
Intel is bringing AI everywhere with a portfolio of AI solutions founded on ubiquitous hardware and open software. These solutions provide competitive and compelling options for the community to develop and run large language models (LLMs) like Llama 2 and Llama 3.
As a part of the AI portfolio from Intel, Intel® Xeon® processors do a great job of tackling demanding everyday AI workloads. Available across all major cloud service providers, Intel Xeon processors have an AI engine (Intel® Advanced Matrix Extensions) in every core that unlocks new levels of performance for inference and training. With faster memory, a larger last-level cache, and more cores, 5th gen Intel Xeon processors deliver better AI performance than our previous generation, unmatched by any other CPU in the market.
Beyond hardware, our deep commitment to AI open software for Intel Xeon processors includes numerous optimizations leveraged by the developer ecosystem:
- Upstreaming optimizations into deep learning frameworks and available in default distributions of PyTorch*, TensorFlow*, DeepSpeed, and other AI libraries.
- Leading the development and optimization of the CPU back end of torch.compile, which is a flagship feature in PyTorch 2.0.
- Offering Intel® Extension for PyTorch* with advanced PyTorch optimizations before they are upstreamed into the official PyTorch distribution. LLM optimizations from Intel are publicly available in open source software. To attain peak performance for LLMs, follow the LLM guide on GitHub*.
An example of Intel’s relentless software optimization of LLM inference is a 5x latency reduction1 on LLMs compared to default PyTorch over 10 weeks in Q3 2023. These outcomes embody software and hardware working in concert, such as optimizations using paged attention and tensor parallelism to better leverage the available compute and memory bandwidth.
At Computex 2024, AMD showed the Turin 128C benchmarks3 against 5th gen Intel Xeon processors, but the results do not reflect achievable performance on 5th gen Intel Xeon processors with optimized open source software. AMD did not disclose the software stack it used for benchmarking. With publicly available software, 5th gen Intel Xeon processors outperform AMD future CPUs.
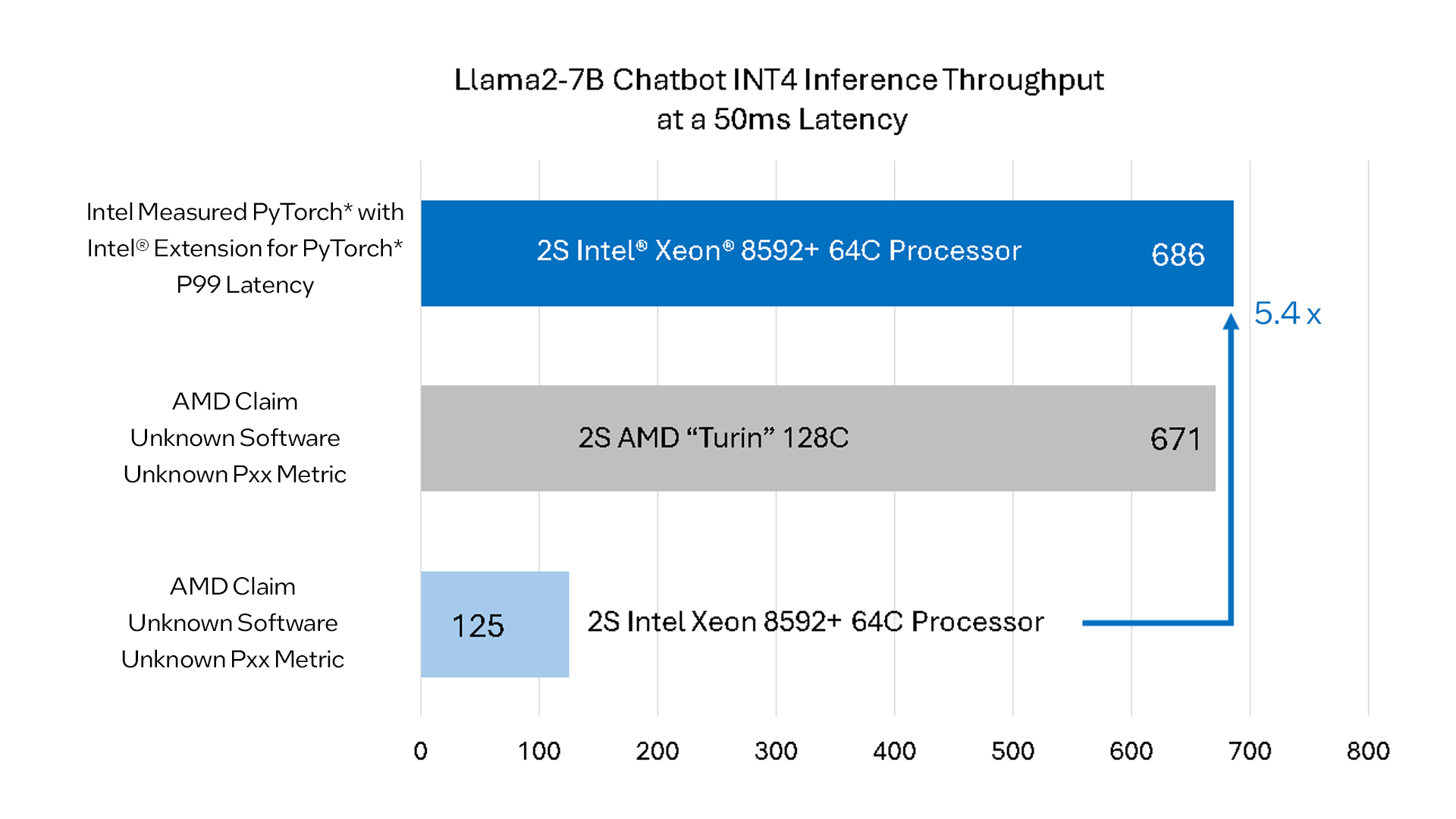
Figure 1. Intel 5th gen Intel Xeon processors with Llama2-7B performance versus the competition's next-generation CPU.2
For performance substantiation, see Product and Performance Notes.
Let's take a deeper look at the Llama2-7B chatbot use case, one of the most relatable use cases and one where AMD claims the 5th gen Intel Xeon processor is significantly underperforming. AMD chose to compare their future CPU against Intel's generally available 5th gen Intel Xeon processor, which launched late last year. Figure 1 shows updated Llama2-7B performance on 5th gen Intel Xeon processor, using claims made for Turin. Since there was no substantiation of software and service-level agreements (SLA) used in these claims, we have measured performance using publicly available software (PyTorch with Intel Extension for PyTorch software) and applied a P99 latency constraint to reflect the most stringent of customer requirements.
A 5th gen Intel Xeon processor delivers real performance leadership against the competition’s next-generation CPU in the chatbot scenario. This is an astounding 5.4x better result than the AMD claims. Optimized software also helps to deliver significant improvement on the inaccurate representation of 5th gen Intel Xeon performance in summarization and translation scenarios, 2.3x and 1.2x, respectively. As LLM workloads benefit from higher memory bandwidth, we expect the Intel® Xeon® 6 processor to enable a new level of performance with an up to 2.3x memory bandwidth increase over 5th gen Intel Xeon processor, going from eight channels of DDR5 to 12 channels of DDR5 with MCR DIMM support.
Furthermore, the world of AI and deep learning goes well beyond LLMs. As we showed in December last year, both 4th and 5th gen Intel Xeon processors beat the competition's current generation of products across a range of deep learning inferencing use cases (figure 2) on a popular datatype, int8.
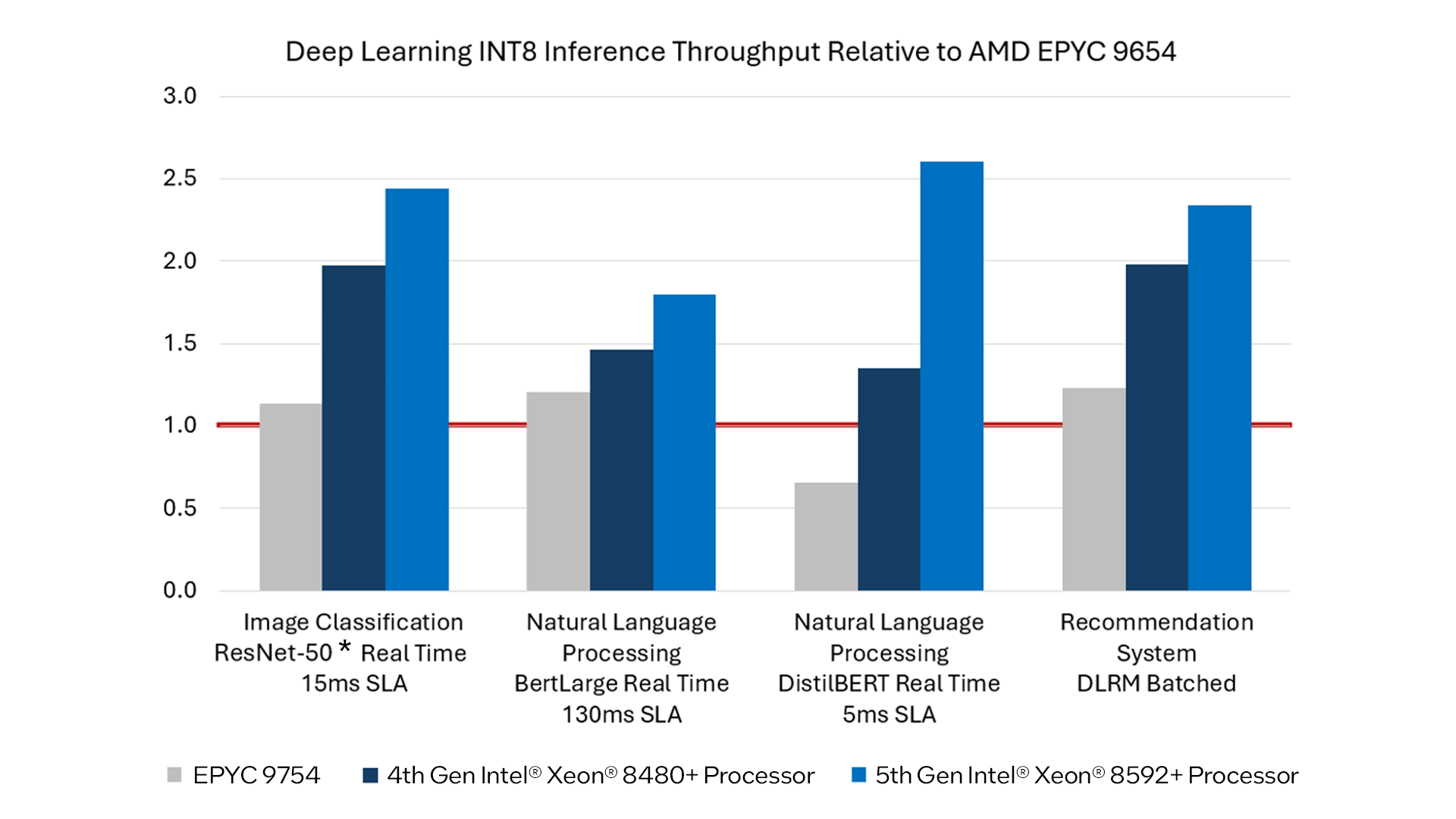
Figure 2. Intel 4th and 5th gen Intel Xeon processor deep learning performance vs AMD Genoa and Bergamo. December 2023.4
For performance substantiation, see Product and Performance Notes.
As the leading CPU for AI today—and besting AMD's next-generation offering—customers are deploying 5th gen Intel Xeon processors in their own infrastructure and through major cloud service providers like Google Cloud* and Alibaba Cloud*.
Looking ahead, we are excited about the recently announced Intel Xeon 6 processor with performance cores. Already demonstrating that the Intel Xeon 6 processor can run large models to support AI deployments and drive the next level of general-purpose computing, we can't wait to show you the continued CPU leadership position for Intel Xeon 6 processor on AI and LLM inference performance in Q3 2024.
Get Started and References
Here are the resources for getting started with AI solutions from Intel:
Product and Performance Notes
Updated on June 14, 2024.
15x latency reduction on LLM optimizations
1-node, 2x Intel® Xeon® Platinum 8480+ processor, 56 cores, Intel® Hyper-Threading Technology on, turbo on, NUMA 2, total memory 512 GB (16x64 GB DDR5 4800 MT/s [4800 MT/s]), AMI BIOS, microcode 3A06, 2x Ethernet Controller X710 for 10GBASE-T, 1x 1.8T Samsung* SSD 970 EVO Plus, CentOS* Stream9, 5.14.0-378.el9.x86_64, text generation on GPT-J 6B, GCC* 12.3, CPU for Intel Extension for PyTorch and PyTorch 2.1. BF16, BS1 CPI 56, input token size = 1016, output token size = 32. Tests by Intel as of September 27, 2023. Results may vary.
2 Figure 1. Intel 5th gen Intel Xeon processor with Llama2-7B performance versus the competition's next-generation processor: on 5th gen Intel® Xeon® Scalable processor (formerly code named Emerald Rapids) using: 2x Intel Xeon Platinum 8592+ processor, 64 cores, Intel Hyper-Threading Technology on, turbo on, 1024 GB (16x64 GB DDR5 5600 MT/s [5600 MT/s]), SNC disabled, Ubuntu* 22.04.4 LTS, kernel-6.5.0-35-generic, Llama2-7B-HF models run with PyTorch v2.3.0 and Intel Extension for PyTorch v2.3.0 (released on May 12, 2024). Model instances-2, batch size 16 (128/128), batch size 2 (2048/2048), batch size 7 (1024/128), Precision: int4—weight-only quantization algorithm—GPTQ, Tested by Intel on June 9, 2024. Scripts to reproduce the performance are on GitHub.
3 The source for AMD's claim of Turin 128C and Intel Xeon 8592+ processor: Computex 2024 Keynote Video.
4 Figure 2. Deep learning performance for 4th and 5th gen Intel Xeon processors versus AMD Genoa and Bergamo, December 2023
See A19, A20, A24, A26, A208, A209, A210, and A211 at intel.com/processorclaims: 5th Generation Intel Xeon Scalable Processors