What Is Graph Analytics? Why Does It Matter?
Henry A. Gabb, senior principal engineer, Intel Corporation, and editor, The Parallel Universe
@IntelDevTools
Get the Latest on All Things CODE
Sign Up
A graph is a good way to represent a set of objects and the relations between them (Figure 1). Graph analytics is the set of techniques to extract information from connections between entities.
For example, graph analytics can be used to:
- Get recommendations among friends in a social network.
- Find cut points in a communication network or electrical grid.
- Determine drug effects on a biochemical pathway.
- Detect robocalls in a telecommunications network.
- Find optimal routes between locations on a map.
Figure 1. Graphs are everywhere
Graph analytics has been getting a lot of attention lately, possibly because Gartner* listed it among the top 10 data and analytics technology trends for 2019:
“The application of graph processing and graph [database management systems] DBMS will grow at 100 percent annually through 2022 to continuously accelerate data preparation and enable more complex adaptive data science.” (Source: Gartner Identifies Top 10 Data and Analytics Technology Trends for 2019)
Intel has a long history of leadership in graph analysis. For example, Intel coauthored the GraphBLAS specification to formulate graph problems such as sparse linear algebra. Though the GraphBLAS API was published in 2017, the initial proposal and manifesto were published over 10 years ago. Today, the same industry and academic partnership is coauthoring the forthcoming LAGraph specification for a library of graph algorithms. The Defense Advanced Research Projects Agency (DARPA) also selected Intel to develop a new processor to handle large graph datasets (see DARPA Taps Intel for Graph Analytics Chip Project). We continue to innovate and push the graph analytics envelope.
Benchmark Graph Analytics Performance
Graph analytics is a large and varied landscape. Even the simple examples in Figure 1 show differing characteristics. For example, some networks are highly connected while others are sparser. A network of webpages exhibits different connectivity than a network of Twitter* users, where some have millions of followers while most have only a few. Consequently, no single combination of graph algorithm, graph topology, or graph size can adequately represent the entire landscape.
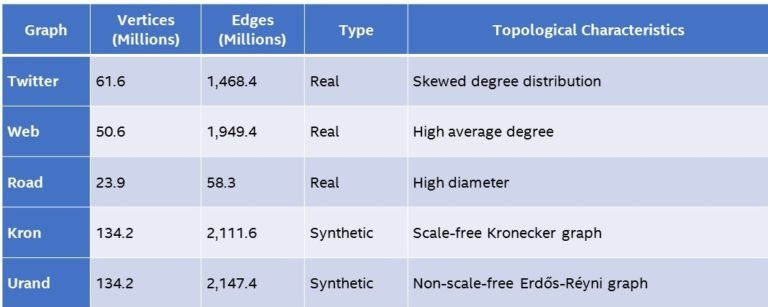
Therefore, we use the Graph Algorithm Platform (GAP) Benchmark Suite from the University of California, Berkeley, to measure graph analytics performance. GAP specifies six widely used algorithms (Table 1) and five small- to medium-sized graphs (Table 2). Each graph has different characteristics: Optimizations that work well for one graph topology may not work well for others. For example, the Road* graph is relatively small, but its high diameter can cause problems for some algorithms. Consequently, the 30 GAP data points provide good coverage of the graph analytics landscape.
Table 1. GAP measures the performance of six common graph analytics algorithms.
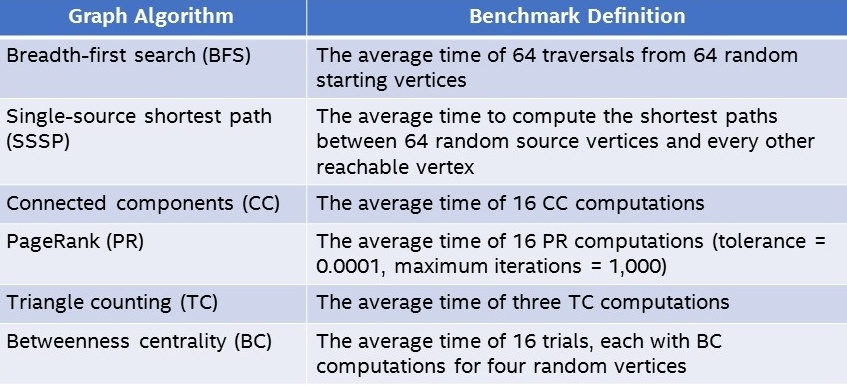
Table 2. GAP uses five graphs of varying size and topology to give a more complete picture of graph analytics performance.
GAP also has the advantages of being a clearly defined, objective, off-the-shelf benchmark. It doesn’t require special hardware or software configurations, so it’s easy to run.
To run the benchmark:
- Download the GAP package.
- To build the reference implementations for the six graph analytics kernels, run make in the gapbs-master subdirectory.
Note These steps use the default GAP build parameters (the GNU C++* v7.4.0 compiler with -std=c++11 -O3 -Wall -fopenmp options). - To download or generate the five benchmark graphs and convert them to more efficient input formats, in the same directory run make -f benchmark/bench.mk bench graphs.
- The GAP reference implementations are parallelized with OpenMP*, so it’s important to set the number of threads. Otherwise, GAP uses all available cores, even if this doesn’t give the best parallel efficiency. For example: The export OMP_NUM_THREADS=32 command sets the number of OpenMP threads to 32.
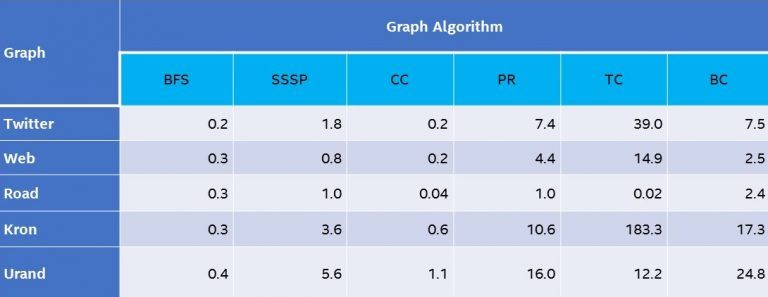
- To launch the benchmarks and generate results, run make -f benchmark/bench.mk bench run (Table 3).
Table 3. Compute times (in seconds, lower is better) for GAP running on a system1 based on a two-socket Intel® Xeon® processor. GAP was run with 1, 8, 16, 24, 32, 48, 64, and 96 threads. The best performance is shown for each test.
The attempt to generate NVIDIA* V100 comparative data ran into several technical barriers:
- Only one of the GAP graphs (Road) fits in the memory of a single NVIDIA V100.
- Only one of the GAP algorithms (PR) in RAPIDS cuGraph can use the aggregate memory of multiple NVIDIA V100s.
- The current version of cuGraph does not provide a business continuity (BC) implementation.
- The cuGraph APIs and documentation do not expose certain implementation details or algorithm parameters. For example, the implementation of multiple NVIDIA V100 PR in cuGraph does not provide a convergence tolerance parameter, which makes a direct comparison to the GAP results difficult.
Consequently, it’s only possible to run nine of the 30 GAP tests (Table 4). As you can see, where GAP can run on both architectures, the Intel Xeon processors outperformed the NVIDIA V100 on most tests, even when:
- The graph is small enough to fit in GPU memory (Road).
- The algorithm can use multiple GPUs (PageRank).
Also, the total cost of ownership (TCO) clearly favors Intel Xeon processors for graph analytics (Table 5).
Table 4. Compute times (in seconds, lower is better) for a cuGraph running on an Amazon EC2* p3.16xlarge instance (eight NVIDIA V100 GPUs connected via NVIDIA NVLink*). All Road tests used a single NVIDIA V100. Twitter and web tests used eight NVIDIA V100s.
Note The multiple NVIDIA V100 PRs in cuGraph does not provide a convergence tolerance parameter so the default parameters were used for these tests. Kron and Urand tests failed with a thrust::system::system_error. The following is also in the graph:
DNR: Does not run because of insufficient memory.
NA: Not available in cuGraph v0.9.0.
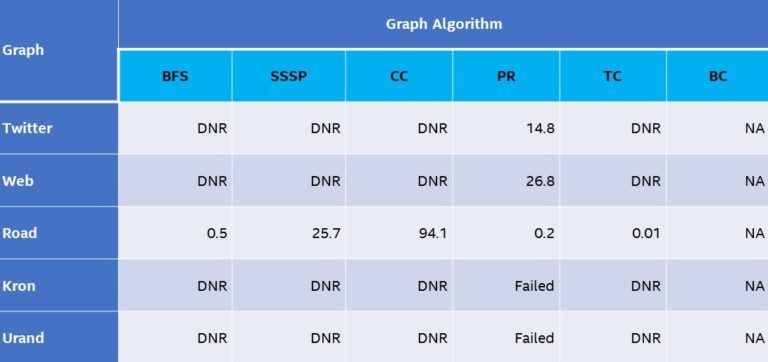
Table 5. A relative TCO of the Intel Xeon processor and NVIDIA V100 benchmark systems.
Note The Amazon Web Services (AWS)* price comparison is only an approximation because no Amazon EC2 instances exactly match the benchmarking system that's based on the Intel Xeon processor, but the m4.16xlarge instance is similar.

Comprehensive, Objective, and Reproducible
The GAP results on the platform for the Intel Xeon processor (Table 3) could be improved with a few simple changes, like:
- Using the Intel® compiler and aggressive optimization and vectorization
- Tweaking the OpenMP* OMP_PROC_BIND and OMP_PLACES environment variables, experimenting with the numactl utility, adjusting page sizes
- And more
But, that's not the purpose of this article. The goal is to show how to get comprehensive, objective, and reproducible graph analytics performance data without confusion or resorting to benchmarking tricks.
References
- Processors:
- Intel® Xeon® Gold processor 6252 (2.1 GHz, 24 cores), Intel® Hyper-Threading Technology enabled (48 virtual cores per socket); Memory: 384 GB Micron* DDR4-2666; Operating system: Ubuntu Linux* release 4.15.0-29, kernel 31.x86_64; Software: GAP Benchmark Suite (downloaded and run September 2019)
- NVIDIA Tesla* V100; Memory: 16 GB; Operating system: Ubuntu Linux 4.15.0-1047-aws, kernel 49.x86_64; Software: RAPIDS v0.9.0 (downloaded and run September 2019)
- Sources (all accessed September 2019):
- If you’re interested in tuning GAP, see Boost the Performance of Graph Analytics Workloads.
______
You May Also Like
Boost the Performance of Graph
Analytics Workloads
Read
Graph Analytics: A Foundational Building Block for the Data Analytics World
Intel® oneAPI Math Kernel Library
Accelerate math processing routines, including matrix algebra, fast Fourier transforms (FFT),
and vector math. Part of the Intel® oneAPI Base Toolkit.
Get It Now