Next-generation sequencing (NGS) technologies have significantly reduced the cost and time required to sequence whole genomes and exomes. NGS and efficient secondary analysis have brought precision medicine to the clinical setting and even to the point of care. Sentieon optimized their genome analytics software for 3rd Gen Intel® Xeon® Scalable processors and the 4th Gen Intel Xeon Scalable processor (formerly code-named Sapphire Rapids). It is designed to scale on multicore systems to achieve best-in-class performance whether the clinical requirement is fast turnaround (e.g., in the emergency department to predict adverse drug reactions from a single patient genome) or high throughput (e.g., in an oncology lab to analyze multiple samples from the same tumor or from different patients).
The Sentieon software is vectorized for modern processors, particularly Intel Xeon processors, to achieve high performance without proprietary programming languages or specialized hardware, which eliminates vendor lock-in and reduces software development, deployment, and maintenance costs. We wanted to compare Sentieon performance and accuracy to alternatives, like NVIDIA Clara Parabricks*, to see if specialized hardware is cost-effective or even necessary.
Recent performance data is available for comparison: Benchmarking the NVIDIA Clara Parabricks Germline Pipeline on AWS. This article reports performance and cost data for the following HG001 tests:
- Whole Exome Sequencing (WES) @ 50x, 75x, and 100x coverage
- Whole Genome Sequencing (WGS) @ 30x and 50x coverage
We will focus on the HG001 WGS 30x test from the PrecisionFDA Truth Challenge. A Parabricks vs. Genome Analysis Toolkit (GATK) performance comparison is provided for this test (Figure 1). GATK is the standard by which variant calling accuracy is judged, but it is written in Java, so it is not the gold standard of performance. The University of Illinois and the Mayo Clinic have already established that Sentieon significantly outperforms GATK with no loss of accuracy: Sentieon DNASeq Variant Calling Workflow Demonstrates Strong Computational Performance and Accuracy. Therefore, we will not bother with a GATK comparison. Our goal is to compare the Sentieon software (written in C++ and optimized for modern vector CPUs) to Parabricks (written in CUDA* and optimized for NVIDIA GPUs).
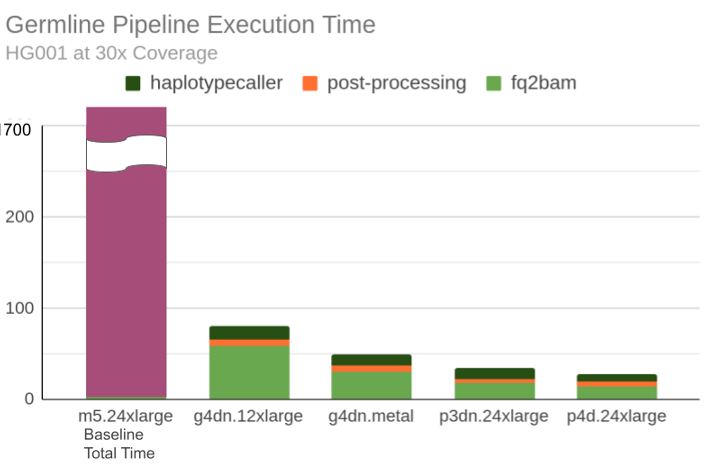
Figure 1. Comparison of NVIDIA Clara Parabricks* execution time (in minutes) against a GATK baseline on various AWS EC2* instance types (Source: Benchmarking the NVIDIA Clara Parabricks Germline Pipeline on AWS, Figure 4).
We used the benchmark description and performance data from Figure 1 to get as close as possible to an apples-to-apples performance comparison of Sentieon and Parabricks. We mapped the haplotypecaller, post-processing, and fq2bam steps from Figure 1 to the typical stages of the variant calling pipeline (Table 1). Our mapping is based on the following description from the Parabricks benchmarks:
“The fq2bam step includes bwa-mem and parts of coordinate sorting, post-processing includes parts of coordinate sorting, marking duplicates followed by bqsr. haplotypecaller the applybqsr step applied on the input bam, which is then fed to the variant calling step.”
|
Pipeline Stage |
Parabricks* |
Sentieon |
|---|---|---|
|
Alignment |
|
|
|
Sorting |
||
|
Deduplication |
|
|
|
BQSR |
||
|
Apply BQSR |
|
|
|
Variant Calling |
Table 1. Stages of the variant calling pipeline and their Parabricks* and Sentieon equivalents for performance comparisons.
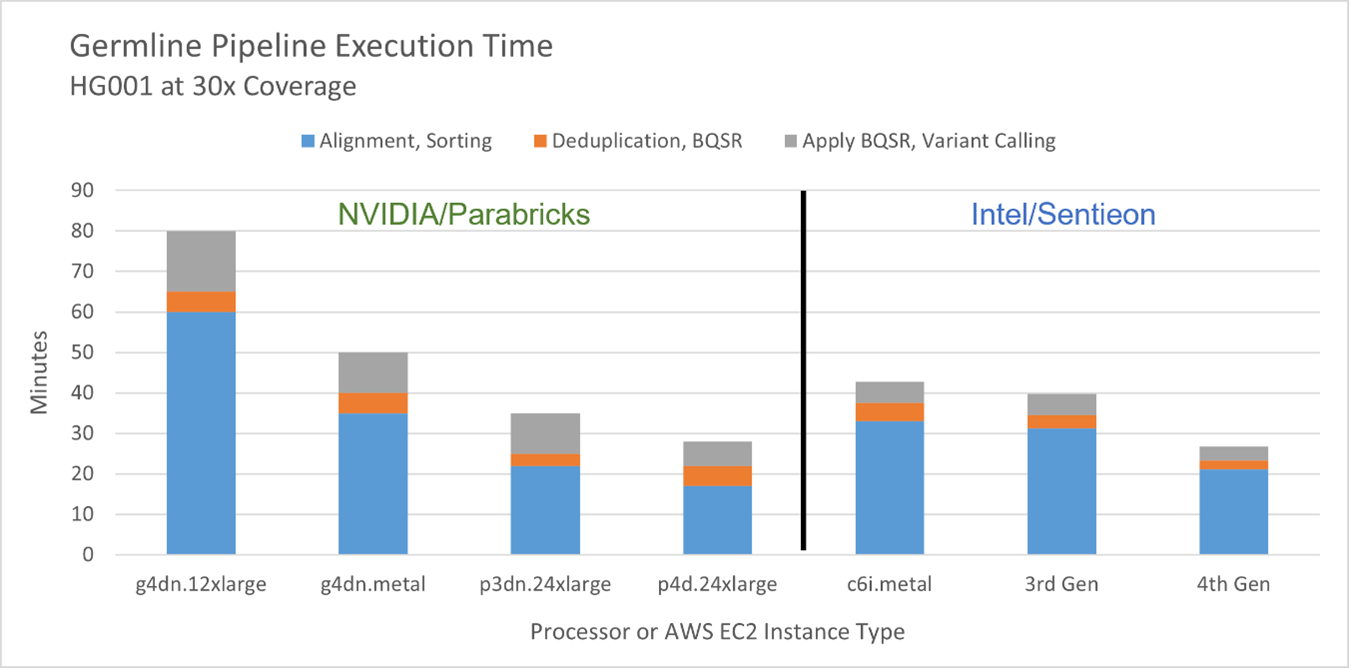
The side-by-side competitive performance of Sentieon vs. Parabricks on a variety of computing platforms is shown in Figure 2 and Table 2. The platforms and pricing details are shown in Table 3. 3rd Gen Intel Xeon Scalable processors deliver competitive performance, with the 4th Gen Intel Xeon Scalable processor (formerly code-named Sapphire Rapids) giving the best overall performance. However, performance is only part of the story. Cost-per-genome and power consumption must also be considered.
The cost-per-genome is substantially lower for the Intel Xeon processor ($1.54) compared to NVIDIA A100 Tensor Core processor ($4.59) (Table 3). If the 4th Gen Intel Xeon Scalable processor has similar AWS EC2* pricing, the cost-per-genome falls to less than a dollar ($2.1635/h * 26.8 minutes = $0.97). It is also worth noting that the 4th Gen Intel Xeon Scalable processors used in these benchmarks are prerelease hardware, so the performance of the final product could improve.
In terms of power consumption, the two Intel Xeon Platinum 8352M processors in the c6i.metal instance require 370W, whereas the eight NVIDIA A100 Tensor Core processors in the p4d.24xlarge instance require 3,200W. The best Parabricks performance requires 8.6x the power and 3.0x the cost but only delivers 1.5x the performance of the 3rd Gen Intel Xeon 8352M processor.
Performance measurements were performed by Sentieon in March 2022. The 3rd Gen Xeon Scalable processor-based system is a two-socket 2.4 GHz Intel Xeon Platinum 8368 processor (152 cores, HyperThreading enabled), 256 GB DDR4-3200 memory, and 1 TB Intel® 660p and 2 TB Intel DC P4510 SSDs. The 4th Gen Intel Xeon Scalable processor-based system is an Intel® pre-production platform with two 4th Gen Intel Xeon Scalable processors (formerly codenamed Sapphire Rapids, >40 cores, HyperThreading enabled), Intel pre-production BIOS, 256 GB DDR memory (16(1DPC)/16 GB/4800 MT/s), and 1 TB Intel D3-S4610 SSD. Ubuntu Linux* 20.04 was installed on both systems. Performance varies by use, configuration, and other factors so results may vary.
Figure 2. Side-by-side competitive performance of Sentieon vs. Parabricks* on a variety of cloud and on-premises platforms. Note that the Parabricks times are taken from the published results or approximated from visual inspection of Figure 1.
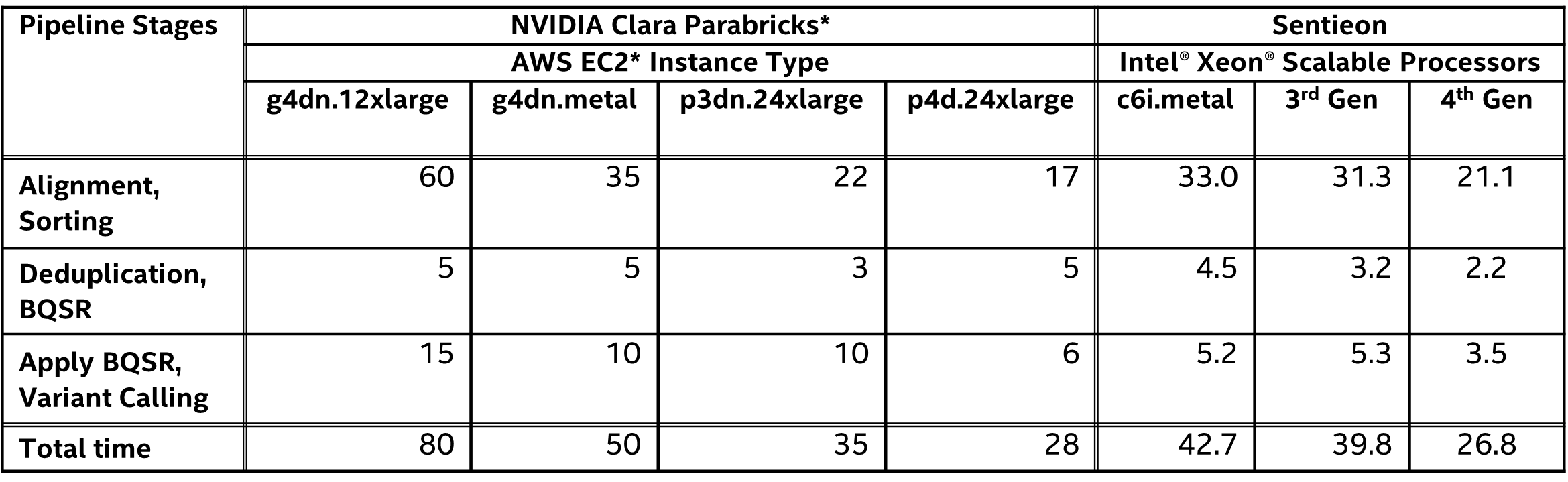
Table 2. Execution time (in minutes) for Parabricks* and Sentieon on a variety of cloud and on-premises platforms. Note that the Parabricks times are taken from the published results or approximated from visual inspection of Figure 1.
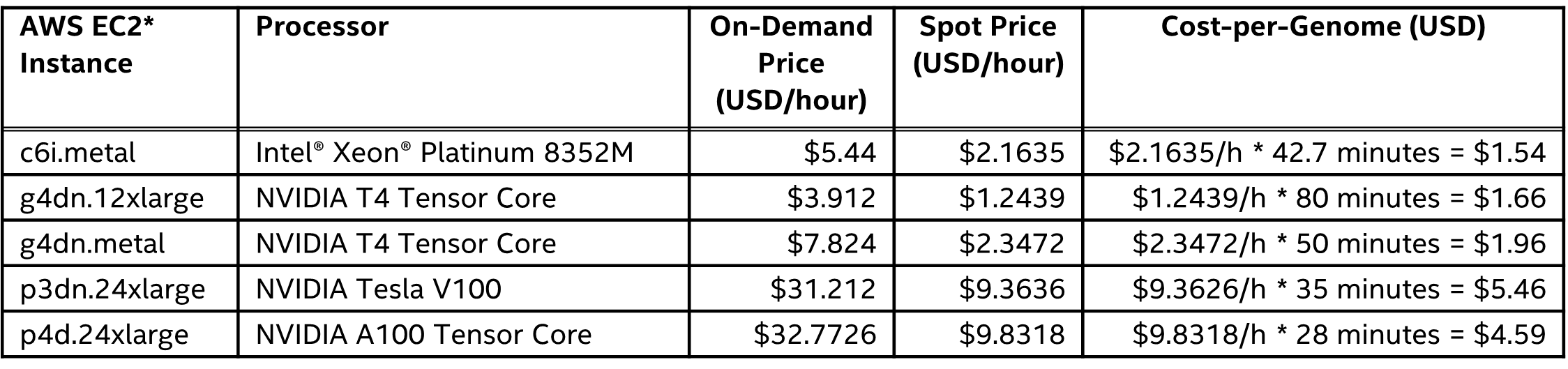
Table 3. AWS EC2* price comparisons for Intel® and NVIDIA instances. Prices are for on-demand and spot instances in the US West (Oregon) region as of March 11, 2022 (see Amazon EC2 Pricing).
The Parabricks blog cited above reports variant calling accuracy (F1 scores) comparable to GATK. Sentieon, however, is a consistent winner in the PrecisionFDA Truth Challenge administered by the US Food and Drug Administration (Figure 3). The HG001 benchmark comes from this challenge. In the more recent PrecisionFDA Truth Challenge V2, Sentieon competed against 19 other teams and won four of the 12 categories. Parabricks was not among the entries.

Figure 3. Results from the first PrecisionFDA Truth Challenge, showing Sentieon winning two of the six categories.
Sentieon does not use proprietary programming languages like CUDA, thus avoiding vendor lock-in. The software is written in standard C++. It is also optimized to take advantage of the vector processing capability of modern processors. Sentieon uses algorithmic improvements rather than expensive, power-hungry hardware to achieve performance. It supports and optimizes for all short- and long-read sequencing platforms, and it is a consistent winner in the FDA’s open challenges. This demonstrates that Sentieon on Intel Xeon Scalable processors is the leadership platform for genome secondary analysis.