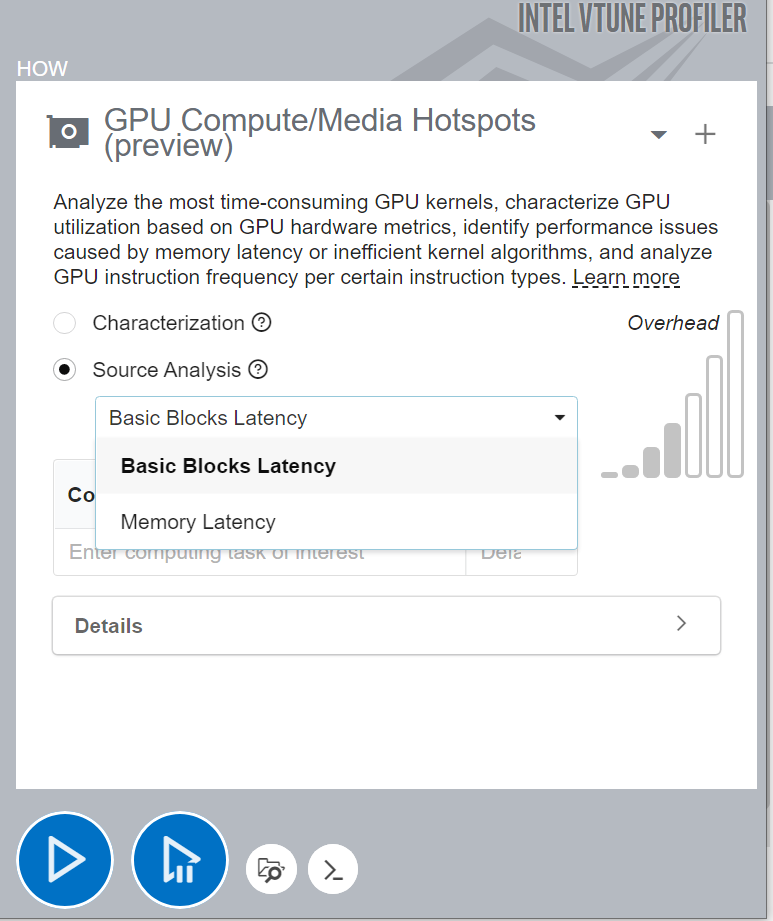
You can analyze compute tasks at source code level too. For example, to count GPU clock cycles spent on a particular task or due to memory latency, use the Source Analysis option.
Use our matrix multiply example in SYCL:
// Basic matrix multiply void multiply1(int msize, int tidx, int numt, TYPE a[][NUM], TYPE b[][NUM], TYPE c[][NUM], TYPE t[][NUM]) { int i, j, k; // Declare a deviceQueue sycl::queue q(sycl::default_selector_v, exception_handler); cout << "Running on " << q.get_device().get_info<sycl::info::device::name>() << "\n"; // Declare a 2 dimensional range sycl::range<2> matrix_range{NUM, NUM}; // Declare 3 buffers and Initialize them sycl::buffer<TYPE, 2> bufferA((TYPE *)a, matrix_range); sycl::buffer<TYPE, 2> bufferB((TYPE *)b, matrix_range); sycl::buffer<TYPE, 2> bufferC((TYPE *)c, matrix_range); // Submit our job to the queue q.submit([&](auto &h) { // Declare 3 accessors to our buffers. The first 2 read and the last // read_write sycl::accessor accessorA(bufferA, h, sycl::read_only); sycl::accessor accessorB(bufferB, h, sycl::read_only); sycl::accessor accessorC(bufferC, h); // Execute matrix multiply in parallel over our matrix_range // ind is an index into this range h.parallel_for(matrix_range, [=](sycl::id<2> ind) { int k; for (k = 0; k < NUM; k++) { // Perform computation ind[0] is row, ind[1] is col accessorC[ind[0]][ind[1]] += accessorA[ind[0]][k] * accessorB[k][ind[1]]; } }); }).wait_and_throw(); } // multiply1
Analyzing the GPU-offload report from the command-line gives detailed recommendations on how to optimize the application.
GPU Time, % of Elapsed time: 6.8% | GPU utilization is low. Consider offloading more work to the GPU to | increase overall application performance. | Top Hotspots when GPU was idle Function Module CPU Time -------------------------- --------------- -------- [Outside any known module] [Unknown] 0.402s [Skipped stack frame(s)] [Unknown] 0.228s operator new libc++abi.so 0.136s memmove libc-dynamic.so 0.078s memcmp libc-dynamic.so 0.058s [Others] N/A 0.918s Hottest Host Tasks Host Task Task Time % of Elapsed Time(%) Task Count ----------------------------------- --------- -------------------- ---------- zeModuleCreate 0.233s 22.4% 1 zeEventHostSynchronize 0.068s 6.5% 6 zeCommandListCreateImmediate 0.003s 0.3% 1 zeCommandListAppendMemoryCopyRegion 0.002s 0.2% 4 zeMemAllocDevice 0.002s 0.2% 3 [Others] 0.003s 0.3% 14 Hottest GPU Computing Tasks GPU Adapter Computing Task Total Time Execution Time % of Total Time(%) SIMD Width XVE Threads Occupancy(%) SIMD Utilization(%) -------------------------------------------------------------- ------------------------------------------------------------------------------------------------- -------------------------------------------------------------------------------------------------------- ---------- -------------- ------------------ ------- --- ------------------------ ------------------- 0:41:0.0 : Display controller: Intel Corporation Device 0x0bdb multiply1_2(int, int, int, float (*)[1024], float (*)[1024], float (*)[1024], float (*)[1024]):: {lambda()#1}::operator()<sycl::_V1::handler>(, signed char) const::{lambda(sycl::_V1::nd_item<(int)2>)#1} 0.071s 0.003s 4.5% 32 97.0% 100.0% 0:41:0.0 : Display controller: Intel Corporation Device 0x0bdb zeCommandListAppendBarrier 0.065s 0s 0.0% Collection and Platform Info Application Command Line: ./matrix.dpcpp Operating System: 5.15.47+prerelease6379.25 DISTRIB_ID=Ubuntu DISTRIB_RELEASE=20.04 DISTRIB_CODENAME=focal DISTRIB_DESCRIPTION="Ubuntu 20.04.2 LTS" Computer Name: ortce-pvc1 Result Size: 49.2 MB Collection start time: 04:55:43 16/03/2023 UTC Collection stop time: 04:55:44 16/03/2023 UTC Collector Type: Event-based sampling driver,Driverless Perf system-wide sampling,User-mode sampling and tracing CPU Name: Intel(R) Xeon(R) Processor code named Sapphirerapids Frequency: 2.000 GHz Logical CPU Count: 224 LLC size: 110.1 MB GPU 0:41:0.0: Display controller: Intel Corporation Device 0x0bdb: XVE Count: 448 Max XVE Thread Count: 8 Max Core Frequency: 1.550 GHz 0:58:0.0: Display controller: Intel Corporation Device 0x0bdb: XVE Count: 448 Max XVE Thread Count: 8 Max Core Frequency: 1.550 GHz Recommendations: GPU Time, % of Elapsed time: 6.8% | GPU utilization is low. Switch to the for in-depth analysis of host | activity. Poor GPU utilization can prevent the application from | offloading effectively. XVE Array Stalled/Idle: 97.0% of Elapsed time with GPU busy | GPU metrics detect some kernel issues. Use GPU Compute/Media Hotspots | (preview) to understand how well your application runs on the specified | hardware. Execution % of Total Time: 2.4% | Execution time on the device is less than memory transfer time. Make sure | your offload schema is optimal. Use Intel Advisor tool to get an insight | into possible causes for inefficient offload.
We can also examine how efficiently our GPU kernel is running using GPU-hotspots. How often our execution units are stalled can be a good indication of GPU performance. Another important metric is whether we are L3 bandwidth bound.
Elapsed Time: 1.682s GPU Time: 0.071s Display controller: Intel Corporation Device 0x0bdb Device Group XVE Array Stalled/Idle: 98.5% of Elapsed time with GPU busy | The percentage of time when the XVEs were stalled or idle is high, which | has a negative impact on compute-bound applications. | This section shows the XVE metrics per stack and per adapter for all the devices in this group. GPU Stack GPU Adapter XVE Array Active(%) XVE Array Stalled(%) XVE Array Idle(%) --------- -------------------------------------------------------------- ------------------- -------------------- ----------------- 0 0:58:0.0 : Display controller: Intel Corporation Device 0x0bdb 0.0% 0.0% 100.0% 0 0:41:0.0 : Display controller: Intel Corporation Device 0x0bdb 0.1% 3.8% 96.0% GPU L3 Bandwidth Bound: 0.2% of peak value
Running VTune on a Multi-Stack GPU
The Intel® Data Center GPU Max Series has a multi-stack architecture. This architecture presents some new performance considerations. If you are using an older version of VTune (prior to 2021.7), To collect GPU HW metrics from all stacks set the following environment variable.
export AMPLXE_EXPERIMENTAL=gpu-multi-tile-metrics
On a multi-stack GPU there are two ways for you to run your application: Implicit scaling, explicit scaling. Implicit scaling does not require code modifications, the GPU driver distributes thread-groups of a device kernel to both stacks.
To use implicit scaling, set the following environment variable.
export EnableImplicitScaling=1
Explicit scaling requires code modifications, so you need to specify to which stack you would like your kernel to run. Using explicit scaling you can often achieve better performance because of additional control that it gives you. Full profiling support is available for explicit scaling mode including per-stack attribution of GPU HW metrics and compute kernels
Application Scaling
To test whether application is scaling on two stacks. First try running on a single stack using the ZE_AFFINITY_MASK environment variable.
export ZE_AFFINITY_MASK=0.0
export ZE_AFFINITY_MASK=0.1
Then compare whether application is running faster on single stack vs two stacks with implicit scaling.
Because of NUMA (and other issues), 2 stacks may not scale without tuning. There are some architecture details that you need to consider:
Each stack on an Intel® Data Center GPU Max has its own L3 cache.
These caches are not coherent.
USM allocations are managed by the GPU driver.
A device cannot access memory allocated on another device.
To understand your kernels performance it is important to understand:
How kernels utilize the execution resources of different stacks.
How allocations are spread across the memory of different stacks.
Where allocations “live” and how they move around the system.
Multi-Stack Analysis
In the VTune GUI you can see all of your GPU execution units on a per stack basis, as shown below.

You can also correlate your activity on the stacks and see when one is idle or stalled.

VTune also shows you your read/write memory bandwidth on each stack across the kernel timeline.

You can also view how well you are using your L3 cache and the cache bandwidth.

GPU Frequency is one factor that can affect your performance. You should note frequency changes, especially if the stacks are operating at difference frequencies. This will require additional investigation

Occupancy analysis
Occupancy - sum of all cycles when thread slots have a thread scheduled.
The idea is to estimate Peak Occupancy based on kernel parameters.
Limiting factors:
Global and local sizes
SLM size requested
Barriers usage (in progress)
Tiny/huge kernels scheduling issues (in analysis)
Multi-GPU
In addition to being able to analyze multiple stacks, VTune can also analyze multiple GPUs. Multiple GPUs are when you have more than one GPU cards attached to your system. If you are using an older version of VTune (prior to 2021.7), To analyze multiple GPUs, use the following environment variables.
export AMPLXE_EXPERIMENTAL=gpu-multi-adapter-metrics,gpu-multi-tile-metrics
To collect on a specific GPU, you need to identify each GPU device and run lspci on Linux to find out the bus/device/function (BDF) of its adapter.
You need to use this format [B:D:F] when specifying your GPU on collection and set -knob target-gpu=BDF in decimal format
For example, the following specifies GPU with BDF=’0000:4d:00.0’ to be profiled by VTune:
vtune -c gpu-hotspots -knob target-gpu=0:77:0.0 -- <your application>
In the GUI, use the Target GPU pulldown menu to specify the device you want to profile. The pulldown menu displays only when VTune Profiler detects multiple GPUs running on the system. The menu then displays the name of each GPU with the BDF of its adapter. If you do not select a GPU, VTune Profiler selects the most recent device family in the list by default.
Hardware-assist Stall Sampling
Hardware-assisted stall sampling is a new performance monitoring capability implemented in Intel® Data Center GPU Max Series. The following section covers some of the details.
For more ways to optimize GPU performance using VTune Profiler, see Software Optimization for Intel® GPUs in the Intel® VTune™ Profiler Performance Analysis Cookbook and Optimize Applications for Intel® GPUs with Intel® VTune™ Profiler .